Case Study: Powering Customer-Facing Dashboards at Scale Using Rockset with PostgreSQL at DataBrain

November 5, 2021
Summary:
- DataBrain, a SaaS company, was using PostgreSQL through Amazon RDS to land and query incoming customer data.
- However, PostgreSQL couldn’t scale, quickly ingest schemaless data, or efficiently run analytics as DataBrain’s data grew.
- Plus, incoming customer data had a dynamic schema, making it painful and expensive for DataBrain to clean the data for PostgreSQL and run queries.
- Rockset solved these data problems, delaying the need to hire a data engineer and saving DataBrain storage costs by offloading some data to Amazon S3.
The Operating System for GTM Teams
Organizations understand that their ability to make their customers happy and successful is directly correlated to the quality of insights they can draw about each customer. And these insights must not only be relevant, but actionable in real time. Knowing a customer is confused today instead of tomorrow can be the difference between keeping the customer happy and keeping the customer, period. This problem is especially acute for teams whose job is to proactively engage with customers. This is where DataBrain steps in.
DataBrain provides go-to-market teams with data-driven insights about the health of their accounts by leveraging real-time customer data. By connecting to a wide range of existing SaaS tools and then analyzing the data, DataBrain’s dashboard surfaces recommendations for account teams, as well as allows them to drill down into data to discover valuable insights.

Perhaps the account hasn’t been adopting new features, or it has had significant touch points with support recently. That highlights a potential churn risk. Or perhaps the account has taken advantage of new capabilities, highlighting an upsell opportunity. DataBrain analyzes a wide range of data points across the customer’s system and recommends potential actions.
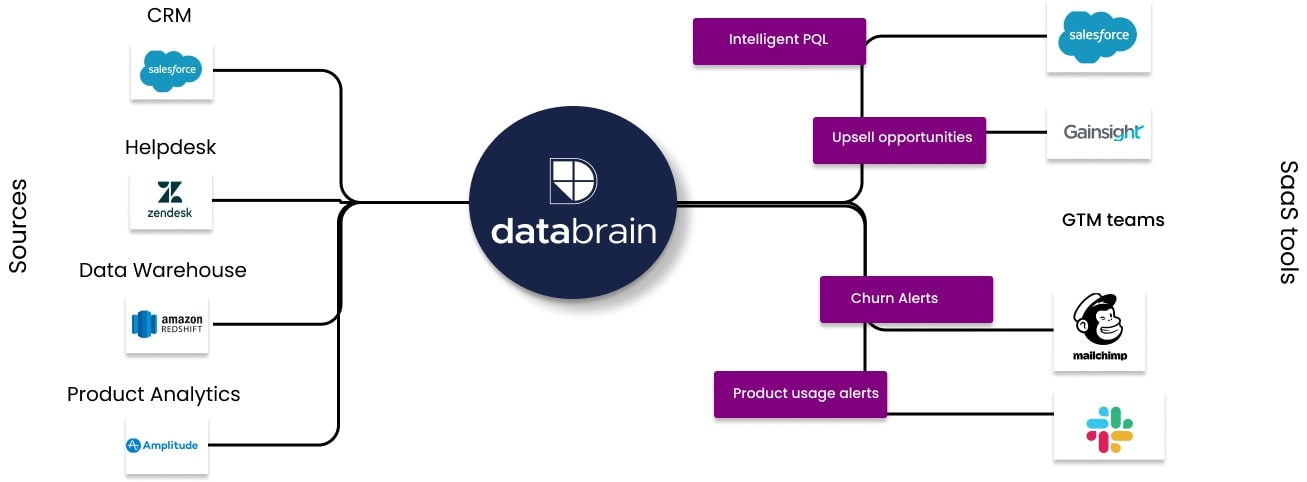
With DataBrain, GTM teams such as customer success, sales operations and even product know how to focus their time and craft their communication based on real-time account data. CEO and founder Rahul Pattamatta describes DataBrain as “the operating system for GTM teams.”
But as a quick, fast-growing company in a competitive space, DataBrain was running into several challenges with its data stack.
Challenge 1: Scaling PostgreSQL for Analytics
DataBrain was using PostgreSQL through Amazon RDS to land and query both incoming customer data as well as internal company data. This made sense when DataBrain didn’t have large amounts of data or complex queries to run. PostgreSQL in the cloud was also straightforward to set up and well-established as a technology.
However, DataBrain’s customer base and usage was growing fast. One customer was already generating 60 million rows of data. That was when DataBrain started to run into the natural limitations of PostgreSQL: high query latency for any type of analytical query. PostgreSQL is just not optimized for analytics. This was especially apparent at scale.
“Writing SQL against an RDS instance was just impossible,” Pattamatta said. “Our queries were taking too long and our app started to time out. This was unacceptable to our customers.”
DataBrain initially experimented with the more analytics-optimized Amazon Redshift, but found it too slow for its use case, with queries taking close to 10 seconds.
Challenge 2: Managing Constantly-Changing Schema on Customer Data
Another problem DataBrain faced was successfully ingesting the semi-structured customer data into PostgreSQL.
“We have to manage a dynamic schema and people defining a bunch of different metrics in their JSON,” Pattamatta said. “It was really hard for us to understand what they were sending us.”
Every time new columns were added to JSON, the engineers at DataBrain went through great effort to scan and identify the changes in the schema before updating the data. This wasn’t sustainable. DataBrain needed a more-automated way to detect and manage schema changes.
“I didn’t want to hire a data engineer to write ETL scripts to make these transformations every time,” Pattamatta said.
Challenge 3: Accelerating Customer Time-To-Value
Finally, DataBrain needed to boost its performance.
“This is a competitive space and in order to stand out, I wanted to make sure our product has the fastest user experience and our customers experience the least time to their aha moment in the market,” Pattamatta said.
This meant being able to automatically index the data during the initial ingest so that customers can effortlessly get insights right away on whatever questions they have.
“I want our product to be as self-service as possible,” Pattamatta said. ”I saw other solutions that required customers to spend 15 minutes with an engineer to set up the initial integrations. I want my customers to just point their integrations at us and have it work within seconds.”
Helping DataBrain Scale and Accelerate
Pattamatta heard about Rockset on a podcast with Rockset’s CTO and co-founder Dhruba Borthakur.
“I was initially drawn to Rockset because it seemed to offer an elegant solution to my schema problem,” Pattamatta said. “The fact that it could do analytics quickly was also important.”
Pattamatta was impressed by how easy it was to deploy Rockset.
“The serverless nature of Rockset made it incredibly simple to start on,” he said. “It took us only a couple days to set up our data pipelines into Rockset and after that, it was pretty straightforward. The docs were great.”
Solution 1: Scale using Rockset’s PostgreSQL integration
DataBrain took advantage of the native integration Rockset has with PostgreSQL. Desired datasets are instantly and automatically synced into Rockset, which readies the data for queries in a few seconds. Rockset then returns query results, even for complex analytical ones, in milliseconds.
Most importantly, Rockset is horizontally scalable. Compute and storage are completely decoupled in Rockset, enabling DataBrain to cost-optimize for the desired performance level. Besides letting DataBrain avoid doing analytics in pricey PostgreSQL, Rockset also allowed DataBrain to offload a large portion of its data from PostgreSQL into an S3 data lake, saving significantly on storage costs. And with a similar connector for S3 (and many other sources), Rockset can automatically stay in sync with both source databases by reading their change streams.
Solution 2: Ingest Dynamic, Semi-Structured Data
Rockset supports schemaless ingestion of raw semi-structured data. The schema does not need to be known or defined ahead of time, and no clunky ETL pipelines are required. In other words, Rockset does not require a schema but is nevertheless schema-aware, coupling the flexibility of schemaless ingestion at write time with the ability to infer the schema at read time. This is exactly what Databrain was looking for. By adopting Rockset, DataBrain didn’t need to hire a data engineer just to manage ETL scripts.
Solution 3: Rockset’s Converged Index™
DataBrain needed its customers’ semi-structured data to be indexed quickly so it could query the data immediately and show insights to customers right away. Rockset solves this through its Converged Index technology, which is optimized for different access patterns, including key-value, time-series, document, search and aggregation queries.
While most databases are optimized only for certain types of data or queries, Rockset can return very fast query results without knowing in advance the shape of the data or the type of queries. Both point lookups and aggregate queries can be extremely fast. Rockset’s P99 latency for filter queries on terabytes of data is in the low milliseconds.
This gave DataBrain both the speed and flexibility to significantly boost the performance of its service even as its customer base grows.
Rockset Gives DataBrain Flexibility and Speed
In summary, DataBrain was able to take advantage of Rockset’s out-of-box integration with PostgreSQL to offload its analytical workloads into the faster, more cost-efficient Rockset. Rockset’s Smart Schema feature was also critical, allowing DataBrain to use real-time SQL queries to extract meaningful insights from raw semi-structured data ingested without a predefined schema. Finally, Rockset’s Converged Index enables low data latency and query latency, giving DataBrain the speed to stay ahead of its competitors.