A Breakthrough Architecture for Real-Time Analytics- An Overview of Compute-Compute Separation in Rockset

March 1, 2023
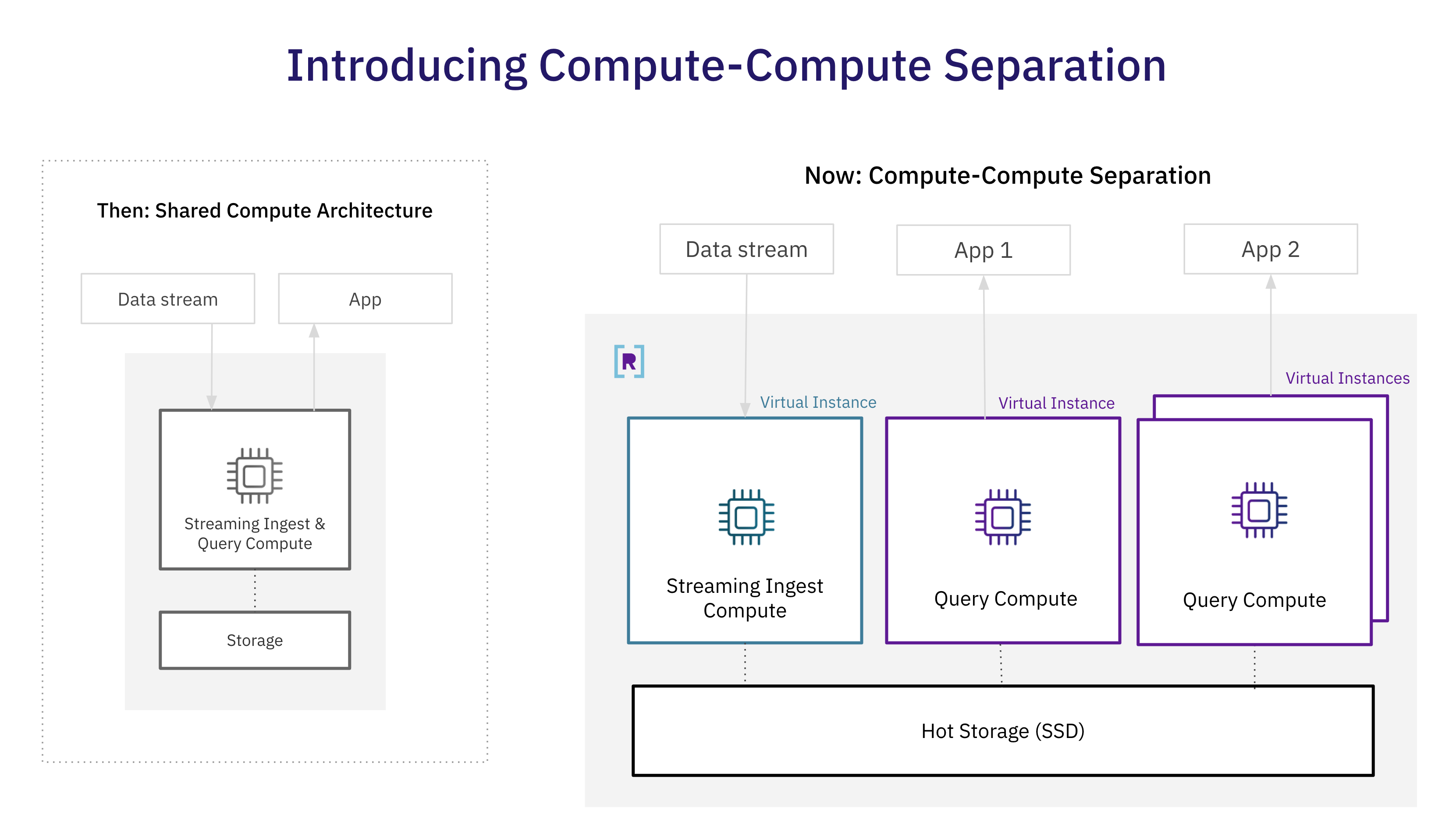
Rockset introduces a new architecture that enables separate virtual instances to isolate streaming ingestion from queries and one application from another. Compute-compute separation in the cloud offers new efficiencies for real-time analytics at scale with shared real-time data, zero compute contention, fast scale up or down, and unlimited concurrency scaling.
The Problem of Compute Contention
Real-time analytics, including personalization engines, logistics tracking applications and anomaly detection applications, are challenging to scale efficiently. Data applications constantly compete for the same pool of compute resources to support high-volume streaming writes, low latency queries, and high concurrency workloads. As a result, compute contention ensues, causing several problems for customers and prospects:
- User-facing analytics in my SaaS application can only update every 30 minutes since the underlying database becomes unstable whenever I try to process streaming data continuously.
- When my e-commerce site runs promotions, the massive amount of writes impacts the performance of my personalization engine because my database cannot isolate writes from reads.
- We started running a single logistics tracking application on the database cluster. However, when we added a real-time ETA and automated routing application, the additional workloads degraded the cluster performance. As a workaround, I have added replicas for isolation, but the additional compute and storage cost is expensive.
- The usage of my gaming application has skyrocketed in the last year. Unfortunately, as the number of users and concurrent queries on my application increases, I have been forced to double the size of my cluster as there is no way to add more resources incrementally.
With all the above scenarios, organizations must either overprovision resources, create replicas for isolation or revert to batching.
Benefits of Compute-Compute Separation
In this new architecture, virtual instances contain the compute and memory needed for streaming ingest and queries. Developers can spin up or down virtual instances based on the performance requirements of their streaming ingest or query workloads. In addition, Rockset provides fast data access through the use of more performant hot storage, while cloud storage is used for durability. Rockset’s ability to exploit the cloud makes complete isolation of compute resources possible.
Compute-compute separation offers the following advantages:
- Isolation of streaming ingestion and queries
- Multiple applications on shared real-time data
- Unlimited concurrency scaling
Isolation of Streaming Ingestion and Queries
In first-generation database architectures, including Elasticsearch and Druid, clusters contain the compute and memory for both streaming ingestion and queries, causing compute contention. Elasticsearch attempted to address compute contention by creating dedicated ingest nodes to transform and enrich the document, but this happens before indexing, which still occurs on data nodes alongside queries. Indexing and compaction are compute-intensive, and putting those workloads on every data node negatively impacts query performance.
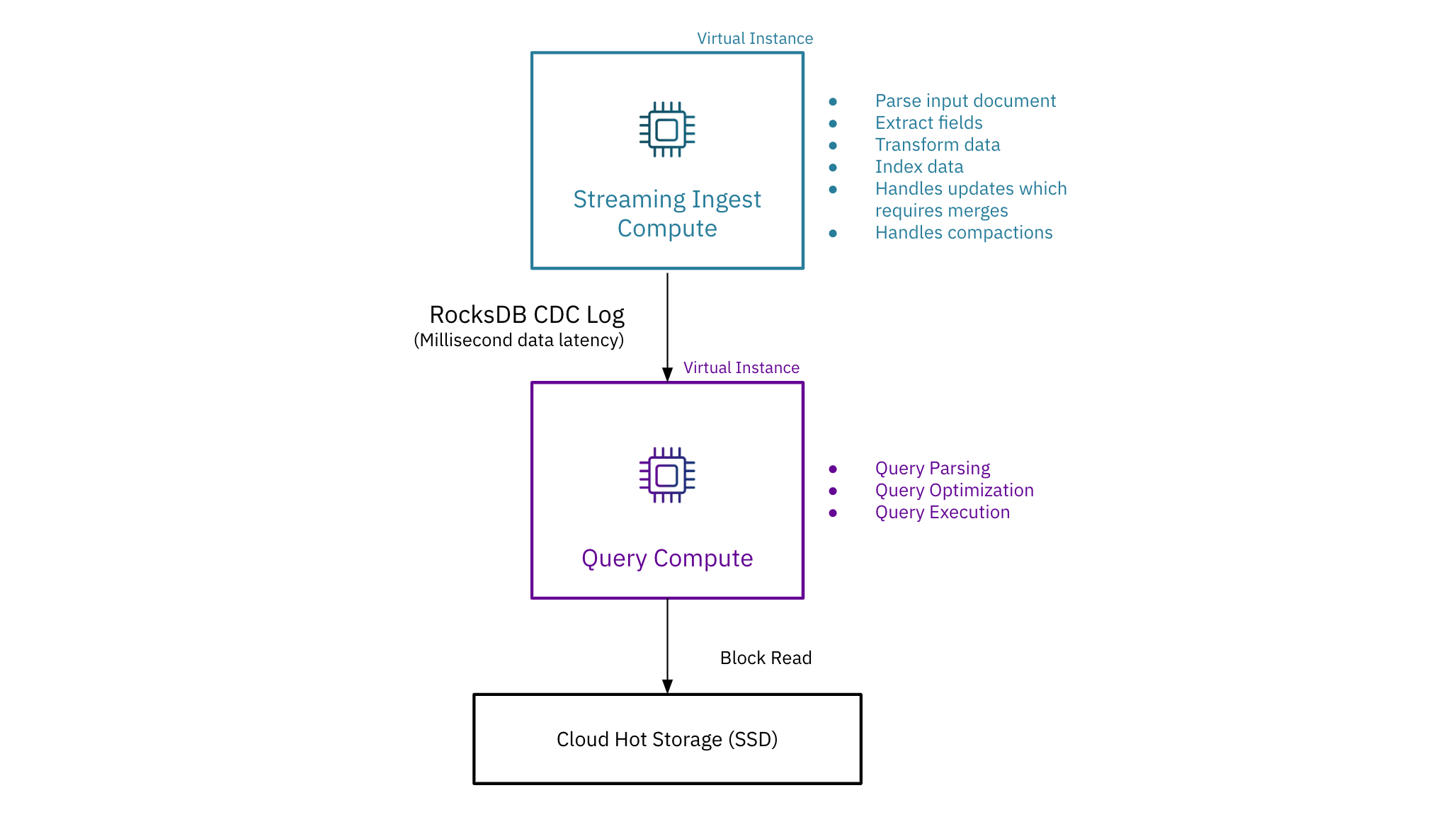
In contrast, Rockset enables multiple virtual instances for compute isolation. Rockset places compute-intensive ingest operations, including indexing and handling updates, on the streaming ingest virtual instance and then uses a RocksDB CDC log to send the updates, inserts, and deletes to query virtual instances. As a result, Rockset is now the only real-time analytics database to isolate streaming ingest from query compute without needing to create replicas.
Multiple Applications on Shared Real-Time Data
Until this point, the separation of storage and compute relied on cloud object storage which is economical but cannot meet the speed demands of real-time analytics. Now, users can run multiple applications on data that is seconds old, where each application is isolated and sized based on its performance requirements. Creating separate virtual instances, each sized for the application needs, eliminates compute contention and the need to overprovision compute resources to meet performance. Furthermore, shared real-time data reduces the cost of hot storage significantly, as only one copy of the data is required.
Unlimited Concurrency
Customers can size the virtual instance for the desired query performance and then scale out compute for higher concurrency workloads. In other systems that use replicas for concurrency scaling, each replica needs to individually process the incoming data from the stream which is compute-intensive. This also adds load on the data source as it needs to support multiple replicas. Rockset processes the streaming data once and then scales out, leaving compute resources for query execution.
How Compute-Compute Separation Works
Let’s walk through how compute-compute separation works using streaming data from the Twitter firehose to serve multiple applications:
- an application featuring the most tweeted stock ticker symbols
- an application featuring the most tweeted hashtags
Here’s what the architecture will look like:
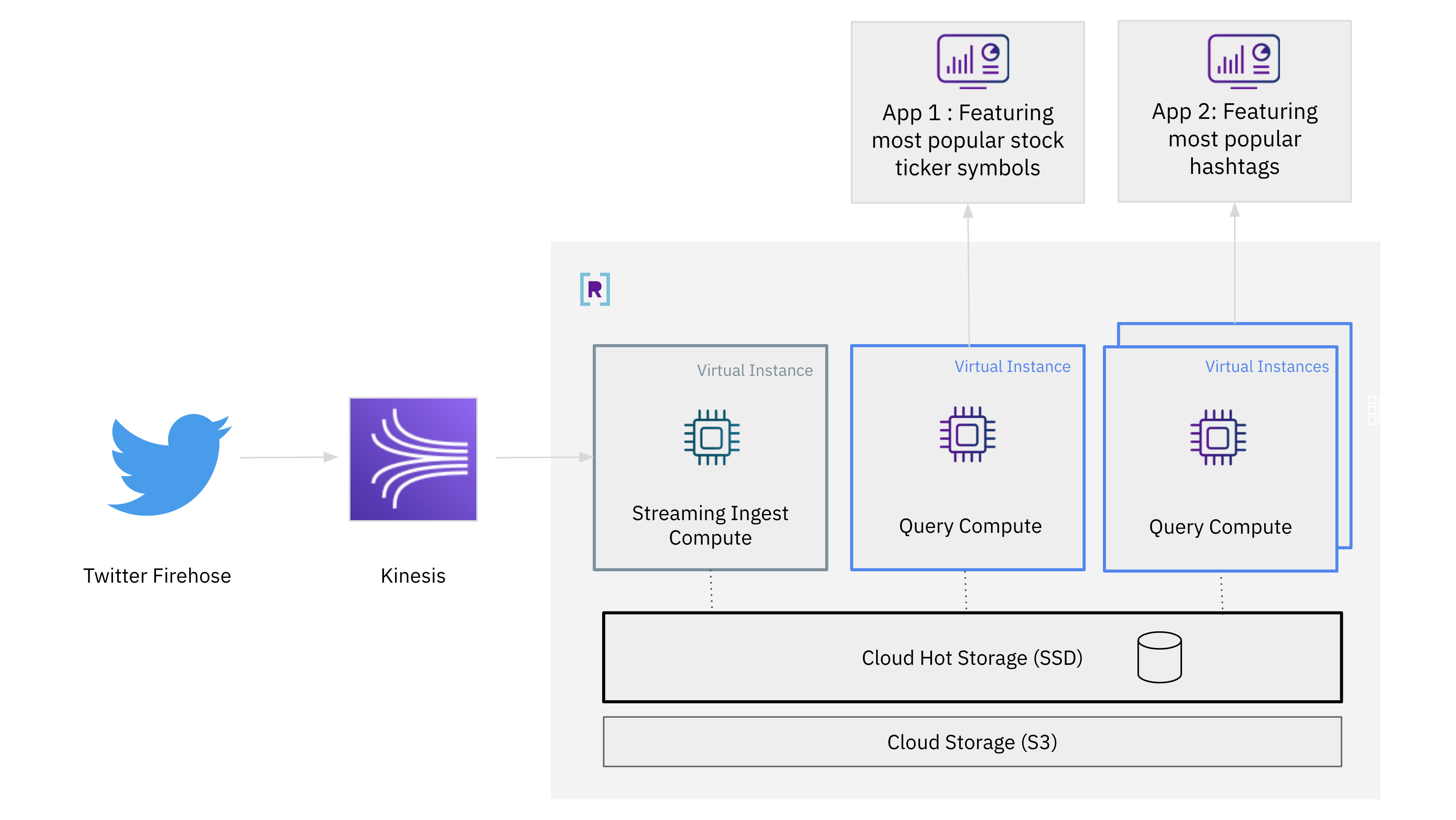
- We’ll stream data from the Twitter Firehose into Rockset using the event streaming platform Amazon Kinesis
- We’ll then create a collection from the Twitter data. The default virtual instance will be dedicated to streaming ingestion in this example.
- We’ll then create an additional virtual instance for query processing. This virtual instance will find the most tweeted stock ticker symbols on Twitter.
- Repeating the same process, we can create another virtual instance for query processing. This virtual instance will find the most popular hashtags on Twitter.
- We’ll scale out to multiple virtual instances to handle high-concurrency workloads.
Step 1: Create a Collection that Syncs Twitter Data from the Kinesis Stream
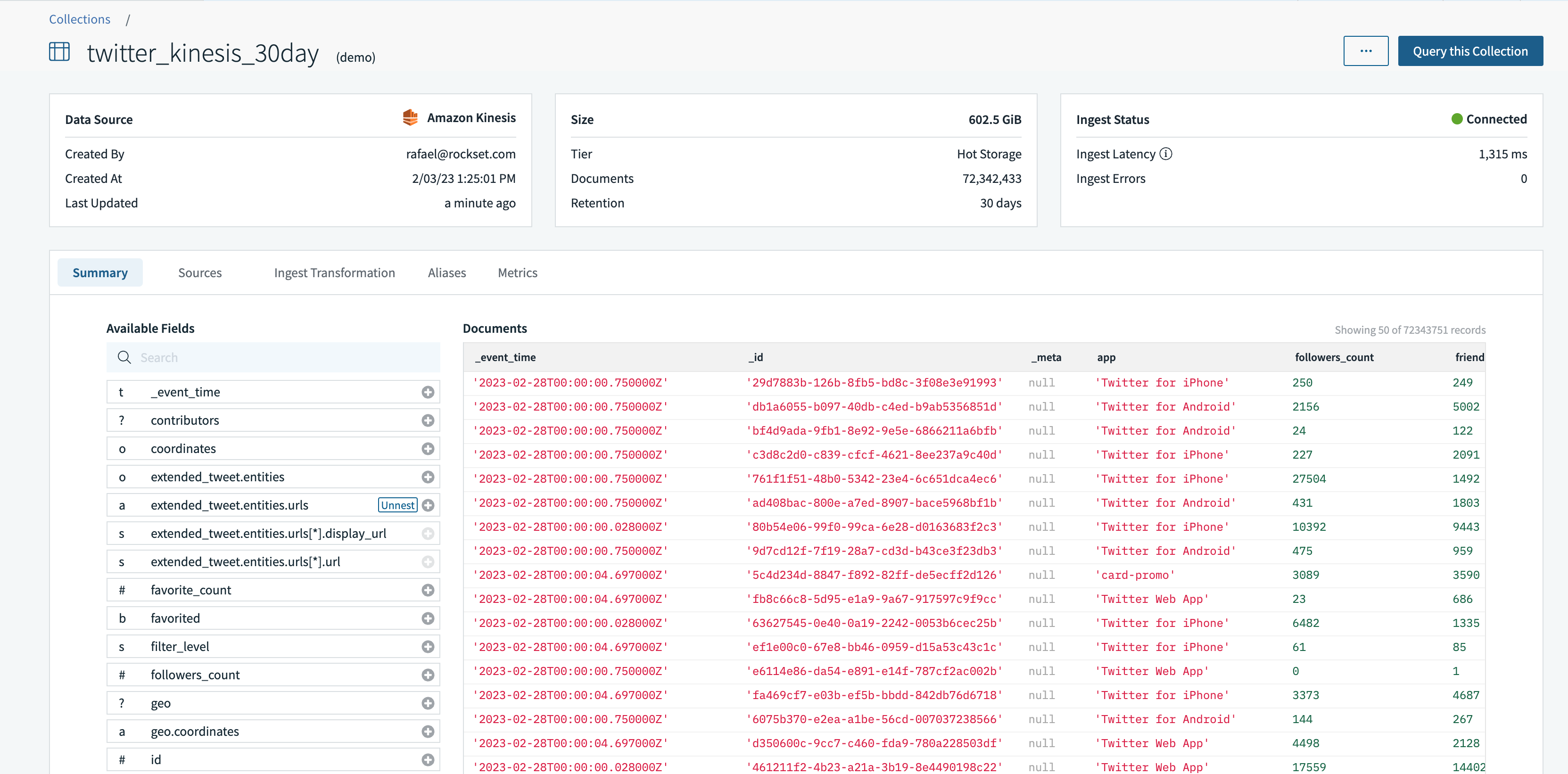
In preparation for the walk-through of compute-compute separation, I set up an integration to Amazon Kinesis using AWS Cross-Account IAM roles and AWS Access Keys. Then, I used the integration to create a collection, twitter_kinesis_30day, that syncs Twitter data from the Kinesis stream.
At collection creation time, I can also create ingest transformations including using SQL rollups to continuously aggregate data. In this example, I used ingest transformations to cast a date as a timestamp, parse a field and extract nested fields.
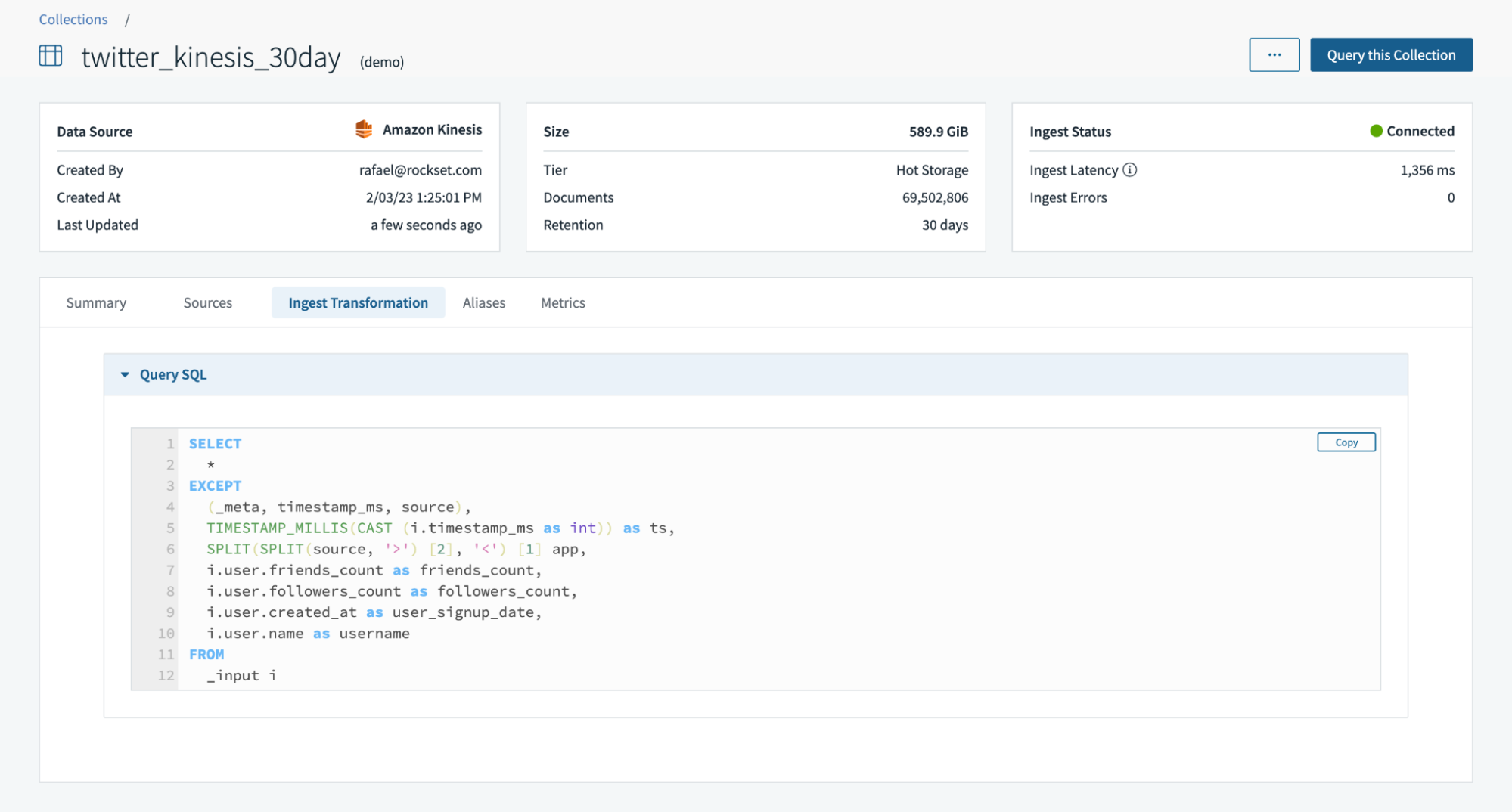
The default virtual instance is responsible for streaming data ingestion and ingest transformations.
Step 2: Create Multiple Virtual Instances
Heading to the virtual instances tab, I can now create and manage multiple virtual instances, including:
- changing the number of resources in a virtual instance
- mounting or associating a virtual instance with a collection
- setting the suspension policy of a virtual instance to save on compute resources
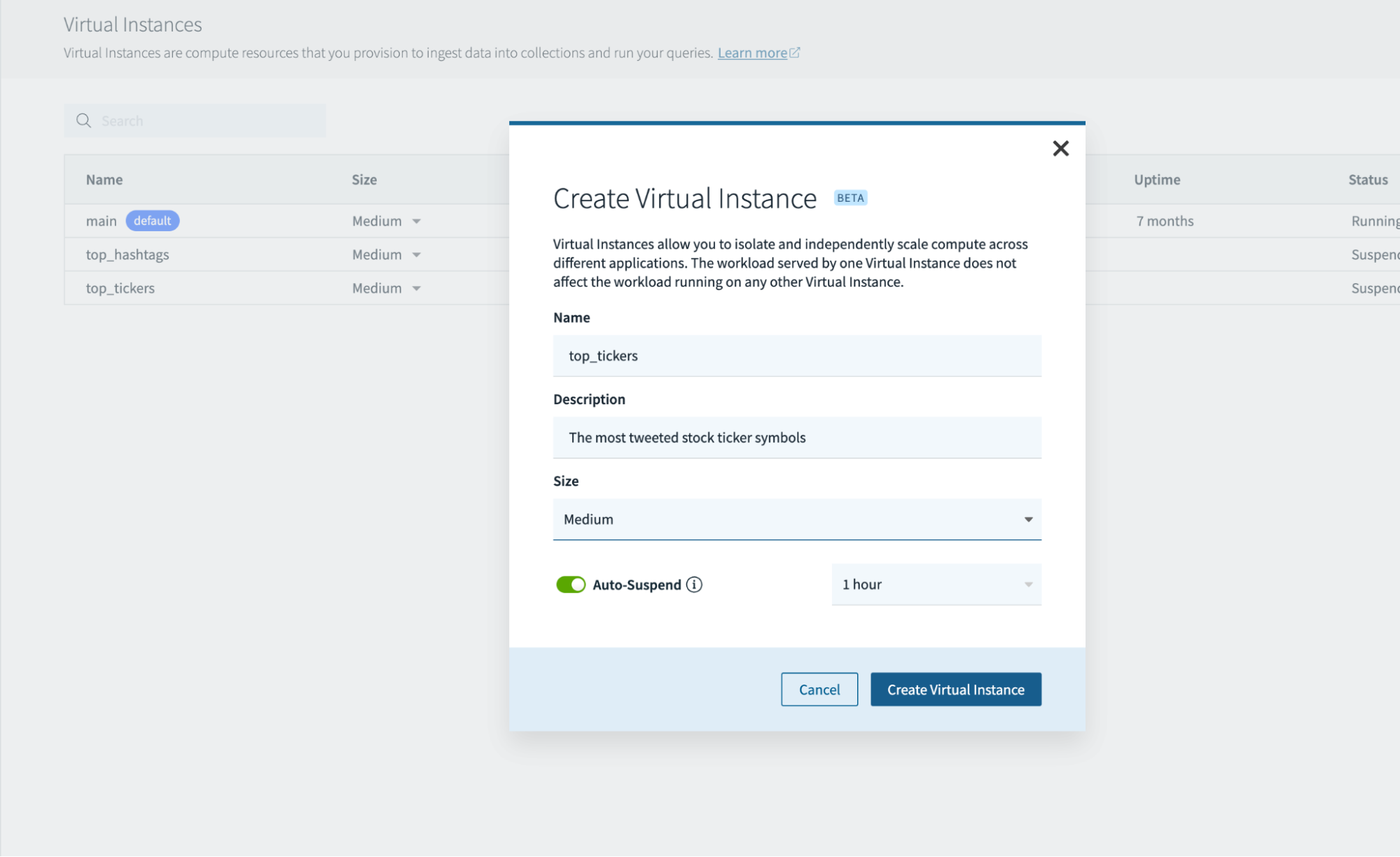
In this scenario, I want to isolate streaming ingest compute and query compute. We’ll create secondary virtual instances to serve queries featuring:
- the most tweeted stock ticker symbols
- the most tweeted hashtags
The virtual instance is sized based on the latency requirements of the application. It can also be auto-suspended due to inactivity.
Step 3: Mount Collections to Virtual Instances
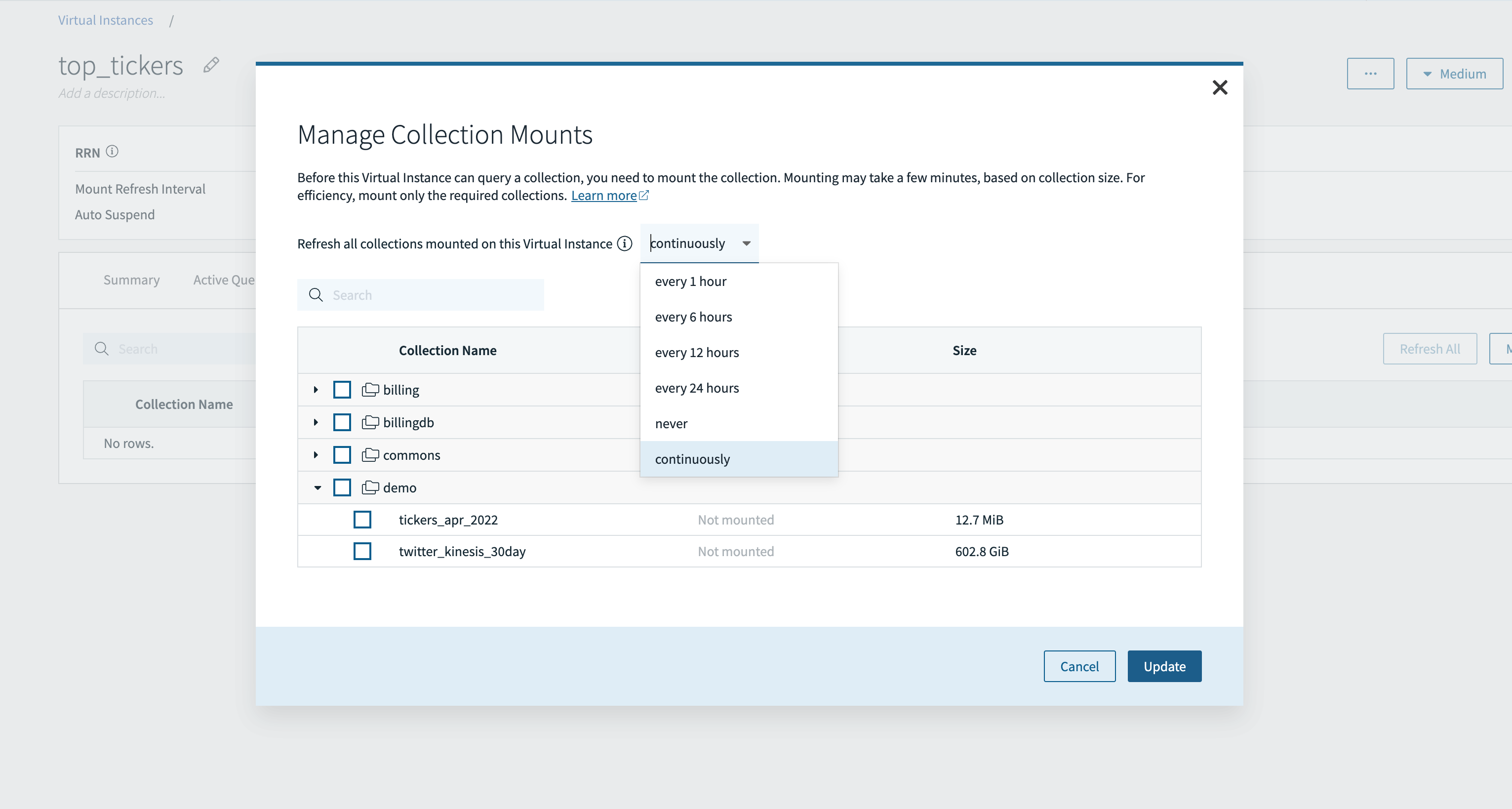
Before I can query a collection, I first need to mount the collection to the virtual instance.
In this example, I’ll mount the Twitter kinesis collection to the top_tickers virtual instance, so I can run queries to find the most tweeted about stock ticker symbols. In addition, I can choose a periodic or continuous refresh depending on the data latency requirements of my application. The option for continuous refresh is currently available in early access.
Step 4: Run Queries Against the Virtual Instance
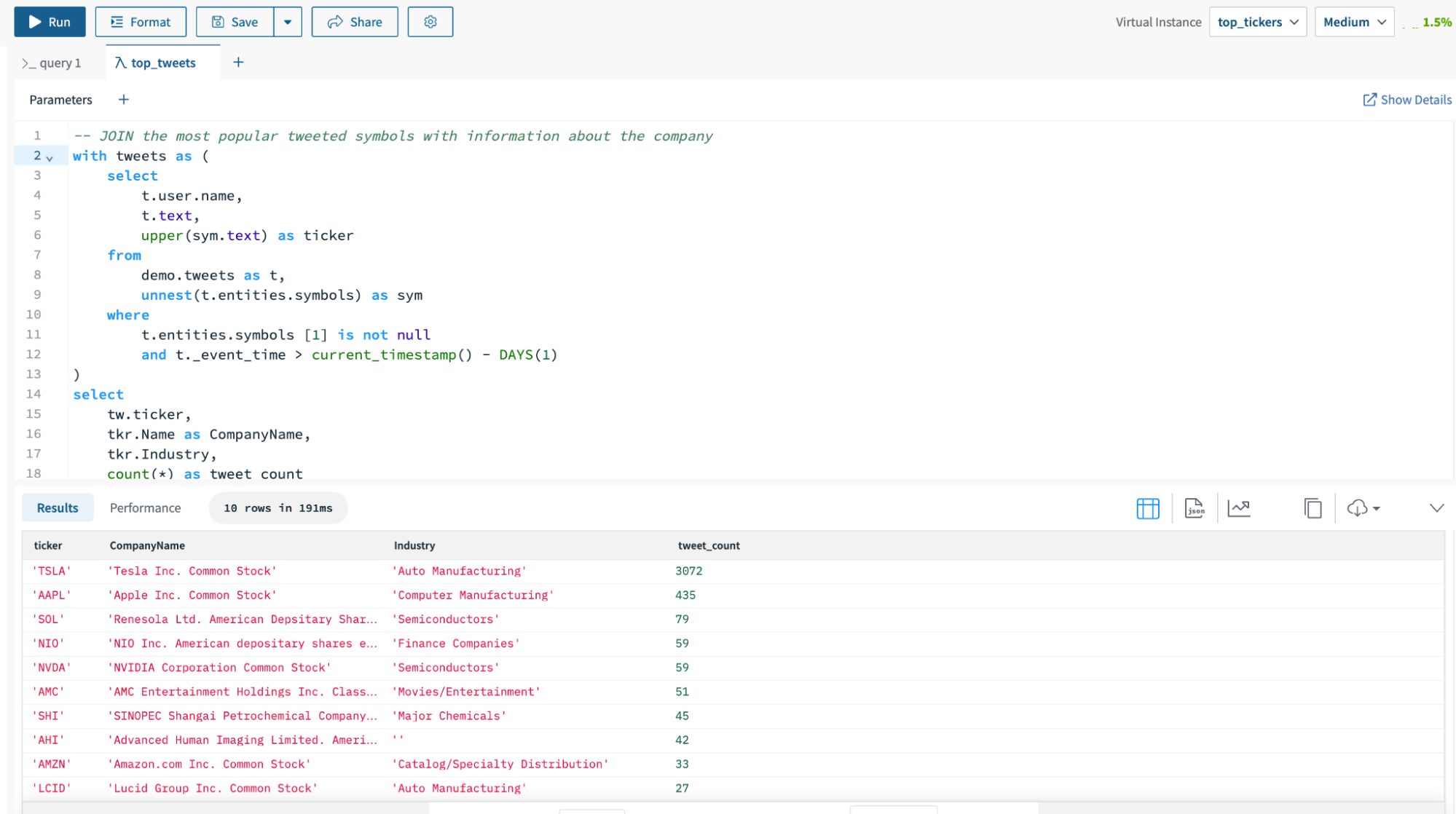
I’ll go to the query editor to run the SQL query against the top_tickers virtual instance.
I created a SQL query to find the stock ticker symbols with the most mentions on Twitter in the last 24 hours. In the upper right hand corner of the query editor, I selected the virtual instance top_tickers to serve the query. You can see that the query executed in 191 ms.
Step 5: Scale Out to Support High Concurrency Workloads
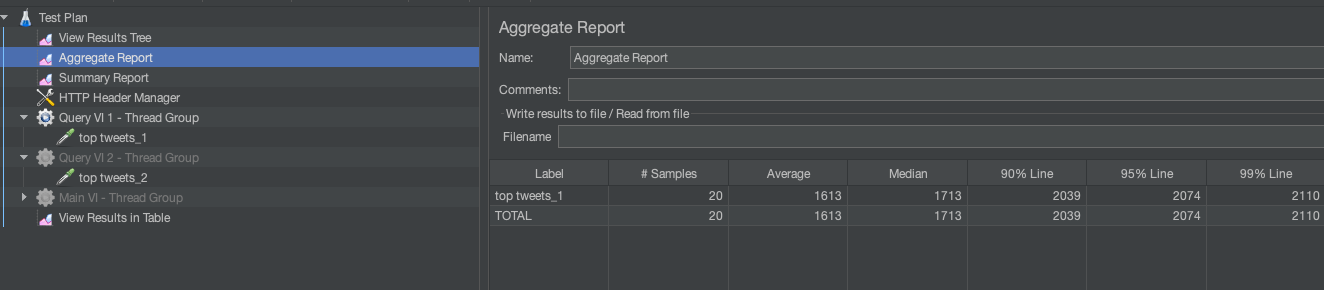
Let’s now scale out to support high concurrency workloads. In JMeter, I simulated 20 queries per second and recorded an average latency of 1613 ms for the queries.
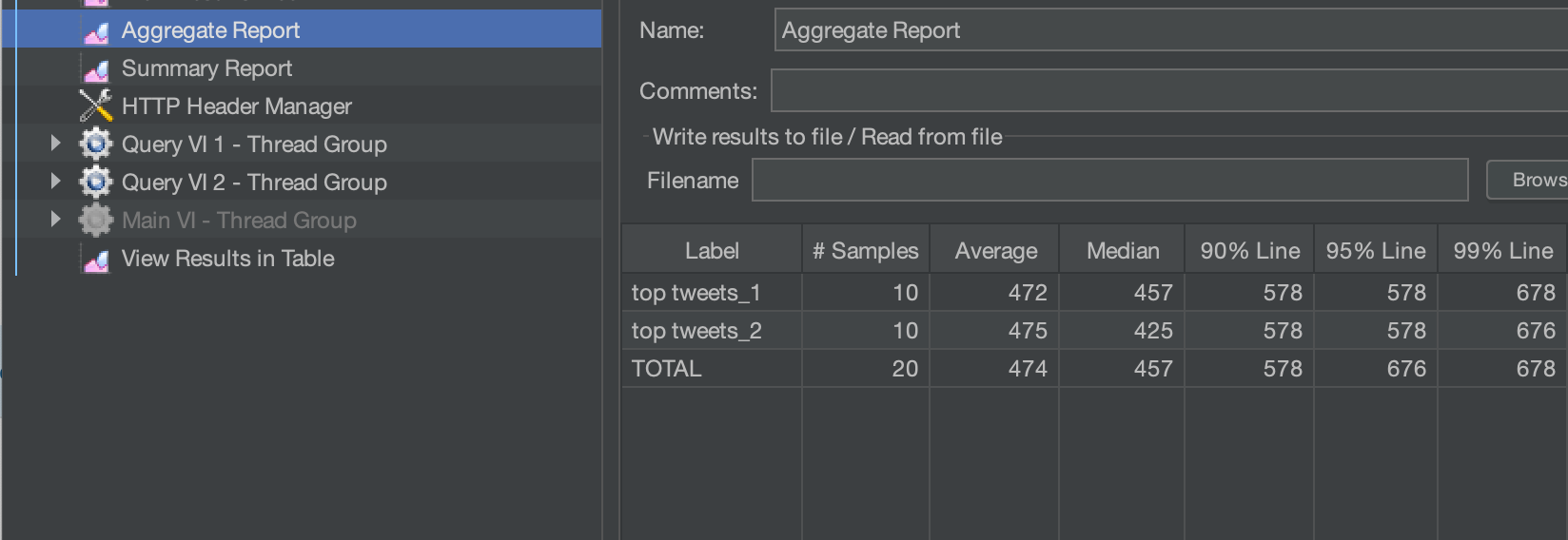
If my SLA for my application is under 1 second, I will want to scale out compute. I can scale out instantly and you can see that adding another medium Virtual Instance took the latency down for 20 queries to an average of 457 ms.
Explore Compute-Compute Separation
We have explored how to create multiple virtual instances for streaming ingest, low-latency queries, and multiple applications. With the release of compute-compute separation in the cloud, we are excited to make real-time analytics more efficient and accessible. Try out the public beta of compute-compute separation today by starting a free trial of Rockset.