Rockset Product Overview
Use Rockset for your data-driven application
Follow our stories and unique insights.
About this video
Hi everyone, my name Nadine and I'm a Senior Developer Advocate here at Rockset and today I'm going to give you a product overview. Rockset is a real-time indexing database, serving low latency, high concurrency queries at scale. If you're familiar with search, then you'll find Rockset's converge indexing really interesting. Rockset is used for analytical queries, not just the dashboard kind. Think leader boards, personalization or recommendation engines, location search, and so on. We're talking real time analytics for apps.
There are many challenges when building real-time analytical applications. You'll need to have real time sync with your data source, you'll need to handle semi-structured data, you'll need to have multiple indexes for low latency queries and so on, but Rockset handles all of this out of the box, so let's see how you can get started.
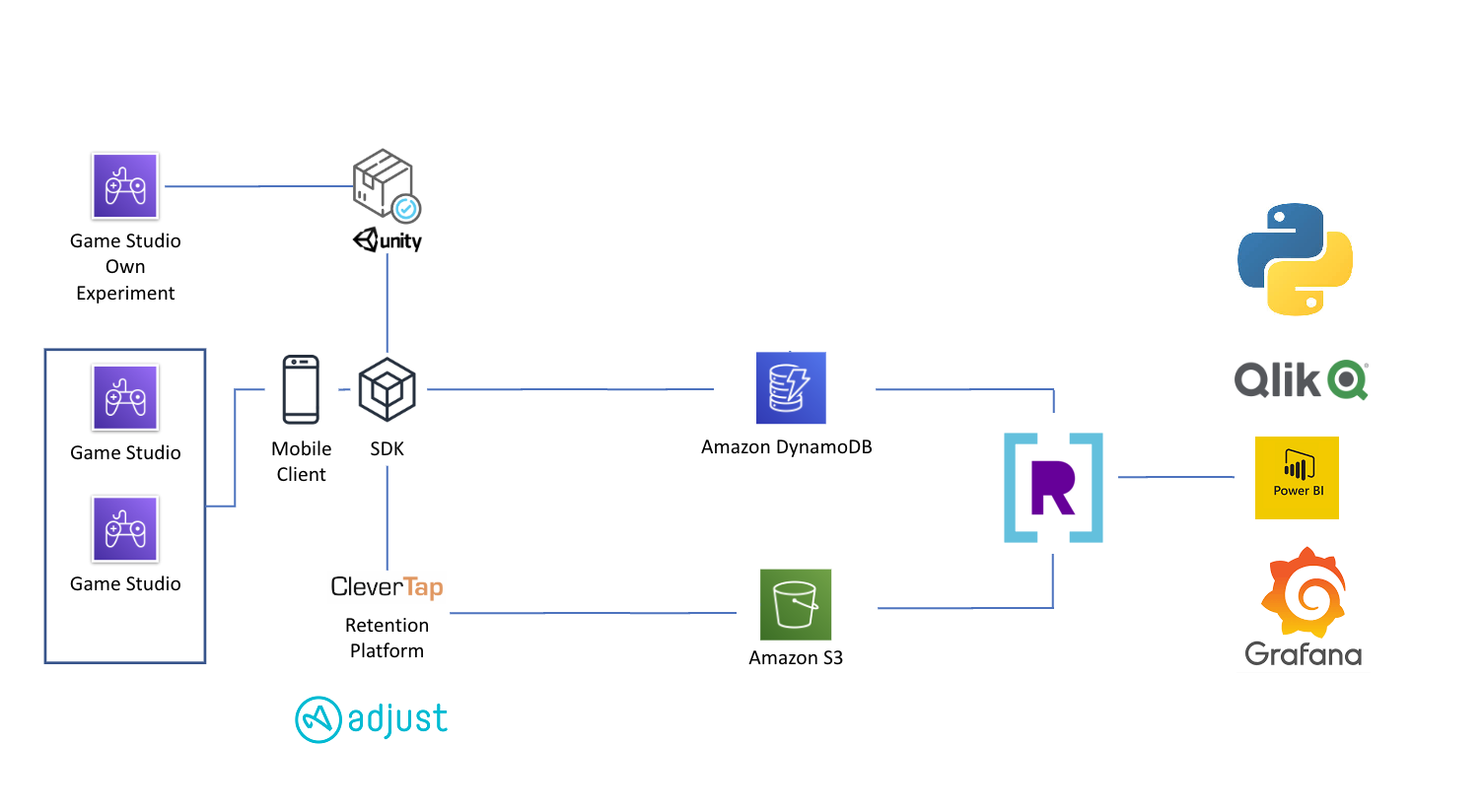
With Rockset you can get started with either the command line or the console. Let's go ahead and jump into the console. So create integration takes about three or four minutes where you'll provide read access to your data source. Rockset will do a bulk load followed by continuous [inaudible 00:01:04]. As you see, Rockset has multiple data source connectors so you can click and connect to your data source such as Mongo DB, Amazon S3, Apache Kafka, and DynamoDB. After Rockset bulk loads the data it'll switch to continuous ingest [inaudible 00:01:19] to sync with your stores so you never have to worry about your data being out of sync.
So now let's go ahead and create a collection from our integration. I'm going to go ahead and click on the collections tab and click on a collection I already made with the data that Rockset ingested. So Rockset creates smart schemas. Smart schemas are automatically generated schemas based on the exact fields and types present in the ingested data. The schema represents semi-structured data, nested objects and arrays, mixed types in nulls, enabling relational SQL queries.
So if I hover above a particular field, you'll see the percentage of what each data type shows up in that field. So here we have ... We have float types and we have in types. Similarly for cloudselling.value, you'll see there are null types and there are in types. So now let's go ahead and query the data now that it is in Rockset. So I'm going to go ahead and navigate to the query editor and we're going to go ahead and take a look at this query.
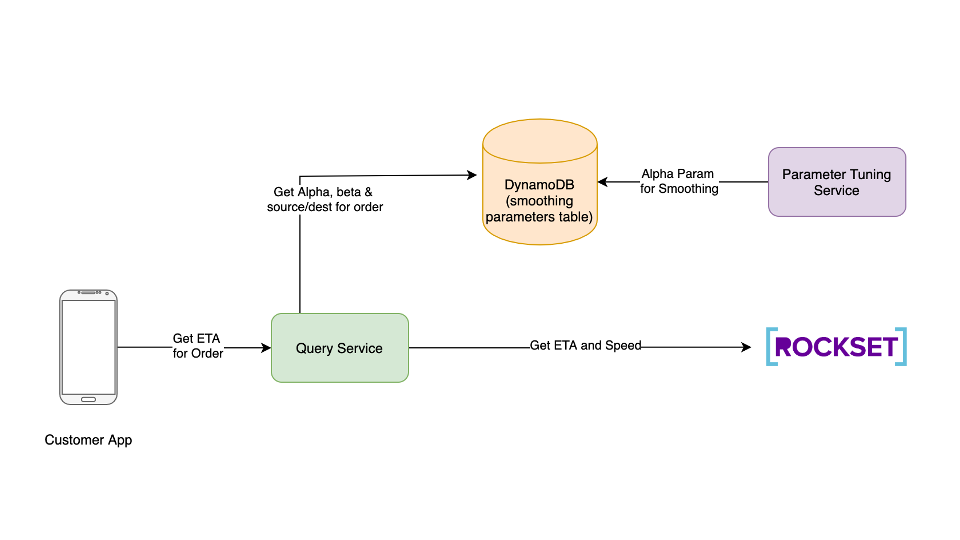
As you can see from the sample data set, we can do complex joins and we can also do aggregations, and at this point we haven't had to do any denormalization or data cleanup. We can actually just run this query on semi-structured data. And this is just a sample data set, but if you were to run a search query in a hundred billion records, it would return in under a hundred milliseconds and this is due to converged indexing. So all fields, including deeply nested fields are index and an inverted index like elastic search, column restore and row index, and our query optimizer selects the best index for the query.
This also means you don't have to do any more index management. You get fast queries out of the box, and we also support high volume rights while every field and document is being indexed. So now that we ran a query, we'll be able to create a rest endpoint and turn it into an API with the query lambda. I'm going to go ahead and click on create query lambda and fill out those details. Afterwards you'll be able to get a code snippet that you'll embed and execute in your application. This is what it looks like.
With query lambdas, you can enforce version control and integrate it to your CI/CD workflow. This is the same query lambda that we created earlier and I'm going to go ahead and run the project. And as you see, we're getting the same results that we did when we ran it in the console. So if you go to the Rockset docs, you'll see all the languages we support for the client libraries. So Rockset is serverless as you see, it auto scales in the cloud and automates cluster provisioning and index management. So if you want to learn more, go ahead and try out our quick start guide with a free developer account.