Search and analytics at cloud scale
Rockset is a real-time search and analytics database designed to serve millisecond-latency analytical queries on event streams, CDC streams, and vectors
Cloud-native efficiency
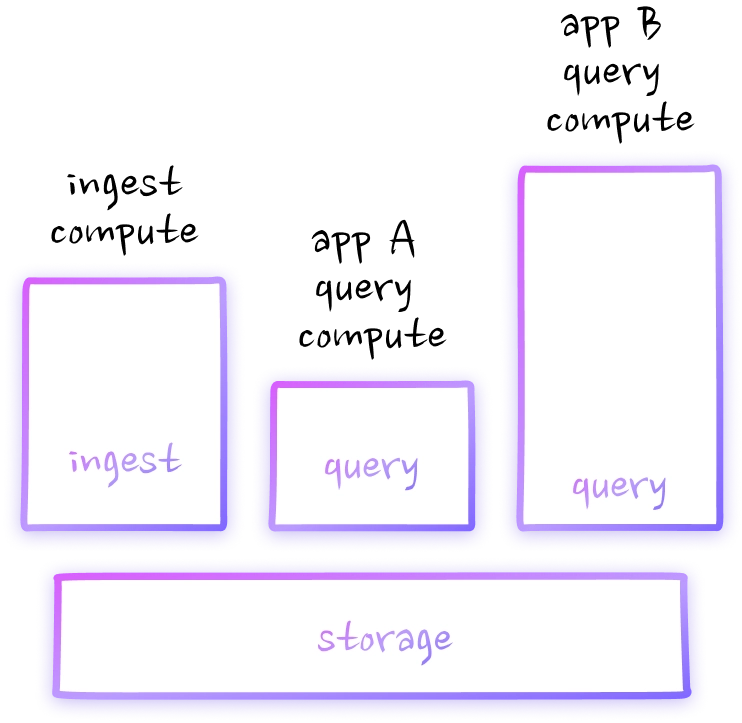
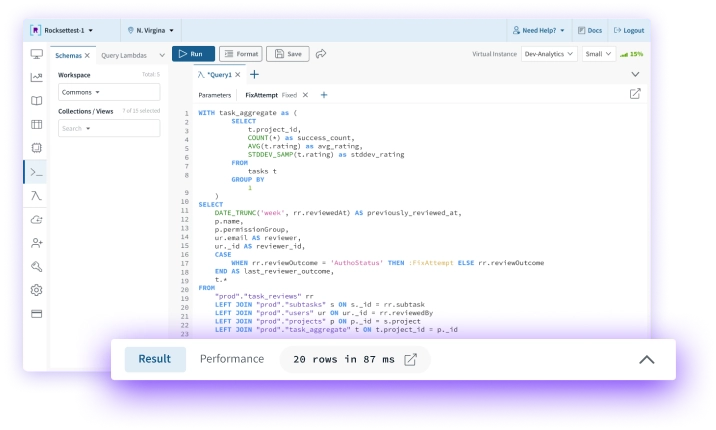
Compute-compute separation
Compute-storage separation
Autoscaling in the cloud
Fully-managed cloud service
Rockset isolates streaming ingest compute from query compute for predictable performance even in the face of high-volume writes or reads. Avoid compute contention, overprovisioning, and replicas.
Read our architecture whitepaper Real-time streaming ingest
Schemaless Ingest
Rockset automatically and continuously infers schema based on fields and types, even if types are mixed. Ingest semi-structured data or nested objects and arrays and execute relational SQL queries over these constructs.
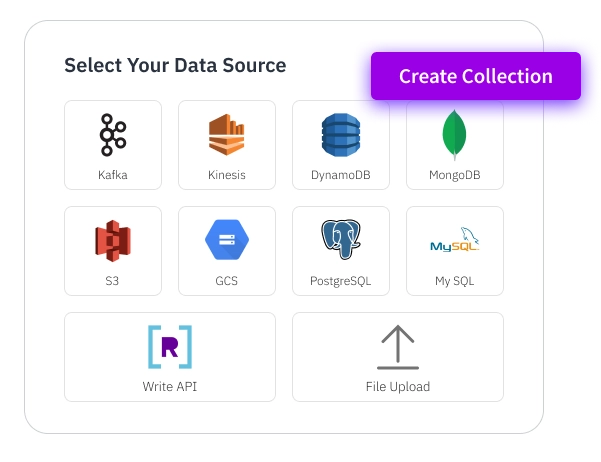
Built-In Connectors
Ingest data with native connectors for streams, databases, data lakes, and cloud data warehouses. Ingest from anywhere using the write API or CDC templates. Ingest millions of events per second and query within 2 seconds. No ETL tools required.
Ingest Transformations
Pre-aggregate and transform data at ingest time using SQL. Reduce the cost of storing and querying high-volume streaming data by up to 100x, and eliminate the need for separate pipelines to process streaming data.
Real-Time Speed
Ingest streaming data, index it, and query it with end to end latency less than a second.
In-Place Updates
Insert, update, and delete data in place without expensive merge operations. Avoid the slow, error prone workarounds for append only databases.
Millisecond-latency search & analytics
Converged Index
Rockset stores all data in a Converged Index, which combines row, column and inverted indexes. This enables fast, compute-efficient queries, regardless of the access pattern or shape of the data.
Full-Featured SQL
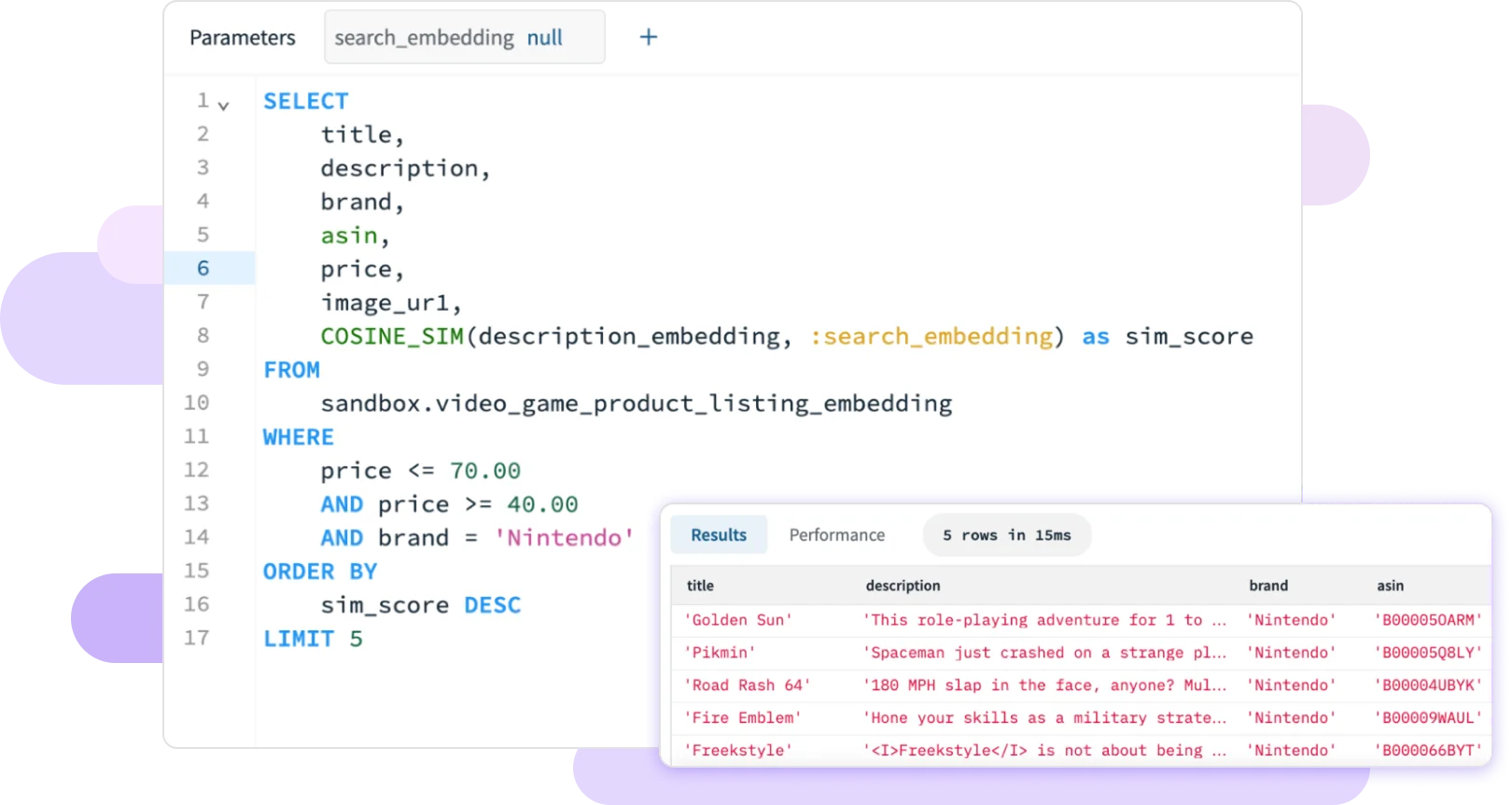
Run SQL search, aggregations and joins directly on semi-structured data. Rockset uses SQL as its native query language.
High-Performance Joins
Rockset supports multiple strategies to optimize join performance, so users do not have to denormalize data or perform application-side joins.
Vector Search
Fast KNN search with metadata filters to deliver relevant results with just milliseconds of latency.
Developer productivity
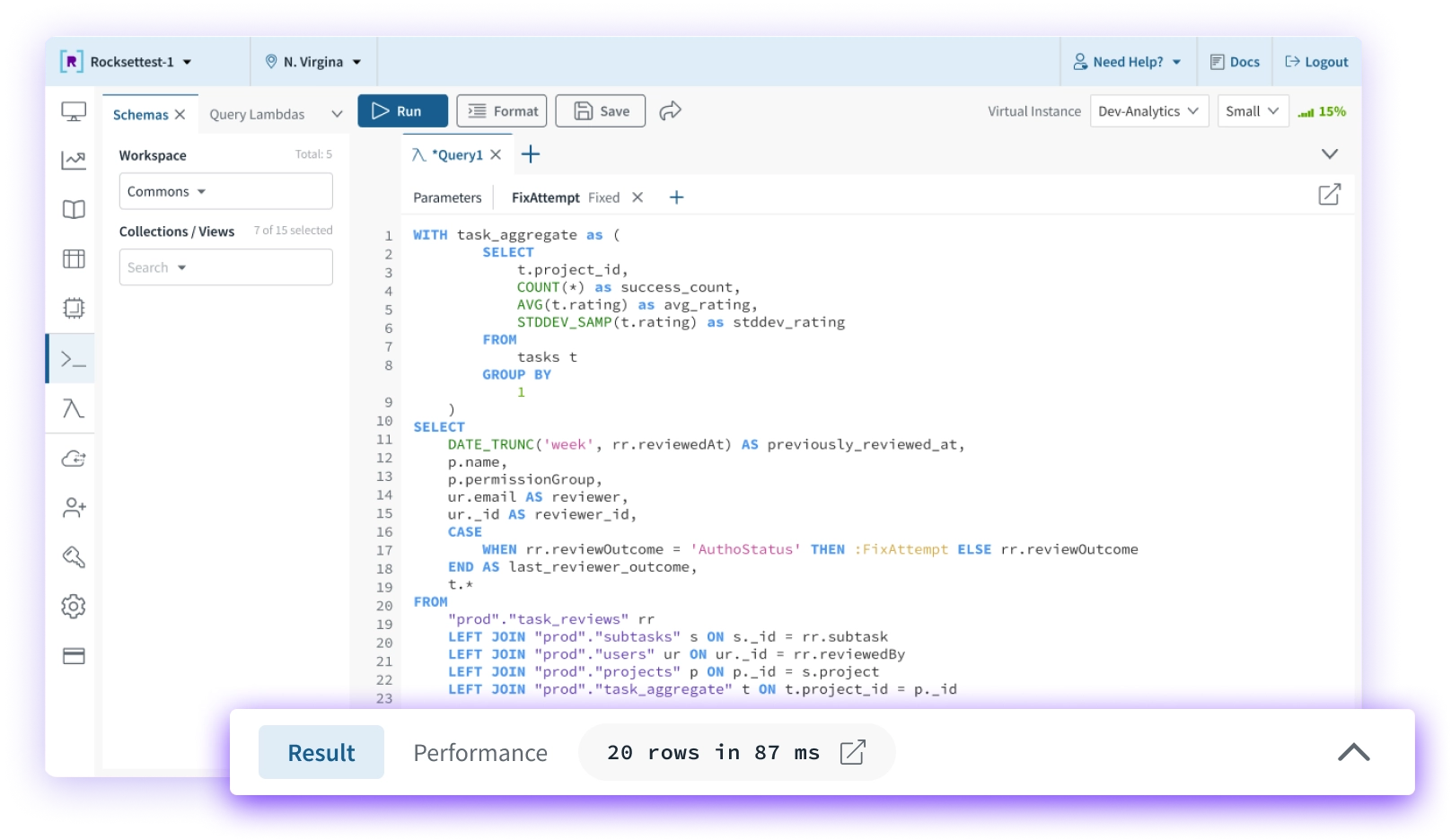
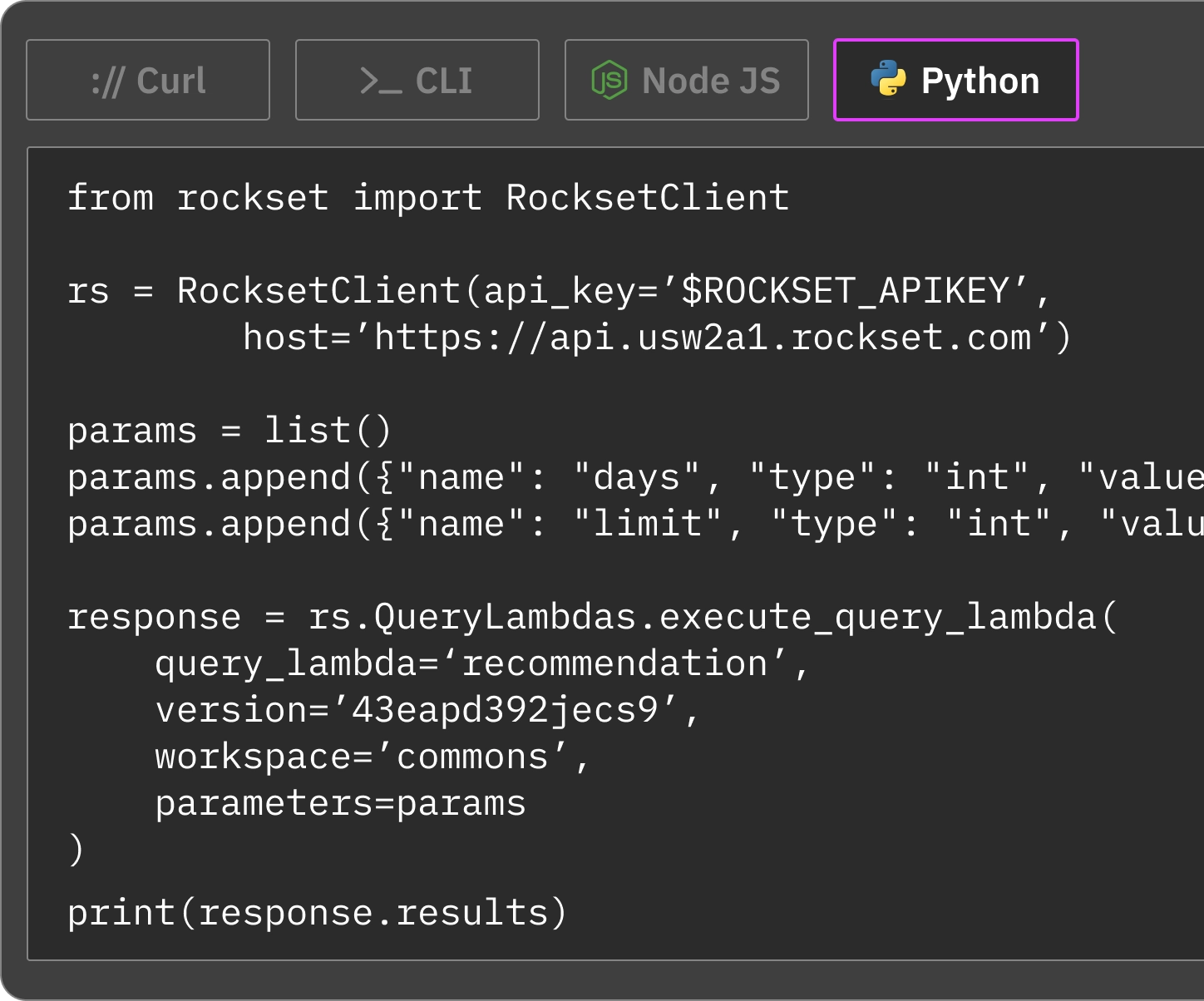
Query Lambdas
Query Lambdas are named, parameterized SQL queries that can be executed from dedicated REST endpoints. Enforce version control and integrate them into CI/CD workflows.
Resource Automation
Automatically deploy Rockset integrations, collections, resources, and third-party dependencies using the Rockset Terraform Provider. Use the dbt adapter to load data and create collections using SQL SELECT statements.
UDFs
JavaScript user-defined functions (UDFs) can perform operations beyond built-in SQL functions. They run in an isolated, sandboxed environment and provide support for advanced math functions, transpositions, and more.
SDKs
Rockset has client libraries for Node.js, Java, Go, Python, and the Rockset CLI that wrap the Rockset API. Client libraries can be used to programmatically insert, update, and query data from your application's code.
Production ready
Reliability
- Continuous backups with data stored on SSDs for performance and cloud storage for durability Disaster recovery with
- Multi-region hot-cold and hot-hot deployment options
- Enterprise SLAs
Compliance
- SOC 2 Type II
- HIPAA
- GDPR
- CCPA
Security
- Single Sign On with Okta and custom SSO
- Data Masking
- Data encrypted at rest and in transit
- Role Based Access Controls (RBAC)
- IP Allowlisting
- AWS Privatelink
- Virtual Private Rockset in your VPC
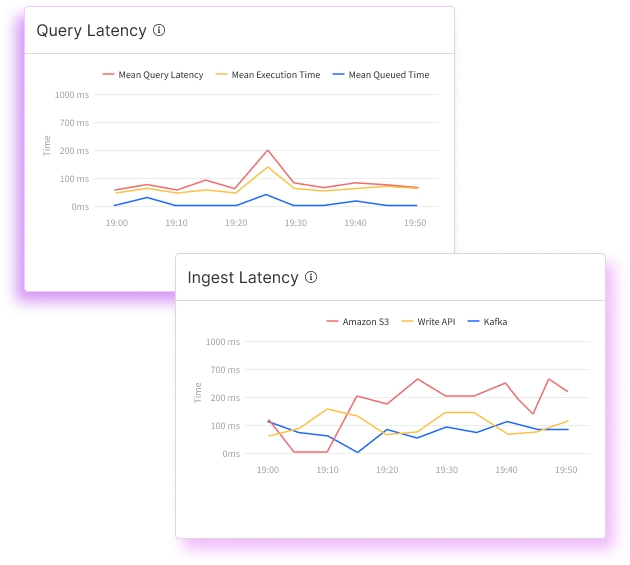
Monitoring
Performance metric endpoint