Faster Results and a Better Experience with New Pagination in Rockset

September 3, 2021
Summary:
- Pagination is a technique used to divide a result-set into smaller, more manageable chunks
- Historically, Rockset used the Limit-Offset method to implement pagination, but query results can be slow and inconsistent when dealing with very large data sets in real-time
- Rockset has now implemented a cursor-based approach for pagination, making queries faster, more consistent, and potentially cheaper for large data sets
- This is available today for all customers
Pagination is a familiar technique in the database world. If you’ve run a SQL query with Limit-Offset on a database like PostgreSQL then you already know what we are talking about here. However, for those who have never heard of the term, pagination is a technique used to divide a result-set of a query into smaller, more manageable chunks, often in the form of ‘pages’ of data that is presented one ‘page’ at a time. The primary reason to split up the result-set is to minimize the data size so it’s easier to manage. We’ve seen that most of our customer’s client apps can’t handle more than 100MiB at a time so they need a way to break it up.
Let’s walk through the example of displaying player’s rank on a gaming leaderboard like this one:

image source: https://pngtree.com/freepng/game-leaderboard-design_6064125.html
It’s likely that pagination was used in the background, especially if there is a long list of players participating in the game. The query might ask for the first few pages of all top players, so players can view their ranking compared to the other top players. Or another query could be to ask for a list of the players ranked immediately above and below a certain player, say all 250 above and 250 below.
Each of these queries requires quite a bit of computation power since not only are you querying live ranking data, which constantly changes in real-time, you will also be querying all profile data about the players. That could mean retrieving quite a lot of data. While Rockset has already implemented pagination using Limit-Offset, this method not only can take a long time but can also be resource heavy because Limit-Offset method recomputes the entire data set every time you request a different subset of the overall data.
Why did we build a new way to paginate?
Rockset provides real-time analytics so some may think that pagination is not an issue. After all, if you care about real-time data, you probably wouldn’t be interesting in stale data that results from pagination. Yet, Rockset has several customers who have asked for pagination because their result-set data size was too big to manage and they wanted a method of dealing with smaller data sizes. Because Limit-Offset requires Rockset to compute the entire query for every subset of the result, it can be challenging with a large result-set.
Here are some real examples from our customers that highlight these challenges:
- Large Data Export: A security analytics company allows its customers to join data the company collected with proprietary data the customers uploaded themselves. In turn, they provide the capability for customers to download the combined data. The size of the export often exceeded the client’s 100MiB limit. They need a way to parse this data into smaller chunks.
- Large Search: A job marketplace company must quickly display job search results over several pages, but the results were often too large, crashing their client. They need a way to paginate the data and only receive the subset of results.
As you can see, Limit-Offset has two main issues: Slow queries and inconsistent results.
Consider running the below query to pull the top scores between users ranked 1,000,000 to 1,000,100:
Select * from users order by score limit 100 offset 1000000
- Slow Queries. With such a large Offset value (1,000,000 in this example), the latency will be unacceptably slow because Rockset will need to scan through the entire million documents each time the page loads the next 100 result page. Though the user only wants to see the results for 100 users, the query would need to run through all million users and would rerun this over and over again for each subsequent page. This is grossly inefficient.
- Inconsistent Results. Limit-Offset queries are run one after another, in a serialized manner. So the first 100 results would be based on data at one point in time and the next 100 results would be based on data at a different point in time shortly in the future. This can result in inconsistent analysis. Since the data is collected in real-time, the data might have changed between the first and second queries so results would be inaccurate.
What is our new pagination method?
With these two challenges in mind, our engineering team worked hard to implement a new way to paginate through a large result set. In order to provide consistency and speed for these queries, the team moved to a cursor-based approach for pagination instead of the Limit-Offset method. With a cursor-based approach, Rockset queries all the data once then instead of sending the results all to the customer’s client, Rockset stores it temporarily in temporary storage. Now, as the client queries for a subset of data, Rockset only sends that subset. This removes the need to run the query on all data every time you need a subset of it.
To get more detailed, the response from calling the query endpoint would include the initial result-set (aka the first page), the total number of documents, the number of documents in the current page, a start cursor, and a next cursor which allows our users to retrieve the next set of documents following the initial result-set.
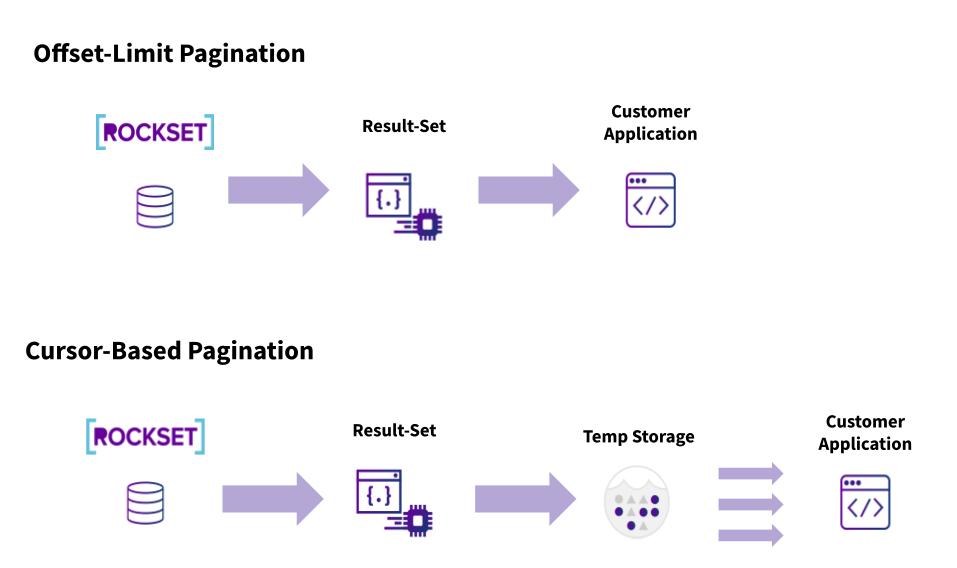
From this point onwards, the user can decide how to page through the results. They might be the same size, smaller, or bigger. If the next cursor is null, it means the last set of results was retrieved for this paginated query.
The result set will stay in temporary storage for enough time to retrieve all the results, multiple times. To check if the result set is still available, the list of available paginated queries, including their start cursor, can be retrieved through the queries endpoint.
Let’s see how pagination solved the above use-cases:
- Large Data Export: The security analytics company who was running into issues exporting large amounts of customer data at once can now just use the new cursor-based pagination and write the results to a file one page at a time
- Large Search: The job marketplace company trying to return a large result set for a search query can now use the cursor-based pagination to let users browse through several pages of the results without needing to run the search query, again and again, also guaranteeing the results will stay consistent
Start using the new approach to pagination today!
In conclusion, though Rockset’s previous method of pagination through Limit-Offset was adequate for most of our customers, we wanted to improve the experience for those with specialized needs so we implemented the cursor-based approach to pagination. This brings several benefits:
- Reduce Processing Needs: By querying only once to get all the result set stored in temporary storage, Rockset can now pull different subsets without repeatedly recomputing the query
- Improved Latency for Large Result-Sets: While the initial query might take longer to process, the following requests to pull pages out of the paginated query endpoint would be very fast
- Consistent Data: Results do not change with every new query since the data is pulled only once and saved as soon as the query finishes processing.
We are very excited to have you try it out! If you are interested, please fill out the request form here.