Getting Started with Apache Spark, S3 and Rockset for Real-Time Analytics

November 4, 2021
Apache Spark is an open-source project that was started at UC Berkeley AMPLab. It has an in-memory computing framework that allows it to process data workloads in batch and in real-time. Even though Spark is written in Scala, you can interact with Spark with multiple languages like Spark, Python, and Java.
Here are some examples of the things you can do in your apps with Apache Spark:
- Build continuous ETL pipelines for stream processing
- SQL BI and analytics
- Do machine learning, and much more!
Since Spark supports SQL queries that can help with data analytics, you’re probably thinking why would I use Rockset 🤔🤔?
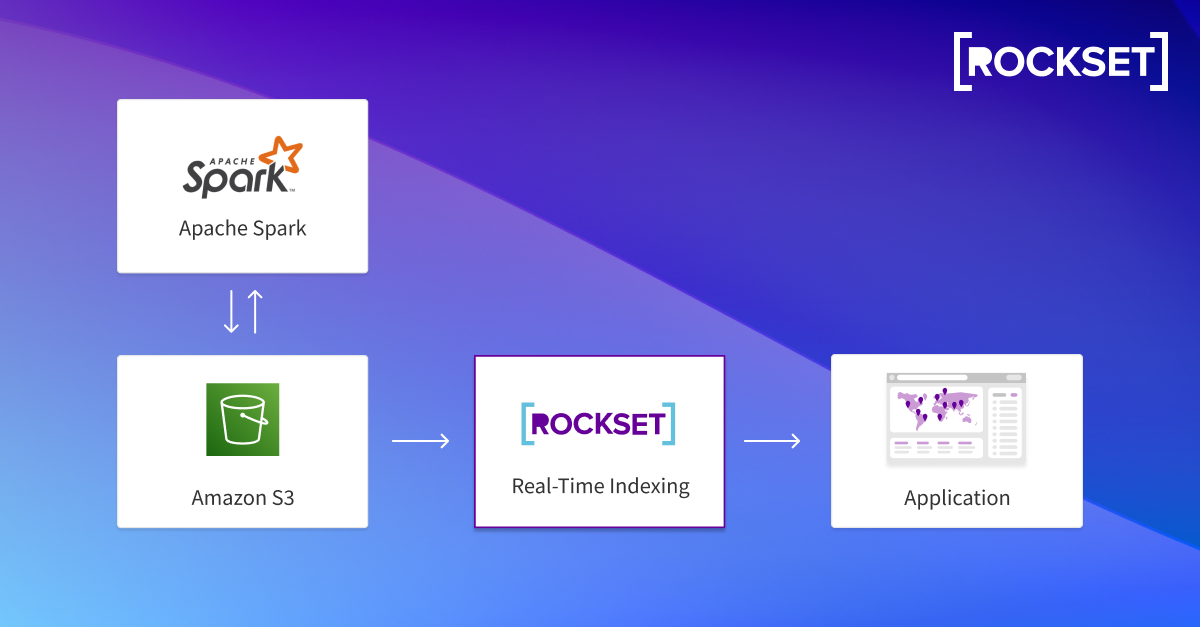
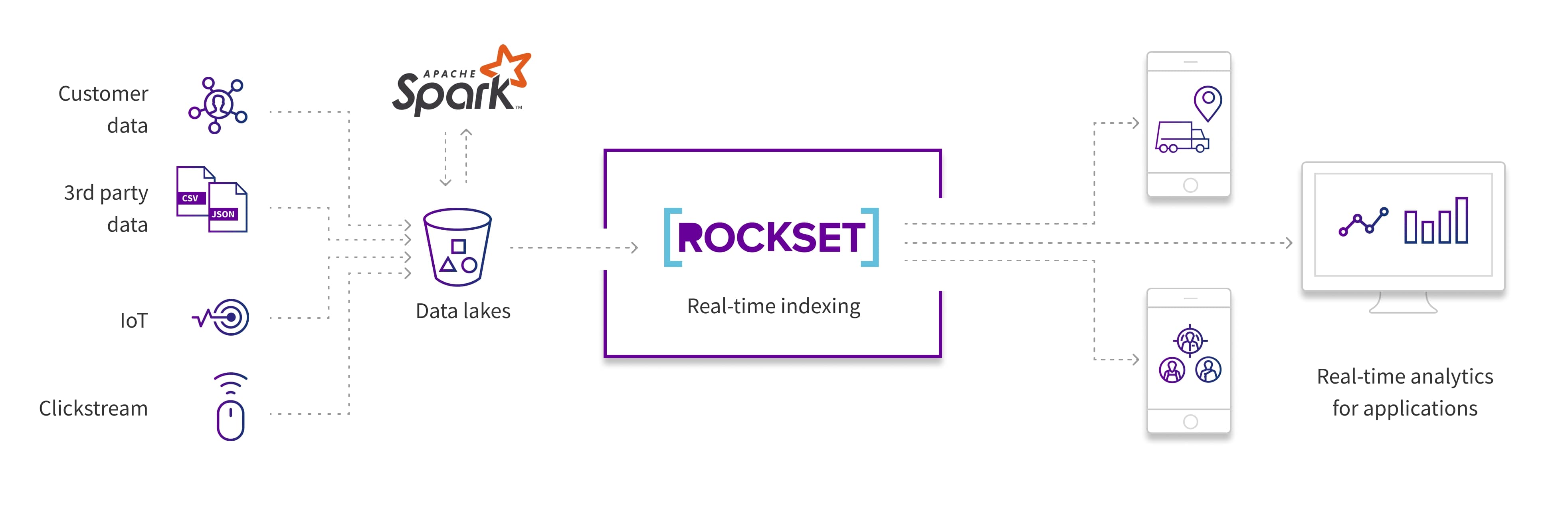
Rockset actually complements Apache Spark for real-time analytics. If you need real-time analytics for customer-facing apps, your data applications need millisecond query latency and support for high concurrency. Once you transform data in Apache Spark and send it to S3, Rockset pulls data from S3 and automatically indexes it via the Converged Index. You’ll be able to effortlessly search, aggregate, and join collections, and scale your apps without managing servers or clusters.
Let’s get started with Apache Spark and Rockset 👀!
Getting started with Apache Spark
You’ll need to ensure you have Apache Spark, Scala, and the latest Java version installed. If you’re on a Mac, you’ll be able to brew install it, otherwise, you can download the latest release here. Make sure that your profile is set to the correct paths for Java, Spark, and such.
We’ll also need to support integration with AWS. You can use this link to find the correct aws-java-sdk-bundle for the version of Apache Spark you’re application is using. In my case, I needed aws-java-sdk-bundle 1.11.375 for Apache Spark 3.2.0.
Once you’ve got everything downloaded and configured, you can run Spark on your shell:
$ spark-shell —packages com.amazonaws:aws-java-sdk:1.11.375,org.apache.hadoop:hadoop-aws:3.2.0
Be sure to set your Hadoop configuration values from Scala:
sc.hadoopConfiguration.set("fs.s3a.access.key","your aws access key")
sc.hadoopConfiguration.set("fs.s3a.secret.key","your aws secret key")
val rdd1 = sc.textFile("s3a://yourPath/sampleTextFile.txt")
rdd1.count
You should see a number show up on the terminal.
This is all great and dandy to quickly show that everything is working, and you set Spark correctly. How do you build a data application with Apache Spark and Rockset?
Create a SparkSession
First, you’ll need to create a SparkSession that’ll give you immediate access to the SparkContext:
Embedded content: https://gist.github.com/nfarah86/1aa679c02b74267a4821b145c2bed195
Read the S3 data
After you create the SparkSession, you can read data from S3 and transform the data. I did something super simple, but it gives you an idea of what you can do:
Embedded content: https://gist.github.com/nfarah86/047922fcbec1fce41b476dc7f66d89cc
Write data to S3
After you’ve transformed the data, you can write back to S3:
Embedded content: https://gist.github.com/nfarah86/b6c54c00eaece0804212a2b5896981cd
Connecting Rockset to Spark and S3
Now that we’ve transformed data in Spark, we can navigate to the Rockset portion, where we’ll integrate with S3. After this, we can create a Rockset collection where it’ll automatically ingest and index data from S3. Rockset's Converged Index allows you to write analytical queries that join, aggregate, and search with millisecond query latency.
Create a Rockset integration and collection
On the Rockset Console, you’ll want to create an integration to S3. The video goes over how to do the integration. Otherwise, you can easily check out these docs to set it up too! After you’ve created the integration, you can programmatically create a Rockset collection. In the code sample below, I’m not polling the collection until the status is READY. In another blog post, I’ll cover how to poll a collection. For now, when you create a collection, make sure on the Rockset Console, the collection status is Ready before you write your queries and create a Query Lambda.
Embedded content: https://gist.github.com/nfarah86/3106414ad13bd9c45d3245f27f51b19a
Write a query and create a Query Lambda
After your collection is ready, you can start writing queries and creating a Query Lambda. You can think of a Query Lambda as an API for your SQL queries:
Embedded content: https://gist.github.com/nfarah86/f8fe11ddd6bda7ac1646efad405b0405
This pretty much wraps it up! Check out our Rockset Community GitHub for the code used in the Twitch stream.
You can listen to the full video stream. The Twitch stream covers how to build a hello world with Apache Spark <=> S3 <=> Rockset.
Have questions about this blog post or Apache Spark + S3 + Rockset? You can always reach out on our community page.