How Rockset Separates Compute and Storage Using RocksDB

June 6, 2023
Rockset is a real-time search and analytics database in the cloud. One of the ways Rockset maximizes price-performance for our customers is by separately scaling compute and storage. This improves efficiency and elasticity, but is challenging to implement for a real-time system. Real-time systems such as Elasticsearch were designed to work off of directly attached storage to allow for fast access in the face of real-time updates. In this blog, we’ll walk through how Rockset provides compute-storage separation while making real-time data available to queries.
The Challenge: Achieving Compute-Storage Separation without Performance Degradation
Traditionally databases have been designed to work off of systems with directly attached storage. This simplifies the system’s architecture and enables high bandwidth, low latency access to the data at query time. Modern SSD hardware can perform many small random reads, which helps indexes perform well. This architecture is well-suited for on-premise infrastructure, where capacity is pre-allocated and workloads are limited by the available capacity. However, in a cloud first world, capacity and infrastructure should adapt to the workload.
There are several challenges when using a tightly coupled architecture for real-time search and analytics:
- Overprovisioning resources: You cannot scale compute and storage resources independently, leading to inefficient resource utilization.
- Slow to scale: The system requires time for additional resources to be spun up and made available to users, so customers need to plan for peak capacity.
- Multiple copies of the dataset: Running multiple compute clusters on the same underlying dataset requires replicating the data onto each compute cluster.
If we could store all data in a shared location accessible by all compute nodes, and still achieve attached-SSD-equivalent performance, we would resolve all the above problems.
Scaling compute clusters would then depend on compute requirements alone, and would be more elastic as we don’t need to download the full dataset as part of each scaling operation. We can load larger datasets by just scaling the storage capacity. This enables multiple compute nodes to access the same dataset without increasing the number of underlying copies of the data. An additional benefit is the ability to provision cloud hardware specifically tuned for compute or storage efficiency.
A Primer on Rockset's Cloud-Native Architecture
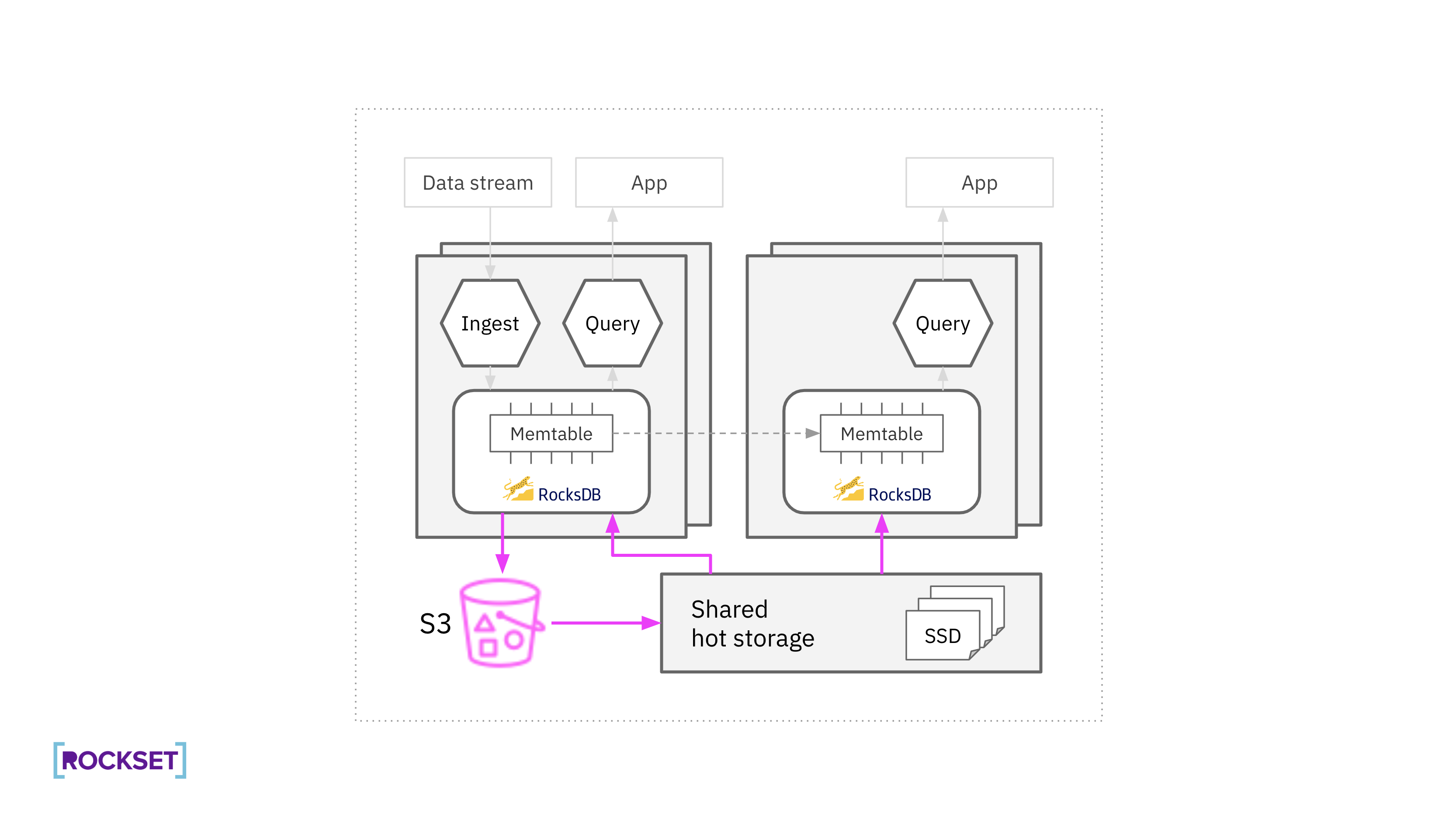
Rockset separates compute from storage. Virtual instances (VIs) are allocations of compute and memory resources responsible for data ingestion, transformations, and queries. Separately, Rockset has a hot storage layer composed of many storage nodes with attached SSDs for increased performance.
Under the hood, Rockset uses RocksDB as its embedded storage engine which is designed for mutability. Rockset created the RocksDB-Cloud library on top of RocksDB to take advantage of new cloud-based architectures. RocksDB-Cloud provides data durability even in the face of machine failures by integrating with cloud services like Amazon S3. This enables Rockset to have a tiered storage architecture where one copy of hot data is stored on SSDs for performance and replicas in S3 for durability. This tiered storage architecture delivers better price-performance for Rockset customers.
When we designed the hot storage layer, we kept the following design principles in mind:
- Similar query performance to tightly coupled compute-storage architecture
- No performance degradation during deployments or when scaling up/down
- Fault tolerance
How We Use RocksDB at Rockset
RocksDB is a popular Log Structured Merge (LSM) tree storage engine that is designed to handle high write rates. In an LSM tree architecture, new writes are written to an in-memory memtable and memtables are flushed, when they fill up, into immutable sorted strings table (SST) files. Rockset performs fine-grained replication of the RocksDB memtable so that the real-time update latency is not tied to the SST file creation and distribution process.
The SST files are compressed into uniform storage blocks for more efficient storage. When there is a data change, RocksDB deletes the old SST file and creates a new one with the updated data. This compaction process, similar to garbage collection in language runtimes, runs periodically, removing stale versions of the data and preventing database bloat.
New SST files are uploaded to S3, to ensure durability. The hot storage layer then fetches the files from S3, for performance. The files are immutable, which simplifies the role of the hot storage layer: it only needs to discover and store newly created SST files and evict old SST files.
When executing queries, RocksDB requests blocks of data, with each block represented by offset and size in a file, from the hot storage layer. RocksDB also caches recently accessed blocks in the compute node for fast retrieval.
In addition to the data files, RocksDB also stores metadata information in MANIFEST files that track the data files that represent the current version of the database. These metadata files are a fixed number per database instance and they are small in size. Metadata files are mutable and updated when new SST files are created, but are rarely read and never read during query execution.
In contrast to SST files, metadata files are stored locally on the compute nodes and in S3 for durability but not on the hot storage layer. Since metadata files are small and only read from S3 rarely, storing them on the compute nodes does not impact scalability or performance. Moreover, this simplifies the storage layer as it only needs to support immutable files.
Data Placement in the Hot Storage Layer
At a high level, Rockset’s hot storage layer is an S3 cache. Files are considered to be durable once they are written to S3, and are downloaded from S3 into the hot storage layer on demand. Unlike a regular cache, however, Rockset’s hot storage layer uses a broad range of techniques to achieve a cache hit rate of 99.9999%.
Distributing RocksDB Data in the Hot Storage Layer
Each Rockset collection, or a table in the relational world, is divided into slices with each slice containing a set of SST files. The slice is composed of all blocks that belong to those SST files. The hot storage layer makes data placement decisions at slice granularity.
Rendezvous hashing is used to map slices to their corresponding storage nodes, a primary and secondary owner storage node. The hash is also used by the compute nodes to identify the storage nodes to retrieve data from. The Rendezvous hashing algorithm works as follows:
- Each collection slice and storage node is given an ID. Those IDs are static and never change
- For every storage node, hash the concatenation of the slice ID and the storage node ID
- The resulting hashes are sorted
- The top two storage nodes from the ordered Rendezvous Hashing list are the slice’s primary and secondary owners

Rendezvous hashing was selected for data distribution because it contains several interesting properties:
- It yields minimal movements when the number of storage nodes changes. If we add or remove a node from the hot storage layer, the number of collection slices that will change owner while rebalancing will be proportional to 1/N where N is the number of nodes in the hot storage layer. This results in fast scaling of the hot storage layer.
- It helps the hot storage layer recover faster on node failure as responsibility for recovery is spread across all remaining nodes in parallel.
- When adding a new storage node, causing the owner for a slice to change, it’s straightforward to compute which node was the previous owner. The ordered Rendezvous hashing list will only shift by one element. That way, compute nodes can fetch blocks from the previous owner while the new storage node warms up.
- Each component of the system can individually determine where a file belongs without any direct communication. Only minimal metadata is required: the slice ID and the IDs of the available storage nodes. This is especially useful when creating new files, for which a centralized placement algorithm would increase latency and reduce availability.
While storage nodes work at the collection slice and SST file granularity, always downloading the entire SST files for the slices they are responsible for, compute nodes only retrieve the blocks that they need for each query. Therefore, storage nodes only need limited knowledge on the physical layout of the database, enough to know which SST files belong to a slice, and rely on compute nodes to specify block boundaries on their RPC requests.
Designing for Reliability, Performance, and Storage Efficiency
An implicit goal of all critical distributed systems, such as the hot storage tier, is to be available and performant at all times. Real-time analytics built on Rockset have demanding reliability and latency goals, which translates directly into demanding requirements on the hot storage layer. Because we always have the ability to read from S3, we think about reliability for the hot storage layer as our ability to service reads with disk-like latency.
Maintaining performance with compute-storage separation
Minimizing the overhead of requesting blocks through the network To ensure that Rockset's separation of compute-storage is performant, the architecture is designed to minimize the impact of network calls and the amount of time it takes to fetch data from disk. That’s because block requests that go through the network can be slower than local disk reads. Compute nodes for many real-time systems keep the dataset in attached storage to avoid this negative performance impact. Rockset employs caching, read-ahead, and parallelization techniques to limit the impact of network calls.
Rockset expands the amount of cache space available on compute nodes by adding an additional caching layer, an SSD-backed persistent secondary cache (PSC), to support large working datasets. Compute nodes contain both an in-memory block cache and a PSC. The PSC has a fixed amount of storage space on compute nodes to store RocksDB blocks that have been recently evicted from the in-memory block cache. Unlike the in-memory block cache, data in the PSC is persisted between process restarts enabling predictable performance and limiting the need to request cached data from the hot storage layer.
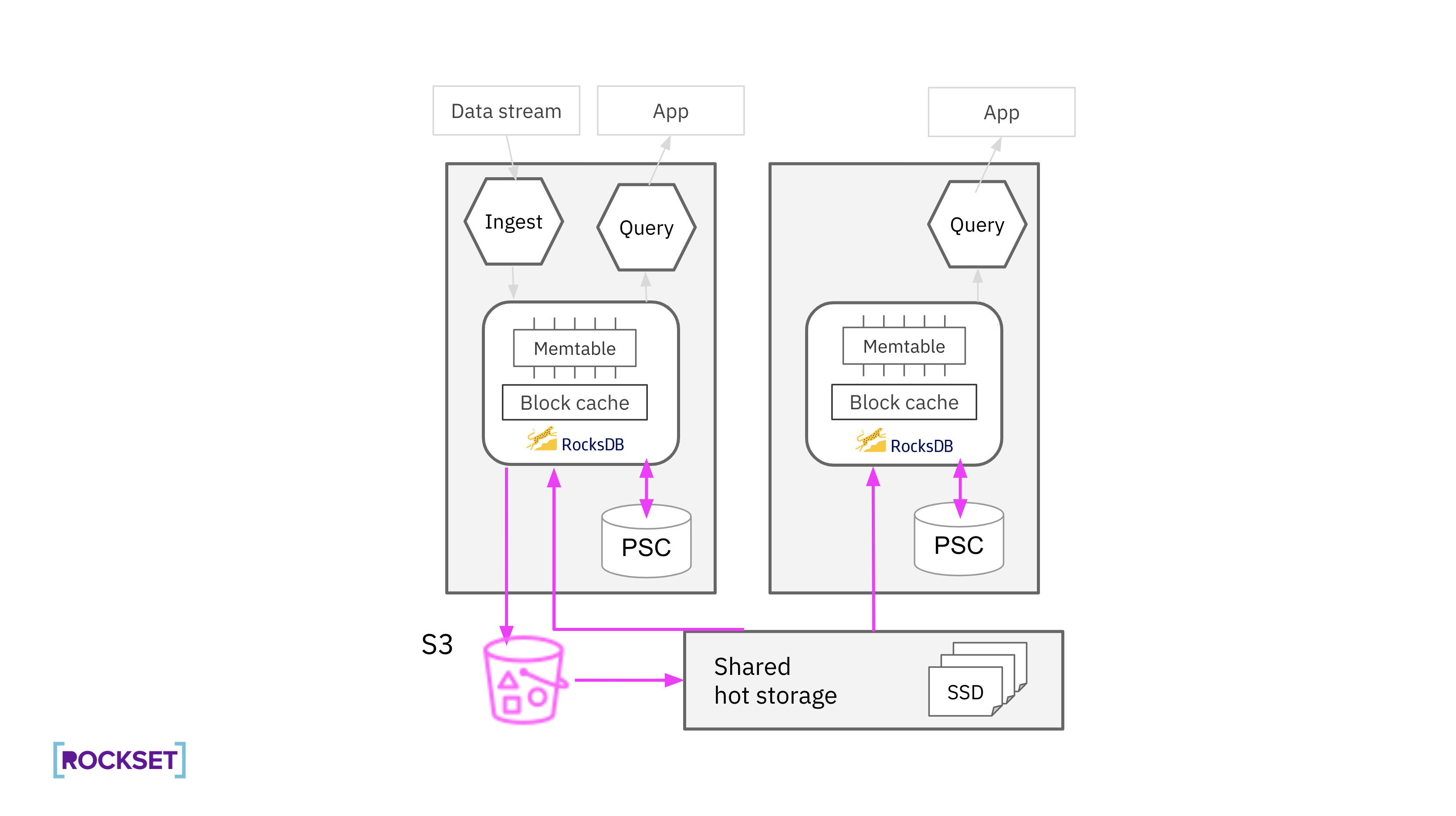
Query execution has also been designed to limit the performance penalty of requests going over the network using prefetching and parallelism. Blocks that will soon be required for computation are fetched in-parallel while compute nodes process the data they already have, hiding the latency of a network round trip. Several blocks are also fetched as part of a single request, reducing the number of RPCs and increasing the data transfer rate. Compute nodes can fetch blocks from the local PSC, possibly saturating the SSD bandwidth, and from the hot storage layer, saturating the network bandwidth, in parallel.
Avoiding S3 reads at query time Retrieving blocks available in the hot storage layer is 100x faster than read misses to S3, a difference of <1ms to 100ms. Therefore, keeping S3 downloads out of the query path is critical for a real-time system like Rockset.
If a compute node requests a block belonging to a file not found in the hot storage layer, a storage node must download the SST file from S3 before the requested block can be sent back to the compute node. To meet the latency requirements of our customers, we must ensure that all blocks needed at query time are available in the hot storage layer before compute nodes request them. The hot storage layer achieves this via three mechanisms:
- Compute nodes send a synchronous prefetch request to the hot storage layer every time a new SST file is created. This happens as part of memtable flushes and compactions. RocksDB commits the memtable flush or compaction operation after the hot storage layer downloads the file ensuring the file is available before a compute node can request blocks from it.
- When a storage node discovers a new slice, due to a compute node sending a prefetch or read block request for a file belonging to that slice, it proactively scans S3 to download the rest of the files for that slice. All files for a slice share the same prefix in S3, making this simpler.
- Storage nodes periodically scan S3 to keep the slices they own in sync. Any locally missing files are downloaded, and locally available files that are obsolete are deleted.
Replicas for Reliability
For reliability, Rockset stores up to two copies of files on different storage nodes in the hot storage layer. Rendezvous hashing is used to determine the primary and secondary owner storage nodes for the data slice. The primary owner eagerly downloads the files for each slice using prefetch RPCs issued by compute nodes and by scanning S3. The secondary owner only downloads the file after it has been read by a compute node. To maintain reliability in a scale up event, the previous owner maintains a copy until the new owners have downloaded the data. Compute nodes use the previous owner as a failover destination for block requests during that time.
When designing the hot storage layer, we realized that we could save on storage costs while still achieving resiliency by only storing a partial second copy. We use a LRU data structure to ensure that the data needed for querying is readily available even if one of the copies is lost. We allocate a fixed amount of disk space in the hot storage layer as a LRU cache for secondary copy files. From production testing we found that storing secondary copies for ~30-40% of the data, in addition to the in-memory block cache and PSC on compute nodes, is sufficient to avoid going to S3 to retrieve data, even in the case of a storage node crash.
Utilizing the spare buffer capacity to improve reliability Rockset further reduces disk capacity requirements using dynamically resizing LRUs for the secondary copies. In other data systems, buffer capacity is reserved for ingesting and downloading new data into the storage layer. We made the hot storage layer more efficient in the usage of local disk by filling the buffer capacity with dynamically resizing LRUs. The dynamic nature of the LRUs means that we can shrink the space used for secondary copies when there is an increased demand for ingesting and downloading data. With this storage design, Rockset fully utilizes the disk capacity on the storage nodes by using the spare buffer capacity to store data.
We also opted to store primary copies in LRUs for the cases where ingestion scales faster than storage. It’s theoretically possible that the cumulative ingestion rate of all virtual instances surpasses the rate at which the hot storage layer can scale capacity, where Rockset would run out of disk space and ingestion would halt without the use of LRUs. By storing primary copies in the LRU, Rockset can evict primary copy data that has not been recently accessed to make space for new data and continue ingesting and serving queries.
By reducing how much data we store and also utilizing more available disk space we were able to reduce the cost of running the hot storage layer significantly.
Safe code deploys on a single copy world The LRU ordering for all files is persisted to disk so that it survives deployments and process restarts. That said, we also needed to ensure the safe deployment or scaling the cluster without a second full copy of the dataset.
A typical rolling code deployment involves bringing down a process running the old version and then starting a process with a new version. With this there is a period of down time after the old process has drained and before the new process has readied up forcing us to choose between two non ideal options:
- Accept that files stored in the storage node will be unavailable during that time. Query performance can suffer in this case, as other storage nodes will need to download SST files on demand if requested by compute nodes before the storage node comes back online.
- While draining the process, transfer the data that the storage node is responsible for to other storage nodes. This would maintain the performance of the hot storage layer during deploys, but results in lots of data movement, making deploys take a much longer time. It’d also increase our S3 cost, due to the number of GetObject operations.
These tradeoffs show us how deployment methods created for stateless systems don’t work for stateful systems like the hot storage layer. So, we implemented a deployment process that avoids data movement while also maintaining availability of all data called Zero Downtime Deploys. Here’s how it works:
- A second process running a new code version is started on each storage node, while the process for the old code version is still running. As this new process running on the same hardware it also has access to all SST files already stored on that node
- The new processes then take over from the processes running the previous version of the binary, and start serving block requests from compute nodes.
- Once the new processes fully take over all responsibilities, the old processes can be drained.
Each process running on the same storage node falls into the same position in the Rendezvous Hashing ordered list. This enables us to double the number of processes without any data movement. A global config parameter (”Active version”) lets the system know which process is the effective owner for that storage node. Compute nodes use this information to decide which process to send requests to.
Beyond deploying with no unavailability this process has wonderful operational benefits. Launching services with new versions and the time at which the newer versions start handling requests are distinctly toggleable steps. This means we can launch new processes, slowly scale up traffic to them, and immediately roll back to the old versions without launching new processes, nodes, or any data movement if we see a problem. Immediate rollback means less chance for any issues.
Hot Storage Layer Resizing Operations for Storage Efficiency
Adding storage nodes to increase capacity The hot storage layer ensures that there is enough capacity to store a copy for each file. As the system approaches capacity, more nodes are added to the cluster automatically. Existing nodes drop data slices that now belong to the new storage node as soon as the new node fetches them, making room for other files.
The search protocol ensures that compute nodes are still able to find data blocks, even if the owner for a data slice has changed. If we add N storage nodes simultaneously, the previous owner for a slice will be at most at the (N+1)th position in the Rendezvous hashing algorithm. Therefore compute nodes can always find a block by contacting the 2nd, 3rd, …, (N+1)th server on the list (in parallel) if the block is available in the hot storage layer.
Removing storage nodes to decrease capacity If the hot storage layer detects that it is over provisioned, it will reduce the number of nodes to decrease cost. Simply scaling down a node would result in read misses to S3 while the remaining storage nodes download the data previously owned by the removed node. In order to avoid that, the node to be removed enters a “pre-draining” state:
- The storage node designated for deletion sends slices of data to the next-in-line storage node. The next-in-line storage node is determined by Rendezvous hashing.
- Once all slices have been copied to the next-in-line storage node, the storage node designated for deletion is removed from the Rendezvous hashing list. This ensures that the data is always available for querying even in the process of scaling down storage nodes.
This design enables Rockset to provide 99.9999% cache hit rate of its hot storage layer without requiring additional replicas of the data. Furthermore, it makes it faster for Rockset to scale up or down the system.
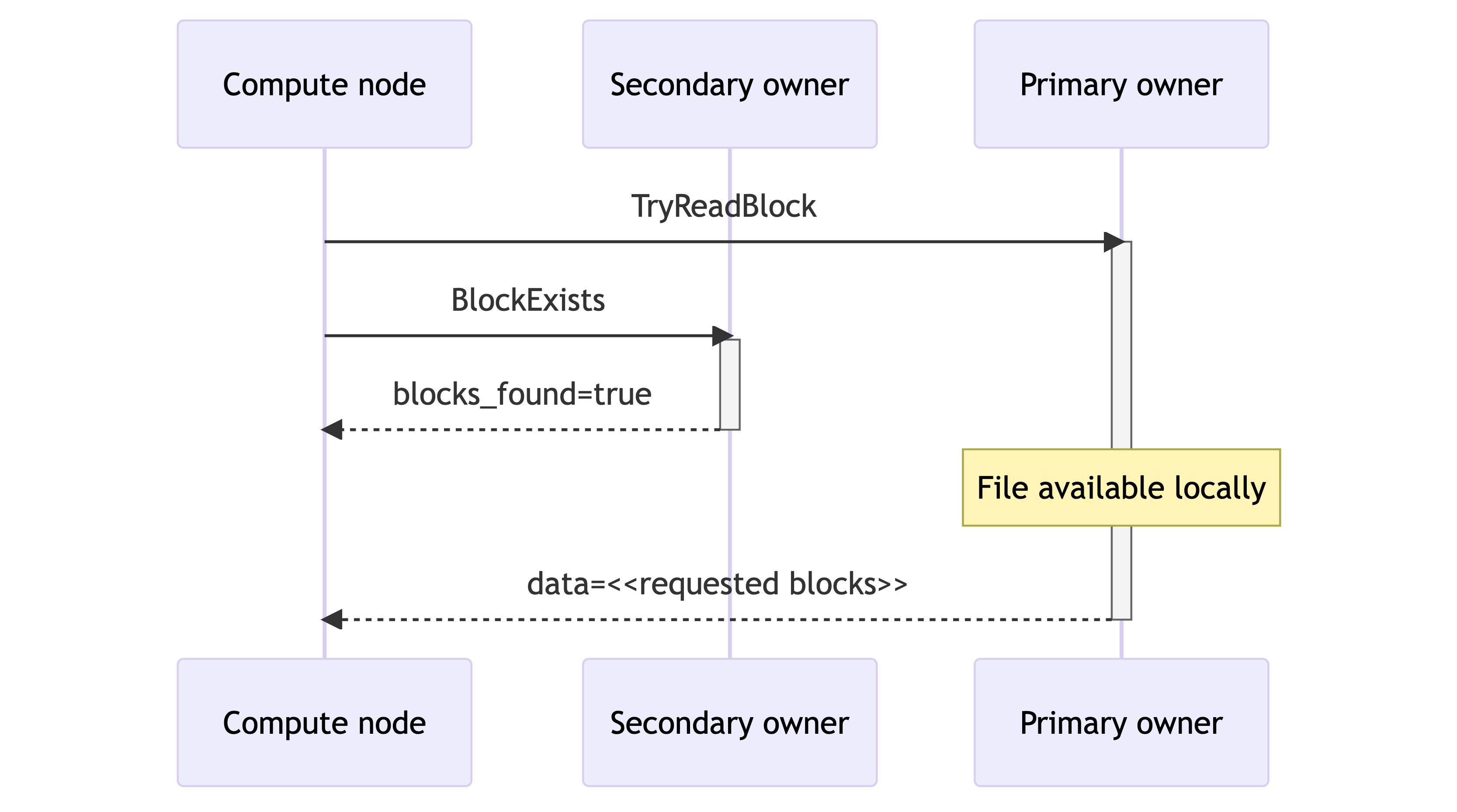
The communication protocol between compute and storage nodes To avoid accessing S3 at query time, compute nodes want to request blocks from the storage nodes that are most likely to have data on their local disk. Compute nodes achieve this through an optimistic search protocol:
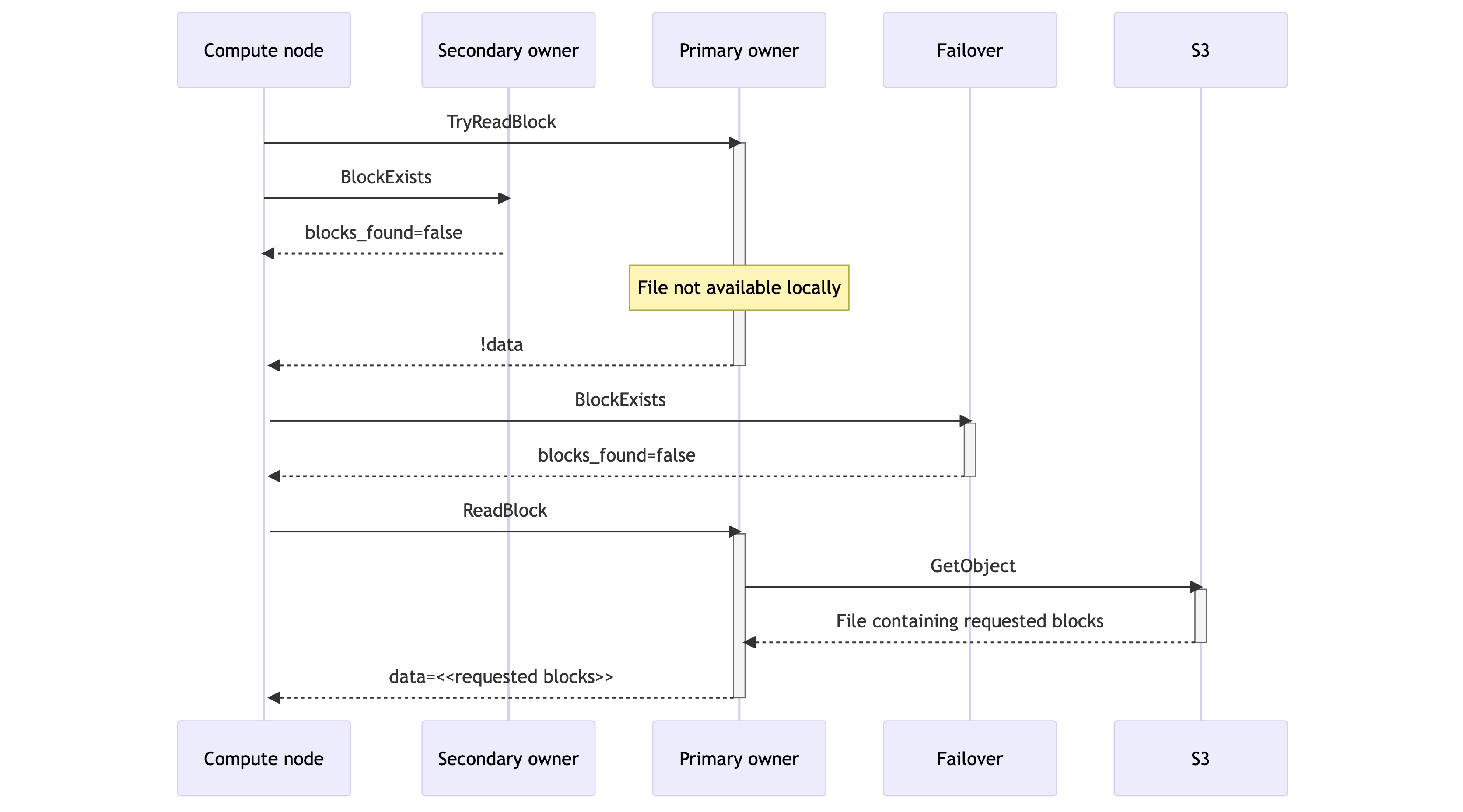
- The compute node sends a disk-only block request to the primary owner via a TryReadBlock RPC. The RPC returns an empty result if the block isn’t available on the storage node’s local disk. In parallel, the compute node sends an existence check to the secondary owner via BlockExists that returns a boolean flag indicating whether the block is available on the secondary owner.
- If the primary owner returns the requested block as part of the TryReadBlock response, the read has been fulfilled. Similarly, if the primary owner didn’t have the data but the secondary owner did, as indicated by the BlockExists response, the compute node issues a ReadBlock RPC to the secondary owner, thus fulfilling the read.
- If neither owner can provide the data immediately, the compute node sends a BlockExists RPC to the data slice’s designated failover destination. This is the next-in-line storage node according to Rendezvous Hashing. If the failover indicates that the block is available locally, the compute node reads from there.
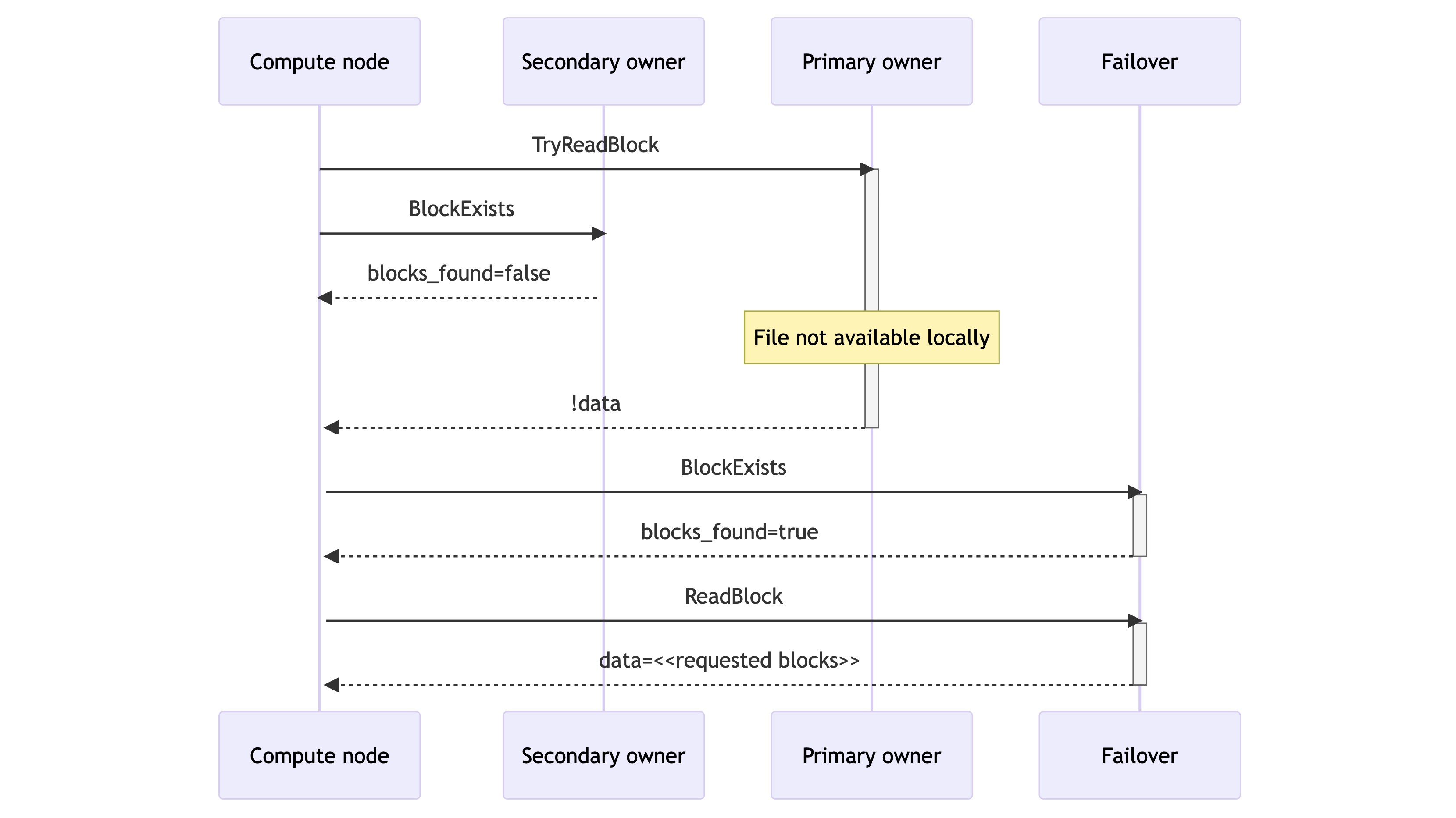
- If one of these three storage nodes had the file locally, then the read can be satisfied quickly (<1ms). In the extremely rare case of a complete cache miss, the ReadBlock RPC satisfies the request with a synchronous download from S3 that takes 50-100ms. This preserves query availability but increases query latency.
Goals of this protocol:
- Avoid the need for synchronous S3 downloads, if the requested blocks are present anywhere in the hot storage tier. The number of failover storage nodes contacted by the compute node in (3) above can be larger than one, to increase the likelihood of finding the data block if it’s available.
- Minimize load on storage nodes. Disk I/O bandwidth is a precious resource on storage nodes. The storage node that fulfills the request is the only one that needs to read data from the local disk. BlockExists is a very lightweight operation that doesn’t require disk access.
- Minimize network traffic. To avoid using unnecessary network I/O bandwidth, only one of the storage nodes returns the data. Sending two TryReadBlock requests to primary and secondary owners in (1) would save one round trip in some situations (i.e. if the primary owner doesn’t have the data but the secondary owner does). However, that’d double the amount of data sent through the network for every block read. The primary owner returns the requested blocks in the vast majority of cases, so sending duplicate data wouldn’t be an acceptable trade-off.
- Ensure that the primary and secondary owners are in sync with S3. The TryReadBlock and BlockExists RPCs will trigger an asynchronous download from S3 if the underlying file wasn’t available locally. That way the underlying file will be available for future requests.
The search process remembers the search results so for future requests the compute nodes only send a single TryReadBlock RPC to the previously accessed known-good storage node with the data. This avoids the BlockExists RPC calls to the secondary owner.
Advantages of the Hot Storage Layer
Rockset disaggregates compute-storage and achieves similar performance to tightly coupled systems with its hot storage layer. The hot storage layer is a cache of S3 that is built from the ground up to be performant by minimizing the overhead of requesting blocks through the network and calls to S3. To keep the hot storage layer price-performant, it is designed to limit the number of data copies, take advantage of all available storage space and scale up and down reliably. We introduced zero downtime deploys to ensure that there is no performance degradation when deploying new binaries.
As a result of separating compute-storage, Rockset customers can run multiple applications on shared, real-time data. New virtual instances can be instantly spun up or down to meet changing ingestion and query demands because there is no need to move any data. Storage and compute can also be sized and scaled independently to save on resource costs, making this more cost-effective than tightly coupled architectures like Elasticsearch.
The design of compute-storage separation was a crucial step in compute-compute separation where we isolate streaming ingest compute and query compute for real-time, streaming workloads. As of the writing of this blog, Rockset is the only real-time database that separates both compute-storage and compute-compute.
You can learn more about how we use RocksDB at Rockset by reading the following blogs:
- Introducing Compute-Compute Separation for Real-Time Analytics
- Optimizing Bulk Load in RocksDB
- How We Use RocksDB at Rockset
Authors: Yashwanth Nannapaneni, Software Engineer Rockset, and Esteban Talavera, Software Engineer Rockset