Elasticsearch SQL
Elasticsearch SQL is a feature provided by Elasticsearch that allows users to execute SQL-like queries to interact with the data stored in Elasticsearch indices.

Contents
What is Elasticsearch SQL?
Elasticsearch SQL is a feature provided by Elasticsearch that allows users to execute SQL-like queries to interact with the data stored in Elasticsearch indices. This feature is designed to make Elasticsearch more accessible to users who are familiar with SQL, the common language of analytics. In this blog, we’ll walk through the conversion of SQL to DSL, visualization integrations, and limitations of Elasticsearch SQL using an example application of a blog system.
Data Modeling in Elasticsearch
Elasticsearch stores data as documents within indices. Each document contains information related to a specific object and collections of documents are indexed for fast retrieval. Designing the right data model involves structuring your data into JSON documents based on the access patterns of your use case. This includes decisions on how to map your data fields to Elasticsearch's data types, whether to denormalize data, and how to use Elasticsearch features like nested objects or parent-child relationships.
When you use Elasticsearch SQL to query your data, the effectiveness of the queries is tied to how well your data is modeled. For example, if your data model doesn't reflect the relationships you need to query, or if the data types are not correctly defined, you might find it challenging to write efficient SQL queries or to get the query results you expect. While Elasticsearch SQL simplifies querying Elasticsearch data by using a familiar SQL syntax, it's predicated on ingesting and indexing your data correctly in Elasticsearch.
Let’s take a look at the role data modeling plays when creating a blog system in Elasticsearch. Coming from the relational world, data related to the author, post and comments would be stored in separate tables and joined at query time. To manage relational data, Elasticsearch uses a nested document model. This means that data which would traditionally be stored in separate tables is instead stored in a single document in a nested format. For a blog system, a single document could contain all the information about a post, including details about the author and any comments on the post, structured in a way that all these related pieces of information are part of the same document.
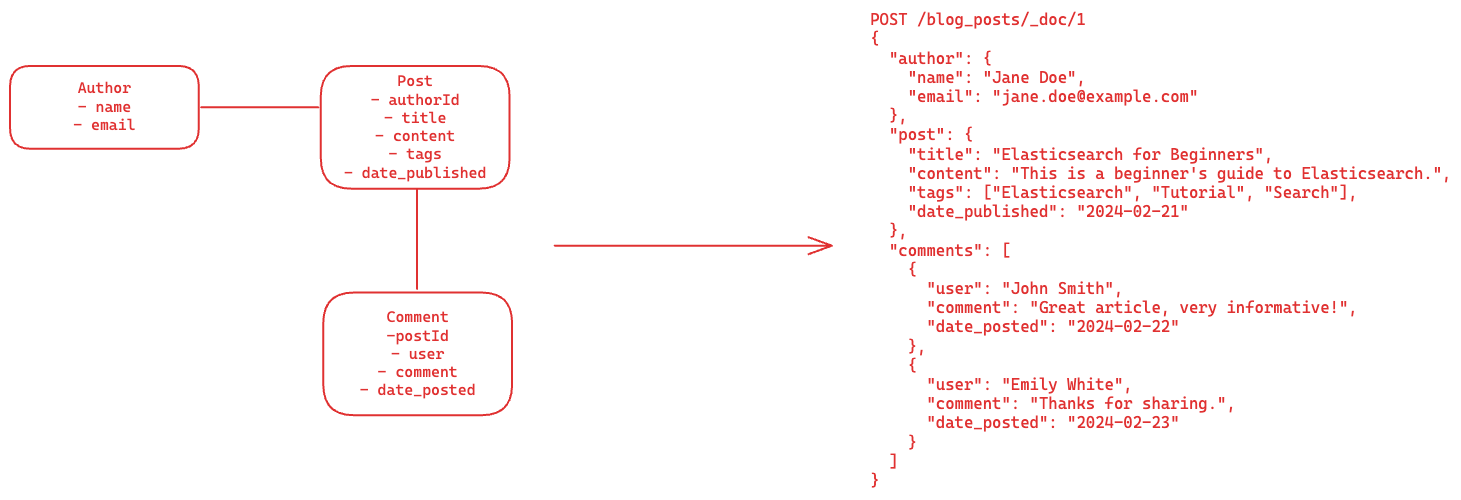
This document shows how a blog post, its author, and comments are stored in a nested Elasticsearch document, contrasting with the relational model where these would be in separate tables. You can see how SQL maps to Elasticsearch concepts below when data modeling:
|
SQL |
Elasticsearch |
Elasticsearch Example |
|---|---|---|
|
column |
field |
post.title |
|
row |
document |
document #1 |
|
table |
index |
blog_posts |
|
database |
cluster |
Cluster where all indices live |
While SQL and Elasticsearch have similar concepts, the main difference is that SQL is designed to model relationships between entities while in Elasticsearch how you model your data depends on how you consume it, so in many cases tables and indices are not a 1:1 comparison.
Implementation of Elasticsearch SQL
Elasticsearch SQL acts as an intermediary layer that translates SQL queries into Elasticsearch's native query DSL. This translation process allows users to leverage the familiar syntax of SQL to query data stored in Elasticsearch but comes with certain limitations, especially concerning the complexity and size of the SQL queries. The conversion process is straightforward and involves the following steps:
- Parsing: Transforming the SQL query into an Abstract Syntax Tree (AST) for structure and syntax validation.
- Analysis: Validating the AST and resolving references to tables, columns, and functions.
- Optimization: Streamlining the query by removing redundant expressions and optimizing its structure.
- Physical Planning and Execution: Translating the optimized query into Elasticsearch DSL and executing it.
This is how a SQL query maps to the Elasticsearch DSL :

Complex or large SQL queries can consume significant memory during the parsing and translation phase. This is because the engine must hold the entire query and its intermediate representations in memory as it converts the SQL syntax into the DSL format. The more complex the query, the more computational and memory resources are needed to process it.
When the Elasticsearch SQL engine has a query that requires more memory for parsing and translation than is available, it will abort the parsing process to prevent memory exhaustion, which could affect the stability of the Elasticsearch cluster. The engine will throw an error, indicating that the query could not be processed. There are strategies to mitigate large query issues including reducing the query size or splitting queries into smaller, more manageable queries.
Visualization of Elasticsearch SQL
Elasticsearch supports a SQL search API that accepts a SQL query in a JSON format and then returns the results.
The SQL query:
POST /_sql?format=txt
{
"query": """
SELECT author.name, post.title
FROM "blog_posts"
WHERE post.tags = 'Elasticsearch'
"""
}
The response:
author.name | post.title
---------------+---------------------------
Jane Doe | Elasticsearch for Beginners
In addition to the SQL search API, you can access Elasticsearch SQL through the SQL CLI, SQL JDBC driver and SQL ODBC driver. The SQL JDBC and SQL ODBC drivers open Elasticsearch to a range of visualization tools including:
- DBeaver
- DbVisualizer
- Microsoft Excel
- Microsoft Power BI Desktop
- Microsoft PowerShell
- MicroStrategy Desktop
- Qlik Sense Desktop
- SQuirreL SQL
- SQL Workbench
- Tableau Desktop
- Tableau Server
For the blog example, we used the Elasticsearch JDBC driver and the dedicated Elasticsearch Tableau Connector to visualize the number of blog posts by their tag. This type of visualization can help track the diversity of content in a blog.
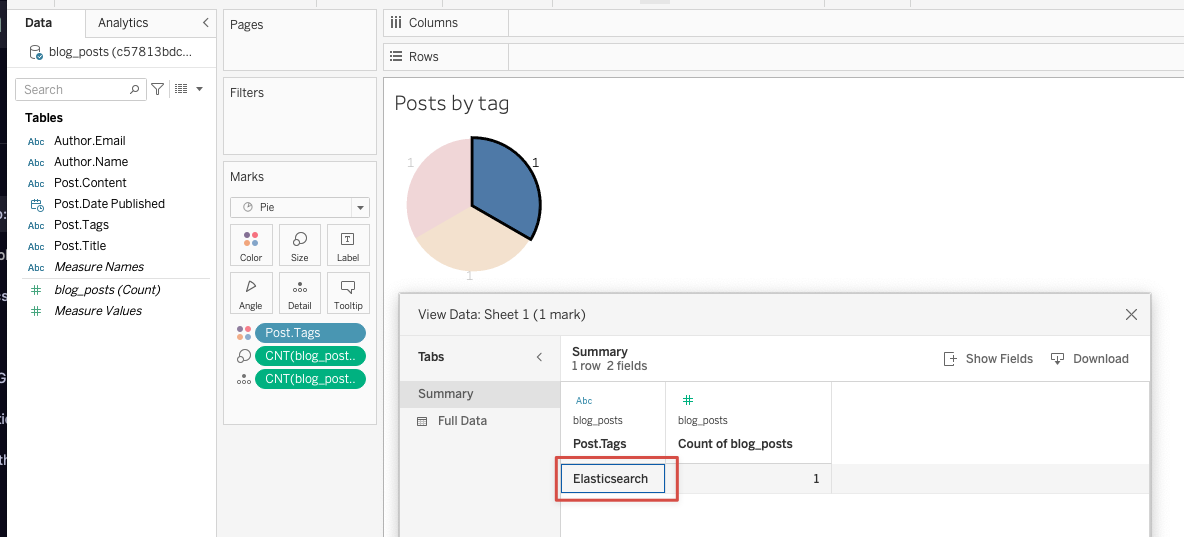
Queries using Elasticsearch SQL
Elasticsearch supports SQL functions including aggregation functions, grouping functions, date-time functions, full-text search functions and more.
That said, Elasticsearch has not altered its query capabilities to support SQL; it is just converting the SQL to the DSL under the hood. So, there are some limitations to the SQL functions it can support. These include:
- Table joins: Elasticsearch does not support SQL-style joins and so you will still need to model your data using denormalization, parent-child relationships, nested objects and application-side joins. There are no cross table join capabilities in Elasticsearch SQL.
- Sub selects: Sub-selects in SQL, also known as nested queries, allow you to use the result of one query within another query. They are useful for performing complex operations by breaking them down into smaller, more manageable steps, enhancing query flexibility and readability. SQL sub-selects are only supported in Elasticsearch SQL when the sub-selects can be flattened into a single select. Sub-selects that include GROUP BY or HAVING clauses are not supported.
- PIVOT clause: The pivot clause in SQL is used to transform row data into columnar format based on specific criteria, typically aggregating values along the way. It allows for dynamic cross-tabulation of data, facilitating analysis and reporting tasks efficiently. Elasticsearch only supports a single aggregation using the PIVOT clause.
- Scalar functions in nested fields: Scalar functions in SQL can be used to perform complex operations on a single field- mathematical calculations, string manipulations, date and time formatting, conversion between data types- minimizing the amount of data manipulation in application code. Elasticsearch SQL cannot apply scalar functions to nested fields with the WHERE and ORDER BY clauses, except when using comparisons or logical operators.
- TIME data type in GROUP BY or HISTOGRAM: Using TIME as a grouping key is not supported.
Elasticsearch Limitations
As we’ve discussed in the sections above, Elasticsearch SQL is used for querying and cannot take the place of data modeling and index management best practices. It also is read only meaning that you cannot create, update or delete documents using Elasticsearch SQL. There are several additional limitations related to Elasticsearch SQL:
- The SQL query can only contain a single nested field. This limitation is in place because of the complexity involved in parsing and executing SQL queries that involve multiple levels of nested data.
- Fields using the normalizer feature are not supported, likely because SQL queries are generally case-sensitive and expect exact matches.
- Array fields are not supported. It’s difficult to represent and manipulate arrays within a SQL framework, which is designed around scalar values.
- Sorting needs to be applied on the key used for aggregation buckets. The aggregations used in the ORDER BY cannot contain scalar functions, operators or complex columns. This restriction ensures that sorting operations are predictable and manageable within the context of aggregated data, where each bucket represents a collection of documents rather than individual entries.
- Geo fields cannot be used for filtering, grouping or sorting.
Conclusion
Elasticsearch SQL helps end users who have a familiarity with SQL access and adopt Elasticsearch. While Elasticsearch SQL can be used to run simple queries, it does not replace the need for data modeling in Elasticsearch.
To achieve optimal performance and the widespread benefits of Elasticsearch, it is recommended that you use the native Elasticsearch DSL based on JSON. Or, you can try the cloud-native, SQL alternative to Elasticsearch, Rockset, which delivers fast SQL search, aggregations and joins using a document data model. Start a free trial with $300 in credits to compare Rockset to Elasticsearch today.