Real-Time CDC With Rockset And Confluent Cloud

March 27, 2023
Breaking Bad… Data Silos
We haven’t quite figured out how to avoid using relational databases. Folks have definitely tried, and while Apache Kafka® has become the standard for event-driven architectures, it still struggles to replace your everyday PostgreSQL database instance in the modern application stack. Regardless of what the future holds for databases, we need to solve data silo problems. To do this, Rockset has partnered with Confluent, the original creators of Kafka who provide the cloud-native data streaming platform Confluent Cloud. Together, we’ve built a solution with fully-managed services that unlocks relational database silos and provides a real-time analytics environment for the modern data application.
My first practical exposure to databases was in a college course taught by Professor Karen Davis, now a professor at Miami University in Oxford, Ohio. Our senior project, based on the LAMP stack (Perl in our case) and sponsored with an NFS grant, put me on a path that unsurprisingly led me to where I am today. Since then, databases have been a major part of my professional life and modern, everyday life for most folks.
In the interest of full disclosure, it’s worth mentioning that I am a former Confluent employee, now working at Rockset. At Confluent I talked often about the fanciful sounding “Stream and Table Duality”. It’s an idea that describes how a table can generate a stream and a stream can be transformed into a table. The relationship is described in this order, with tables first, because that is often how most folks query their data. However, even within the database itself, everything starts as an event in a log. Often this takes the form of a transaction log or journal, but regardless of the implementation, most databases internally store a stream of events and transform them into a table.
If your company only has one database, you can probably stop reading now; data silos are not your problem. For everyone else, it’s important to be able to get data from one database to another. The products and tools to accomplish this task make up an almost $12 billion dollar market, and they essentially all do the same thing in different ways. The concept of Change Data Capture (CDC) has been around for a while but specific solutions have taken many shapes. The most recent of these, and potentially the most interesting, is real-time CDC enabled by the same internal database logging systems used to build tables. Everything else, including query-based CDC, file diffs, and full table overwrites is suboptimal in terms of data freshness and local database impact. This is why Oracle acquired the very popular GoldenGate software company in 2009 and the core product is still used today for real-time CDC on a variety of source systems. To be a real-time CDC flow we need to be event driven; anything less is batch and changes our decision capabilities.
Real-Time CDC Is The Way
Hopefully now you’re curious how Rockset and Confluent help you break down data silos using real-time CDC. As you would expect, it starts with your database of choice, although preferably one that supports a transaction log that can be used to generate real-time CDC events. PostgreSQL, MySQL, SQL Server, and even Oracle are popular choices, but there are many others that will work fine. For our tutorial we’ll focus on PostgreSQL, but the concepts will be similar regardless of the database.
Next, we need a tool to generate CDC events in real time from PostgreSQL. There are a few options and, as you may have guessed, Confluent Cloud has a built-in and fully managed PostgreSQL CDC source connector based on Debezium’s open-source connector. This connector is specifically designed to monitor row-level changes after an initial snapshot and write the output to Confluent Cloud topics. Capturing events this way is both convenient and gives you a production-quality data flow with built-in support and availability.
Confluent Cloud is also a great choice for storing real-time CDC events. While there are multiple benefits to using Confluent Cloud, the most important is the reduction in operational burden. Without Confluent Cloud, you would be spending weeks getting a Kafka cluster stood up, months understanding and implementing proper security and then dedicating several folks to maintaining it indefinitely. With Confluent Cloud, you can have all of that in a matter of minutes with a credit card and a web browser. You can learn more about Confluent vs. Kafka over on Confluent’s site.
Last, but by no means least, Rockset will be configured to read from Confluent Cloud topics and process CDC events into a collection that looks very much like our source table. Rockset brings three key features to the table when it comes to handling CDC events.
- Rockset integrates with several sources as part of the managed service (including DynamoDB and MongoDB). Similar to Confluent’s managed PostgreSQL CDC connector, Rockset has a managed integration with Confluent Cloud. With a basic understanding of your source model, like the primary key for each table, you have everything you need to process these events.
- Rockset also uses a schemaless ingestion model that allows data to evolve without breaking anything. If you are interested in the details, we’ve been schemaless since 2019 as blogged about here. This is crucial for CDC data as new attributes are inevitable and you don’t want to spend time updating your pipeline or postponing application changes.
- Rockset’s Converged Index™ is fully mutable, which gives Rockset the ability to handle changes to existing records in the same way the source database would, usually an upsert or delete operation. This gives Rockset a unique advantage over other highly indexed systems that require heavy lifting to make any changes, typically involving significant reprocessing and reindexing steps.
Databases and data warehouses without these features often have elongated ETL or ELT pipelines that increase data latency and complexity. Rockset generally maps 1 to 1 between source and target objects with little or no need for complex transformations. I’ve always believed that if you can draw the architecture you can build it. The design drawing for this architecture is both elegant and simple. Below you’ll find the design for this tutorial, which is completely production ready. I am going to break the tutorial up into two main sections: setting up Confluent Cloud and setting up Rockset.

Streaming Things With Confluent Cloud
The first step in our tutorial is configuring Confluent Cloud to capture our change data from PostgreSQL. If you don’t already have an account, getting started with Confluent is free and easy. Additionally, Confluent already has a well documented tutorial for setting up the PostgreSQL CDC connector in Confluent Cloud. There are a few notable configuration details to highlight:
- Rockset can process events whether “after.state.only” is set to “true” or “false”. For our purposes, the remainder of the tutorial will assume it’s “true”, which is the default.
- ”output.data.format” needs to be set to either “JSON” or “AVRO”. Currently Rockset doesn’t support “PROTOBUF” or “JSON_SR”. If you are not bound to using Schema Registry and you’re just setting this up for Rockset, “JSON” is the easiest approach.
- Set “Tombstones on delete” to “false”, this will reduce noise as we only need the single delete event to properly delete in Rockset.
-
I also had to set the table’s replica identity to “full” in order for delete to work as expected, but this might be configured already on your database.
ALTER TABLE cdc.demo.events REPLICA IDENTITY FULL; - If you have tables with high-frequency changes, consider dedicating a single connector to them since “tasks.max” is limited to 1 per connector. The connector, by default, monitors all non-system tables, so make sure to use “table.includelist” if you want a subset per connector.
There are other settings that may be important to your environment but shouldn’t affect the interaction between Rockset and Confluent Cloud. If you do run into issues between PostgreSQL and Confluent Cloud, it’s likely either a gap in the logging setup on PostgreSQL, permissions on either system, or networking. While it’s difficult to troubleshoot via blog, my best recommendation is to review the documentation and contact Confluent support. If you have done everything correct up to this point, you should see data like this in Confluent Cloud:

Real Time With Rockset
Now that PostgreSQL CDC events are flowing through Confluent Cloud, it is time to configure Rockset to consume and process those events. The good news is that it’s just as easy to set up an integration to Confluent Cloud as it was to set up the PostgreSQL CDC connector. Start by creating a Rockset integration to Confluent Cloud using the console. This can also be done programmatically using our REST API or Terraform provider, but those examples are less visually stunning.
Step 1. Add a new integration.

Step 2. Select the Confluent Cloud tile in the catalog.

Step 3. Fill out the configuration fields (including Schema Registry if using Avro).

Step 4. Create a new collection from this integration.

Step 5. Fill out the data source configuration.
- Topic name
- Starting offset (recommend earliest if the topic is relatively small or static)
- Data Format (ours will be JSON)
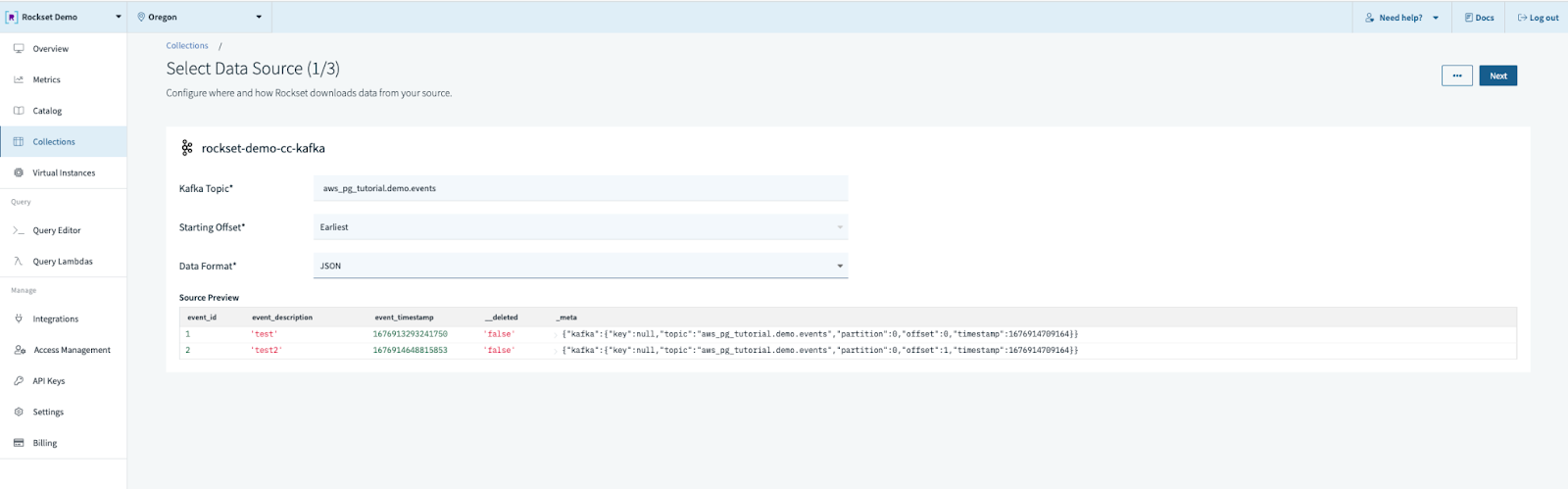

Step 6. Choose the “Debezium” template in “CDC formats” and select “primary key”. The default Debezium template assumes we have both a before and after image. In our case we don’t, so the actual SQL transformation will be similar to this:
SELECT
IF(input.__deleted = 'true', 'DELETE', 'UPSERT') AS _op,
CAST(_input.event_id AS string) AS _id,
TIMESTAMP_MICROS(CAST(_input.event_timestamp as int)) as event_timestamp,
_input.* EXCEPT(event_id, event_timestamp, __deleted)
FROM _input
Rockset has template support for many common CDC events, and we even have specialized _op codes for “_op” to suit your needs. In our example we are only concerned with deletes; we treat everything else as an upsert.

Step 7. Fill out the workspace, name, and description, and choose a retention policy. For this style of CDC materialization we should set the retention policy to “Keep all documents”.

Once the collection state says “Ready” you can start running queries. In just a few minutes you have set up a collection which mimics your PostgreSQL table, automatically stays updated with just 1-2 seconds of data latency, and is able to run millisecond-latency queries.
Speaking of queries, you can also turn your query into a Query Lambda, which is a managed query service. Simply write your query in the query editor, save it as a Query Lambda, and now you can run that query via a REST endpoint managed by Rockset. We’ll track changes to the query over time using versions, and even report on metrics for both frequency and latency over time. It’s a way to turn your data-as-a-service mindset into a query-as-a-service mindset without the burden of building out your own SQL generation and API layer.

The Amazing Database Race
As an amateur herpetologist and general fan of biology, I find technology follows a similar process of evolution through natural selection. Of course, in the case of things like databases, the “natural” part can sometimes seem a bit “unnatural”. Early databases were strict in terms of format and structure but quite predictable in terms of performance. Later, during the Big Data craze, we relaxed the structure and spawned a branch of NoSQL databases known for their loosey-goosey approach to data models and lackluster performance. Today, many companies have embraced real-time decision making as a core business strategy and are looking for something that combines both performance and flexibility to power their real time decision making ecosystem.
Fortunately, like the fish with legs that would eventually become an amphibian, Rockset and Confluent have risen from the sea of batch and onto the land of real time. Rockset’s ability to handle high frequency ingestion, a variety of data models, and interactive query workloads makes it unique, the first in a new species of databases that will become ever more common. Confluent has become the enterprise standard for real-time data streaming with Kafka and event-driven architectures. Together, they provide a real-time CDC analytics pipeline that requires zero code and zero infrastructure to manage. This allows you to focus on the applications and services that drive your business and quickly derive value from your data.
You can get started today with a free trial for both Confluent Cloud and Rockset. New Confluent Cloud signups receive $400 to spend during their first 30 days — no credit card required. Rockset has a similar deal – $300 in credit and no credit card required.