5 Use Cases for Vector Search

May 8, 2023
Many organizations that we’ve spoken to are in the exploration phase of using vector search for AI-powered personalization, recommendations, semantic search and anomaly detection. The recent and astronomical improvements in accuracy and accessibility of large language models (LLMs) including BERT and OpenAI have made companies rethink how to build relevant search and analytics experiences.
In this blog, we capture engineering stories from 5 early adopters of vector search- Pinterest, Spotify, eBay, Airbnb and Doordash- who have integrated AI into their applications. We hope these stories will be helpful to engineering teams who are thinking through the full lifecycle of vector search all the way from generating embeddings to production deployments.
What is vector search?
Vector search is a method for efficiently finding and retrieving similar items from a large dataset based on representations of the data in a high-dimensional space. In this context, items can be anything, such as documents, images, or sounds, and are represented as vector embeddings. The similarity between items is computed using distance metrics, such as cosine similarity or Euclidean distance, which quantify the closeness of two vector embeddings.
The vector search process usually involves:
- Generating embeddings: Where relevant features are extracted from the raw data to create vector representations using models such as word2vec, BERT or Universal Sentence Encoder
- Indexing: The vector embeddings are organized into a data structure that enables efficient search using algorithms such as FAISS or HNSW
- Vector search: Where the most similar items to a given query vector are retrieved based on a chosen distance metric like cosine similarity or Euclidean distance
To better visualize vector search, we can imagine a 3D space where each axis corresponds to a feature. The time and the position of a point in the space is determined by the values of these features. In this space, similar items are located closer together and dissimilar items are farther apart.
Embedded content: https://gist.github.com/julie-mills/b3aefe62996c4b969b18e8abd658ce84
Given a query, we can then find the most similar items in the dataset. The query is represented as a vector embedding in the same space as the item embeddings, and the distance between the query embedding and each item embedding is computed. The item embeddings with the shortest distance to the query embedding are considered the most similar.
Embedded content: https://gist.github.com/julie-mills/d5833ea9c692edb6750e5e94749e36bf
This is obviously a simplified visualization as vector search operates in high-dimensional spaces.
In the next sections, we’ll summarize 5 engineering blogs on vector search and highlight key implementation considerations. The full engineering blogs can be found below:
- PinText: A Multitask Text Embedding System in Pinterest by Jinfeng Zhuang at Pinterest
- Introducing Natural Language Search for Podcast Episodes by Alexandre Tamborrino at Spotify
- How eBay’s New Search Feature Was Inspired By Window Shopping by Senthilkumar Gopal, Shubhangi Tandon, Christopher Miller, Deepika Srinivasan, Rui Kong, Selcuk Kopru and Srinivas Bhagavathula at eBay
- Listing Embeddings in Search Ranking by Mihajlo Grbovic at AirBnb
- Personalized Store Feed with Vector Embeddings by Mitchell Koch, Aamir Manasawala, Raghav Ramesh at Doordash
Pinterest: Interest search and discovery
Pinterest uses vector search for image search and discovery across multiple areas of its platform, including recommended content on the home feed, related pins and search using a multitask learning model.
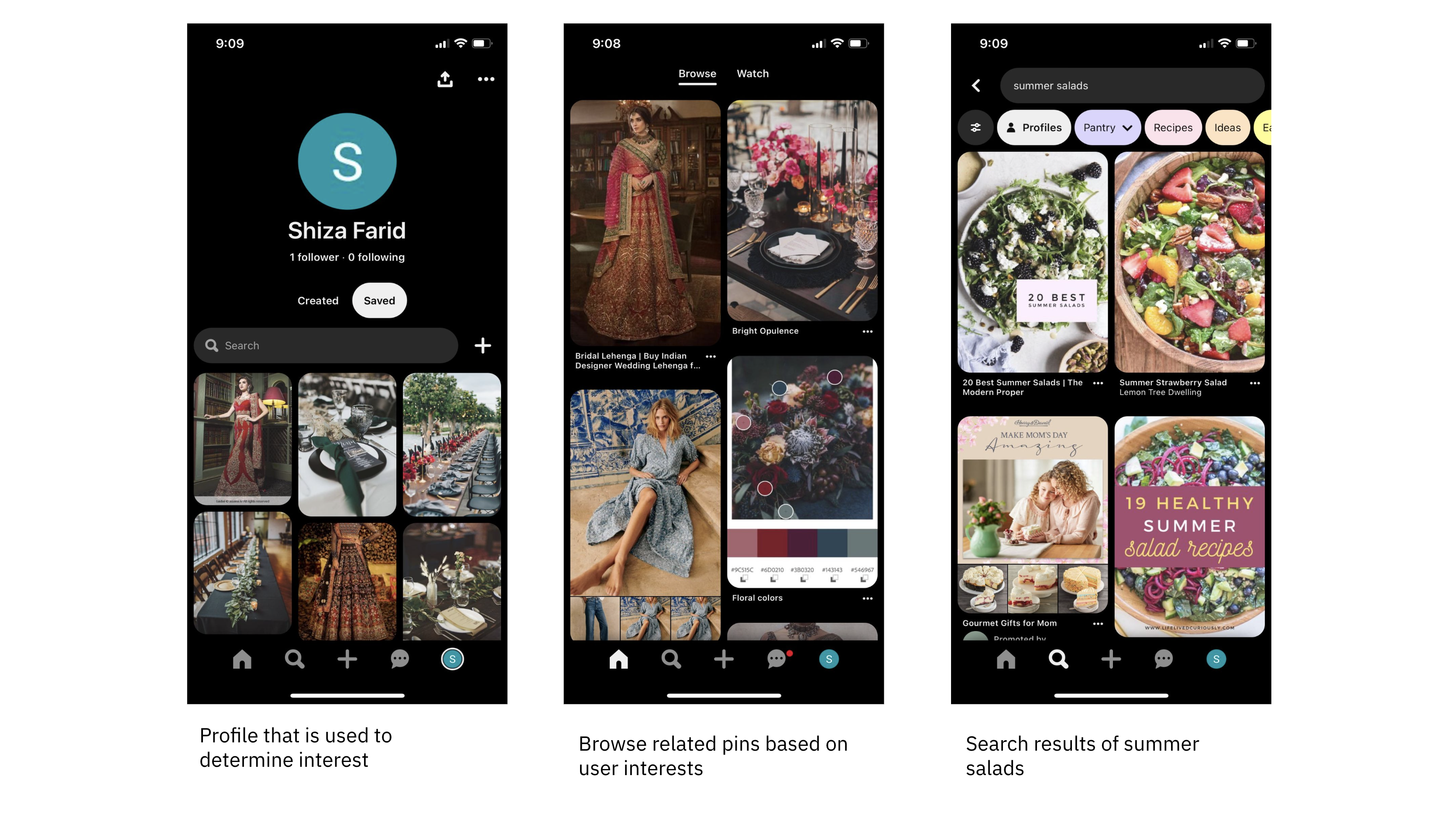
A multi-task model is trained to perform multiple tasks simultaneously, often sharing underlying representations or features, which can improve generalization and efficiency across related tasks. In the case of Pinterest, the team trained and used the same model to drive recommended content on the homefeed, related pins and search.
Pinterest trains the model by pairing a users search query (q) with the content they clicked on or pins they saved (p). Here is how Pinterest created the (q,p) pairs for each task:
- Related Pins: Word embeddings are derived from the selected subject (q) and the pin clicked on or saved by the user (p).
- Search: Word embeddings are created from the search query text (q) and the pin clicked on or saved by the user (p).
- Homefeed: Word embeddings are generated based on the interest of the user (q) and the pin clicked on or saved by the user (p).
To obtain an overall entity embedding, Pinterest averages the associated word embeddings for related pins, search and the homefeed.
Pinterest created and evaluated its own supervised Pintext-MTL (multi-task learning) against unsupervised learning models including GloVe, word2vec as well as a single-task learning model, PinText-SR on precision. PinText-MTL had higher precision than the other embedding models, meaning that it had a higher proportion of true positive predictions among all positive predictions.
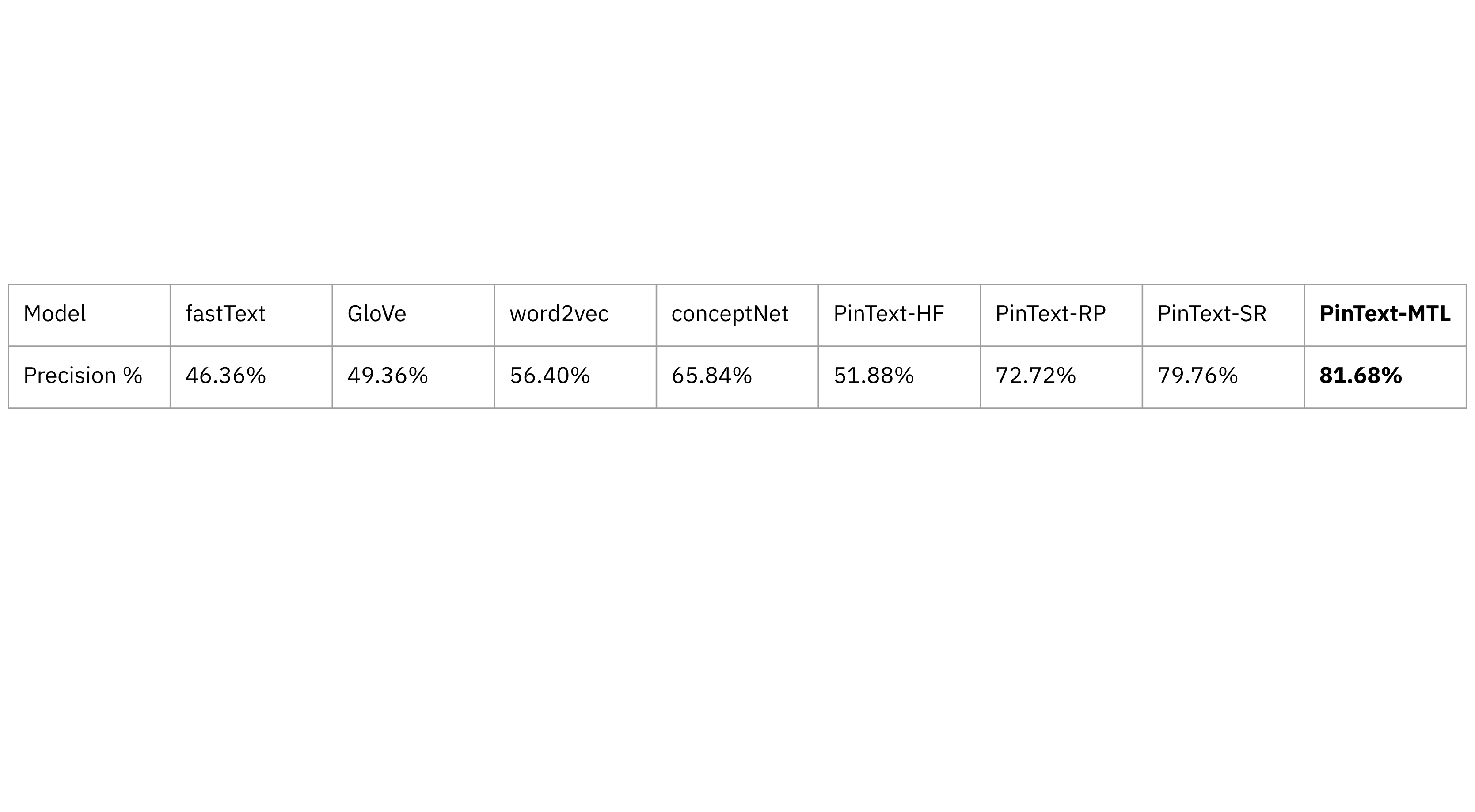
Pinterest also found that multi-task learning models had a higher recall, or a higher proportion of relevant instances correctly identified by the model, making them a better fit for search and discovery.
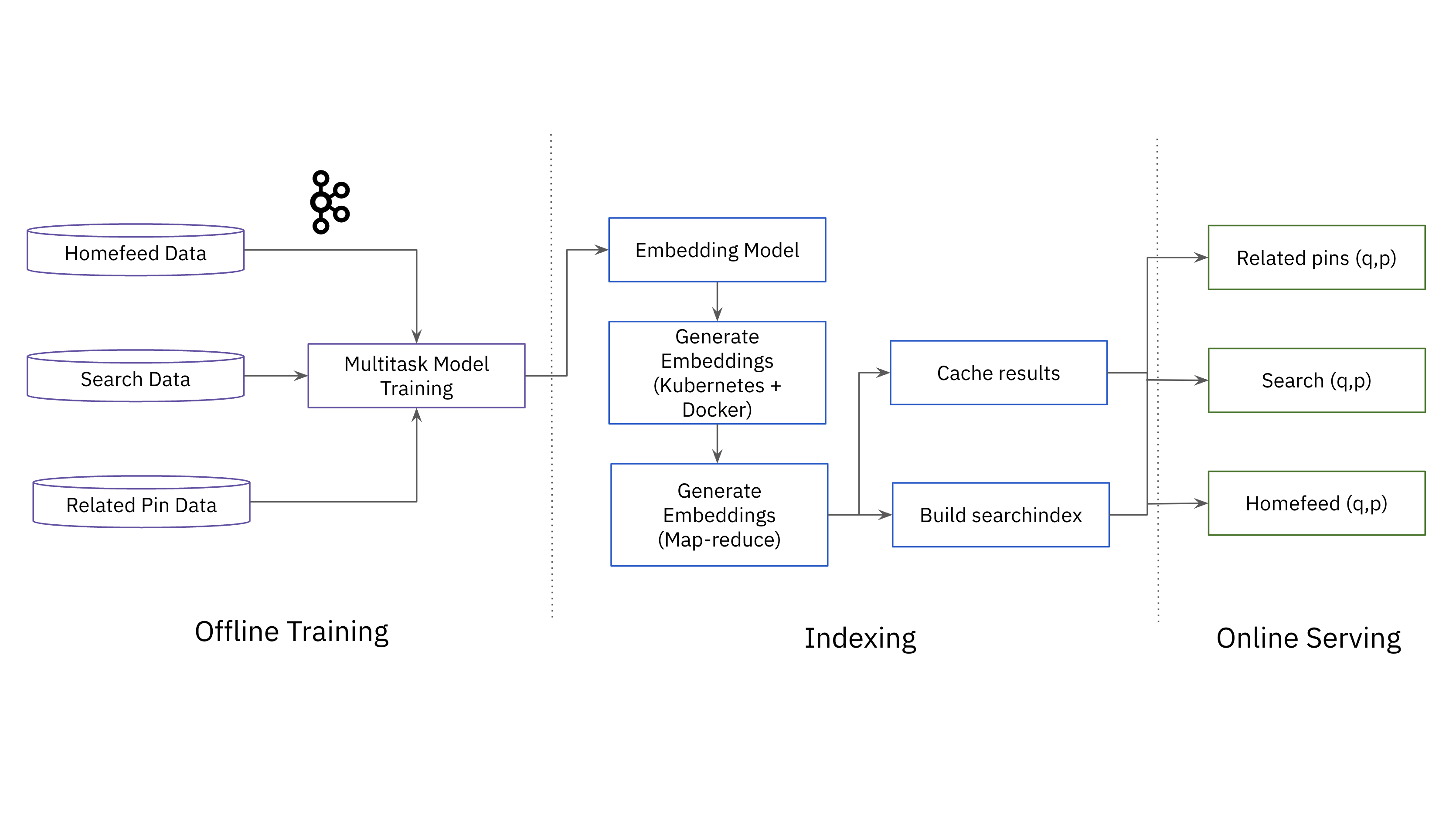
To put this all together in production, Pinterest has a multitask model trained on streaming data from the homefeed, search and related pins. Once that model is trained, vector embeddings are created in a large batch job using either Kubernetes+Docker or a map-reduce system. The platform builds a search index of vector embeddings and runs a K-nearest neighbors (KNN) search to find the most relevant content for users. Results are cached to meet the performance requirements of the Pinterest platform.
Spotify: Podcast search
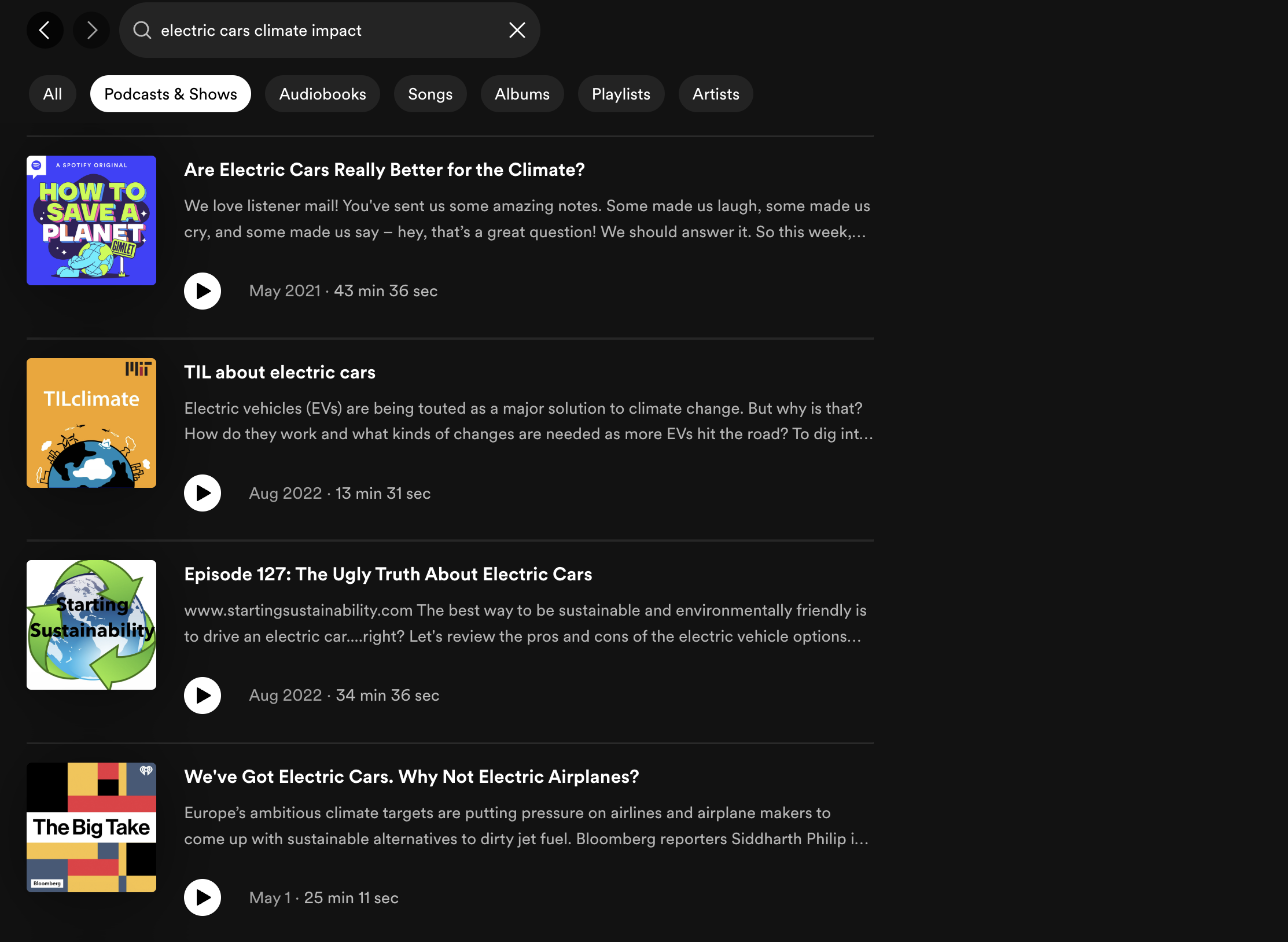
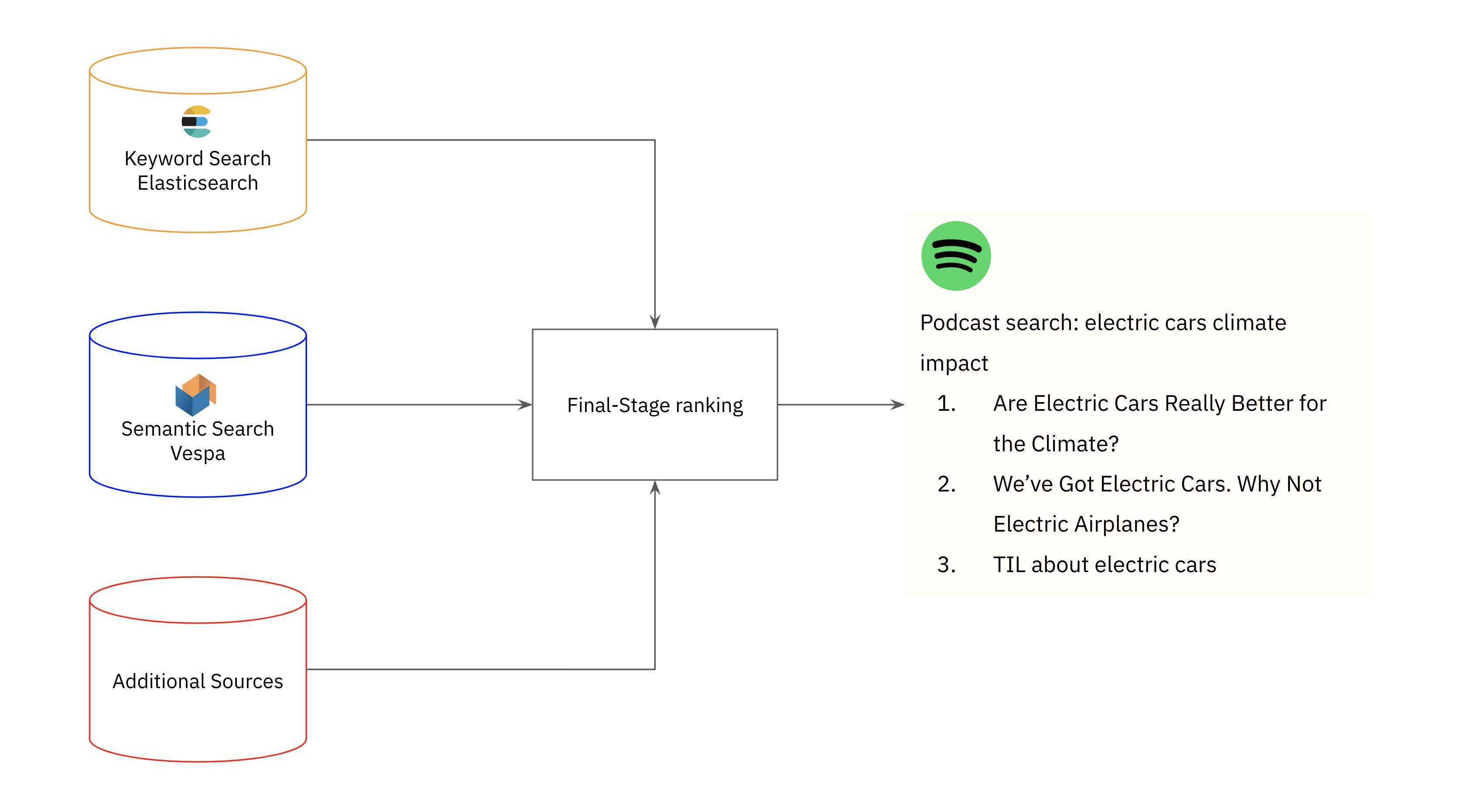
Spotify combines keyword and semantic search to retrieve relevant podcast episode results for users. As an example, the team highlighted the limitations of keyword search for the query “electric cars climate impact”, a query which yielded 0 results even though relevant podcast episodes exist in the Spotify library. To improve recall, the Spotify team used Approximate Nearest Neighbor (ANN) for fast, relevant podcast search.
The team generates vector embeddings using the Universal Sentence Encoder CMLM model as it is multilingual, supporting a global library of podcasts, and produces high-quality vector embeddings. Other models were also evaluated including BERT, a model trained on a big corpus of text data, but found that BERT was better suited for word embeddings than sentence embeddings and was pre-trained only in English.
Spotify builds the vector embeddings with the query text being the input embedding and a concatenation of textual metadata fields including title and description for the podcast episode embeddings. To determine the similarity, Spotify measured the cosine distance between the query and episode embeddings.
To train the base Universal Sentence Encoder CMLM model, Spotify used positive pairs of successful podcast searches and episodes. They incorporated in-batch negatives, a technique highlighted in papers including Dense Passage Retrieval for Open-Domain Question Answering (DPR) and Que2Search: Fast and Accurate Query and Document Understanding for Search at Facebook, to generate random negative pairings. Testing was also conducted using synthetic queries and manually written queries.
To incorporate vector search into serving podcast recommendations in production, Spotify used the following steps and technologies:
- Index episode vectors: Spotify indexes the episode vectors offline in batch using Vespa, a search engine with native support for ANN. One of the reasons that Vespa was chosen is that it can also incorporate metadata filtering post-search on features like episode popularity.
- Online inference: Spotify uses Google Cloud Vertex AI to generate a query vector. Vertex AI was chosen for its support for GPU inference, which is more cost effective when using large transformer models to generate embeddings, and for its query cache. After the query vector embedding is generated, it is used to retrieve the top 30 podcast episodes from Vespa.
Semantic search contributes to the identification of pertinent podcast episodes, yet it is unable to fully supplant keyword search. This is due to the fact that semantic search falls short of exact term matching when users search an exact episode or podcast name. Spotify employs a hybrid search approach, merging semantic search in Vespa with keyword search in Elasticsearch, followed by a conclusive re-ranking stage to establish the episodes displayed to users.
eBay: Image search
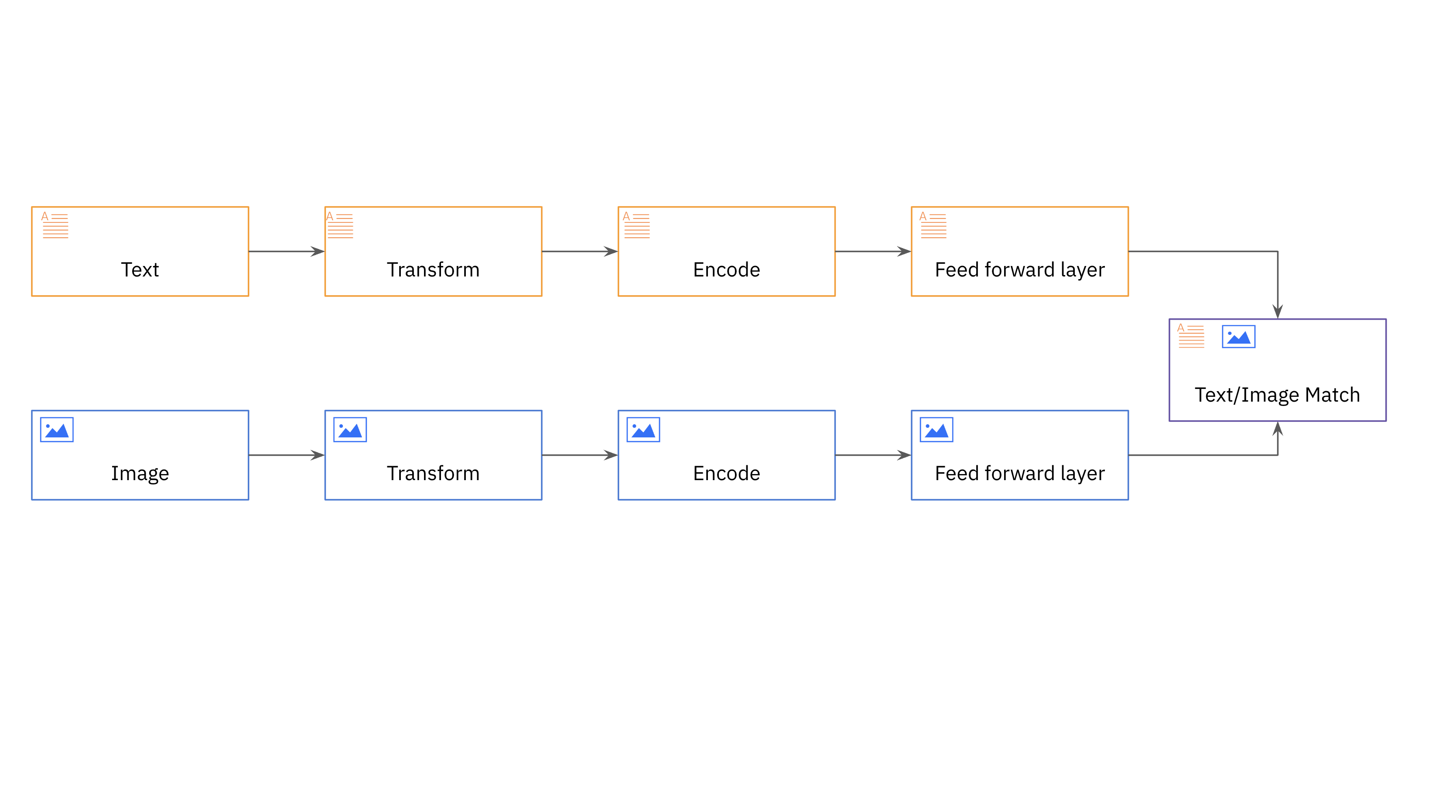
Traditionally, search engines have displayed results by aligning the search query text with textual descriptions of items or documents. This method relies extensively on language to infer preferences and is not as effective in capturing elements of style or aesthetics. eBay introduces image search to help users find relevant, similar items that meet the style they’re looking for.
eBay uses a multi-modal model which is designed to process and integrate data from multiple modalities or input types, such as text, images, audio, or video, to make predictions or perform tasks. eBay incorporates both text and images into its model, producing image embeddings utilizing a Convolutional Neural Network (CNN) model, specifically Resnet-50, and title embeddings using a text-based model such as BERT. Every listing is represented by a vector embedding that combines both the image and title embeddings.
Once the multi-modal model is trained using a large dataset of image-title listing pairs and recently sold listings, it is time to put it into production in the site search experience. Due to the large number of listings at eBay, the data is loaded in batches to HDFS, eBay’s data warehouse. eBay uses Apache Spark to retrieve and store the image and relevant fields required for further processing of listings, including generating listing embeddings. The listing embeddings are published to a columnar store such as HBase which is good at aggregating large-scale data. From HBase, the listing embedding is indexed and served in Cassini, a search engine created at eBay.
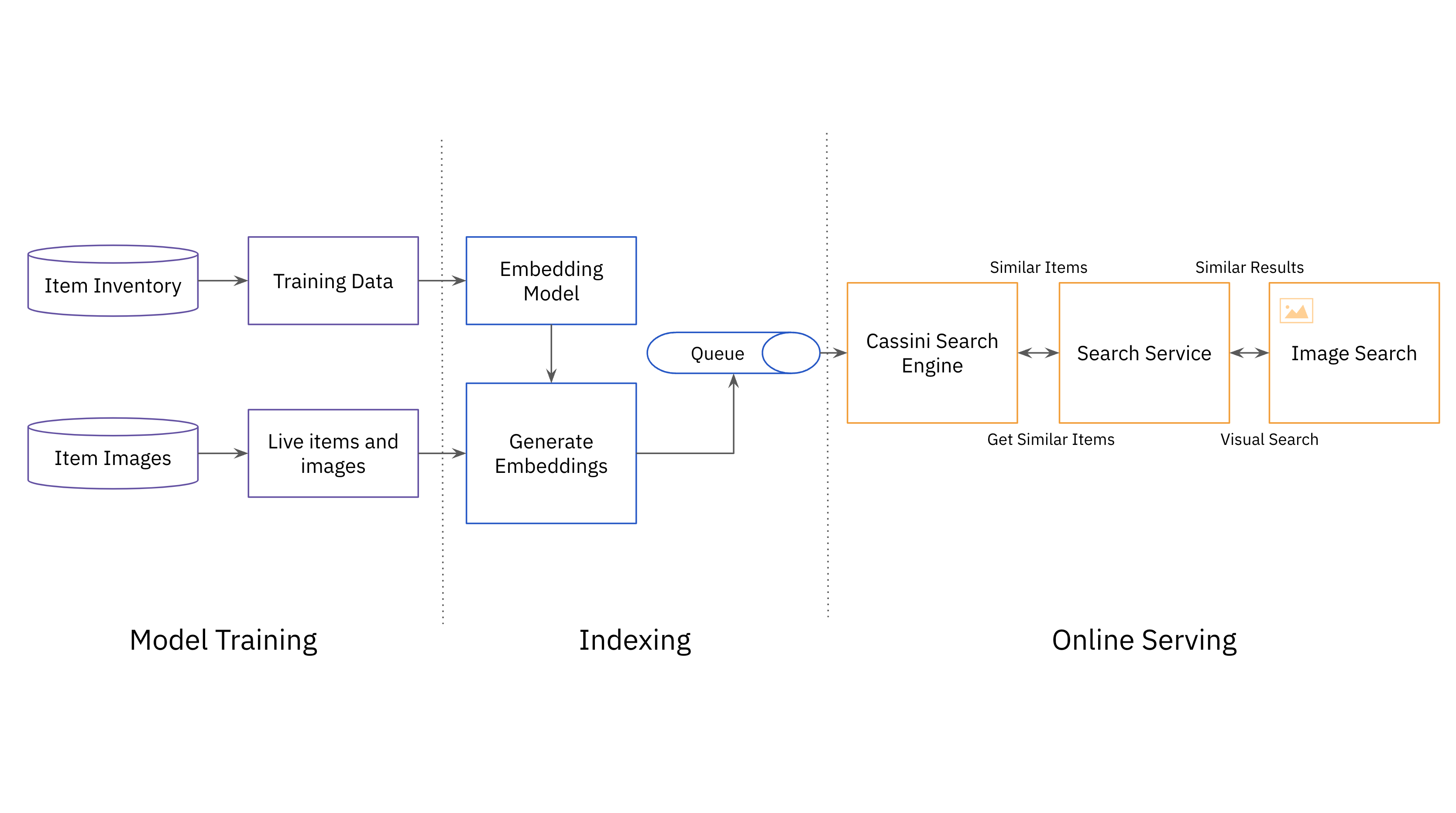
The pipeline is managed using Apache Airflow, which is capable of scaling even when there is a high quantity and complexity of tasks. It also provides support for Spark, Hadoop, and Python, making it convenient for the machine learning team to adopt and utilize.
Visual search allows users to find similar styles and preferences in the categories of furniture and home decor, where style and aesthetics are key to purchase decisions. In the future, eBay plans to expand visual search across all categories and also help users discover related items so they can establish the same look and feel across their home.
AirBnb: Real-time personalized listings
Search and similar listings features drive 99% of bookings on the AirBnb site. AirBnb built a listing embedding technique to improve similar listing recommendations and provide real-time personalization in search rankings.
AirBnb realized early on that they could expand the application of embeddings beyond just word representations, encompassing user behaviors including clicks and bookings as well.
To train the embedding models, AirBnb incorporated over 4.5M active listings and 800 million search sessions to determine the similarity based on what listings a user clicks and skips in a session. Listings that were clicked by the same user in a session are pushed closer together; listings that were skipped by the user are pushed further away. The team settled on the dimensionality of a listing embedding of d=32 given the tradeoff between offline performance and memory needed for online serving.
Embedded content: https://youtu.be/aWjsUEX7B1I
AirBnb found that certain listings characteristics do not require learning, as they can be directly obtained from metadata, such as price. However, attributes like architecture, style, and ambiance are considerably more challenging to derive from metadata.
Before moving to production, AirBnb validated their model by testing how well the model recommended listings that a user actually booked. The team also ran an A/B test comparing the existing listings algorithm against the vector embedding-based algorithm. They found that the algorithm with vector embeddings resulted in a 21% uptick in CTR and 4.9% increase in users discovering a listing that they booked.
The team also realized that vector embeddings could be used as part of the model for real-time personalization in search. For each user, they collected and maintained in real time, using Kafka, a short-term history of user clicks and skips in the last two weeks. For every search conducted by the user, they ran two similarity searches:
- based on the geographic markets that were recently searched and then
- the similarity between the candidate listings and the ones the user has clicked/skipped
Embeddings were evaluated in offline and online experiments and became part of the real-time personalization features.
Doordash: Personalized store feeds
Doordash has a wide variety of stores that users can choose to order from and being able to surface the most relevant stores using personalized preferences improves search and discovery.
Doordash wanted to apply latent information to its store feed algorithms using vector embeddings. This would enable Doordash to uncover similarities between stores that were not well-documented including if a store has sweet items, is considered trendy or features vegetarian options.
Doordash used a derivative of word2vec, an embedding model used in natural language processing, called store2vec that it adapted based on existing data. The team treated each store as a word and formed sentences using the list of stores viewed during a single user session, with a maximum limit of 5 stores per sentence. To create user vector embeddings, Doordash summed the vectors of the stores from which users placed orders in the past 6 months or up to 100 orders.
As an example, Doordash used vector search to find similar restaurants for a user based on their recent purchases at popular, trendy joints 4505 Burgers and New Nagano Sushi in San Francisco. Doordash generated a list of similar restaurants measuring the cosine distance from the user embedding to store embeddings in the area. You can see that the stores that were closest in cosine distance include Kezar Pub and Wooden Charcoal Korean Village BBQ.

Doordash incorporated store2vec distance feature as one of the features in its larger recommendation and personalization model. With vector search, Doordash was able to see a 5% increase in click-through-rate. The team is also experimenting with new models like seq2seq, model optimizations and incorporating real-time onsite activity data from users.
Key considerations for vector search
Pinterest, Spotify, eBay, Airbnb and Doordash create better search and discovery experiences with vector search. Many of these teams started out using text search and found limitations with fuzzy search or searches of specific styles or aesthetics. In these scenarios, adding vector search to the experience made it easier to find relevant, and often personalized, podcasts, pillows, rentals, pins and eateries.
There are a few decisions that these companies made that are worth calling out when implementing vector search:
- Embedding models: Many started out using an off-the-shelf model and then trained it on their own data. They also recognized that language models like word2vec could be used by swapping words and their descriptions with items and similar items that were recently clicked. Teams like AirBnb found that using derivatives of language models, rather than image models, could still work well for capturing visual similarities and differences.
- Training: Many of these companies opted to train their models on past purchase and click through data, making use of existing large-scale datasets.
- Indexing: While many companies adopted ANN search, we saw that Pinterest was able to combine metadata filtering with KNN search for efficiency at scale.
- Hybrid search: Vector search rarely replaces text search. Many times, like in Spotify’s example, a final ranking algorithm is used to determine whether vector search or text search generated the most relevant result.
- Productionizing: We’re seeing many teams use batch-based systems to create the vector embeddings, given that these embeddings are rarely updated. They employ a different system, frequently Elasticsearch, to compute the query vector embedding live and incorporate real-time metadata in their search.
Rockset, a real-time search and analytics database, recently added support for vector search. Give vector search on Rockset a try for real-time personalization, recommendations, anomaly detection and more by starting a free trial with $300 in credits today.