A Blueprint for a Real-World Recommendation System

December 19, 2023
Overview
In this guide, we will:
- Understand the Blueprint of any modern recommendation system
- Dive into a detailed analysis of each stage within the blueprint
- Discuss infrastructure challenges associated with each stage
- Cover special cases within the stages of the recommendation system blueprint
- Get introduced to some storage considerations for recommendation systems
- And finally, end with what the future holds for the recommendation systems
Introduction
In a recent insightful talk at Index conference, Nikhil, an expert in the field with a decade-long journey in machine learning and infrastructure, shared his valuable experiences and insights into recommendation systems. From his early days at Quora to leading projects at Facebook and his current venture at Fennel (a real-time feature store for ML), Nikhil has traversed the evolving landscape of machine learning engineering and machine learning infrastructure specifically in the context of recommendation systems. This blog post distills his decade of experience into a comprehensive read, offering a detailed overview of the complexities and innovations at every stage of building a real-world recommender system.
Recommendation Systems at a high level
At an extremely high level, a typical recommender system starts simple and can be compartmentalized as follows:
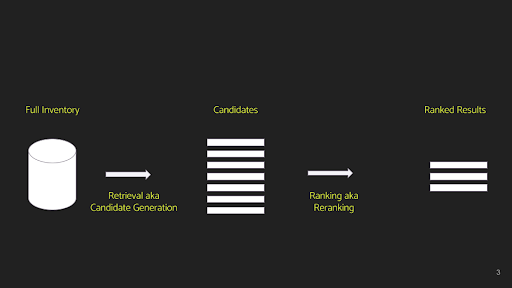
Note: All slide content and related materials are credited to Nikhil Garg from Fennel.
Stage 1: Retrieval or candidate generation - The idea of this stage is that we typically go from millions or even trillions (at the big-tech scale) to hundreds or a couple of thousand candidates.
Stage 2: Ranking - We rank these candidates using some heuristic to pick the top 10 to 50 items.
Note: The necessity for a candidate generation step before ranking arises because it's impractical to run a scoring function, even a non-machine-learning one, on millions of items.
Recommendation System - A general blueprint
Drawing from his extensive experience working with a variety of recommendation systems in numerous contexts, Nikhil posits that all forms can be broadly categorized into the above two main stages. In his expert opinion, he further delineates a recommender system into an 8-step process, as follows:
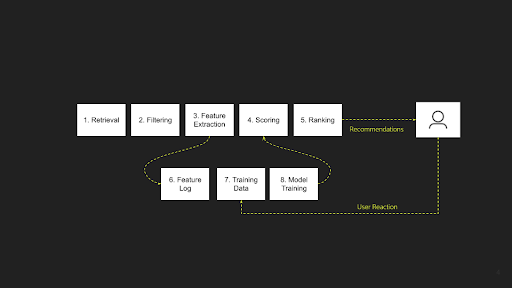
The retrieval or candidate generation stage is expanded into two steps: Retrieval and Filtering. The process of ranking the candidates is further developed into three distinct steps: Feature Extraction, Scoring, and Ranking. Additionally, there's an offline component that underpins these stages, encompassing Feature Logging, Training Data Generation, and Model Training.
Let's now delve into each stage, discussing them one by one to understand their functions and the typical challenges associated with each:
Step 1: Retrieval
Overview: The primary objective of this stage is to introduce a quality inventory into the mix. The focus is on recall — ensuring that the pool includes a broad range of potentially relevant items. While some non-relevant or 'junk' content may also be included, the key goal is to avoid excluding any relevant candidates.
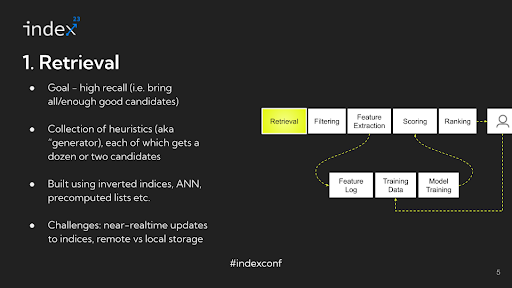
Detailed Analysis: The key challenge in this stage lies in narrowing down a vast inventory, potentially comprising a million items, to just about a thousand, all while ensuring that recall is preserved. This task might seem daunting at first, but it's surprisingly manageable, especially in its basic form. For instance, consider a simple approach where you examine the content a user has interacted with, identify the authors of that content, and then select the top five pieces from each author. This method is an example of a heuristic designed to generate a set of potentially relevant candidates. Typically, a recommender system will employ dozens of such generators, ranging from straightforward heuristics to more sophisticated ones that involve machine learning models. Each generator typically yields a small group of candidates, about a dozen or so, and rarely exceeds a couple dozen. By aggregating these candidates and forming a union or collection, each generator contributes a distinct type of inventory or content flavor. Combining a variety of these generators allows for capturing a diverse range of content types in the inventory, thus addressing the challenge effectively.
Infrastructure Challenges: The backbone of these systems frequently involves inverted indices. For example, you might associate a specific author ID with all the content they've created. During a query, this translates into extracting content based on particular author IDs. Modern systems often extend this approach by employing nearest-neighbor lookups on embeddings. Additionally, some systems utilize pre-computed lists, such as those generated by data pipelines that identify the top 100 most popular content pieces globally, serving as another form of candidate generator.
For machine learning engineers and data scientists, the process entails devising and implementing various strategies to extract pertinent inventory using diverse heuristics or machine learning models. These strategies are then integrated into the infrastructure layer, forming the core of the retrieval process.
A primary challenge here is ensuring near real-time updates to these indices. Take Facebook as an example: when an author releases new content, it's imperative for the new Content ID to promptly appear in relevant user lists, and simultaneously, the viewer-author mapping process needs to be updated. Although complex, achieving these real-time updates is essential for the system's accuracy and timeliness.
Major Infrastructure Evolution: The industry has seen significant infrastructural changes over the past decade. About ten years ago, Facebook pioneered the use of local storage for content indexing in Newsfeed, a practice later adopted by Quora, LinkedIn, Pinterest, and others. In this model, the content was indexed on the machines responsible for ranking, and queries were sharded accordingly.
However, with the advancement of network technologies, there's been a shift back to remote storage. Content indexing and data storage are increasingly handled by remote machines, overseen by orchestrator machines that execute calls to these storage systems. This shift, occurring over recent years, highlights a significant evolution in data storage and indexing approaches. Despite these advancements, the industry continues to face challenges, particularly around real-time indexing.
Step 2: Filtering
Overview: The filtering stage in recommendation systems aims to sift out invalid inventory from the pool of potential candidates. This process is not focused on personalization but rather on excluding items that are inherently unsuitable for consideration.
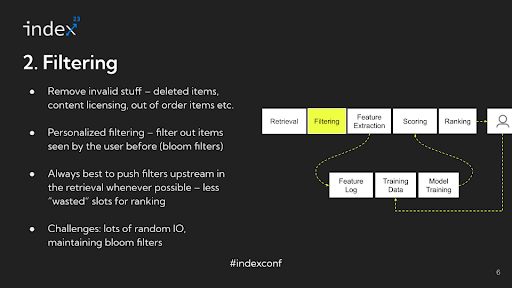
Detailed Analysis: To better understand the filtering process, consider specific examples across different platforms. In e-commerce, an out-of-stock item should not be displayed. On social media platforms, any content that has been deleted since its last indexing must be removed from the pool. For media streaming services, videos lacking licensing rights in certain regions should be excluded. Typically, this stage might involve applying around 13 different filtering rules to each of the 3,000 candidates, a process that requires significant I/O, often random disk I/O, presenting a challenge in terms of efficient management.
A key aspect of this process is personalized filtering, often using Bloom filters. For example, on platforms like TikTok, users are not shown videos they've already seen. This involves continuously updating Bloom filters with user interactions to filter out previously viewed content. As user interactions increase, so does the complexity of managing these filters.
Infrastructure Challenges: The primary infrastructure challenge lies in managing the size and efficiency of Bloom filters. They must be kept in memory for speed but can grow large over time, posing risks of data loss and management difficulties. Despite these challenges, the filtering stage, particularly after identifying valid candidates and removing invalid ones, is typically seen as one of the more manageable aspects of recommendation system processes.
Step 3: Feature extraction
After identifying suitable candidates and filtering out invalid inventory, the next critical stage in a recommendation system is feature extraction. This phase involves a thorough understanding of all the features and signals that will be utilized for ranking purposes. These features and signals are vital in determining the prioritization and presentation of content to the user within the recommendation feed. This stage is crucial in ensuring that the most pertinent and suitable content is elevated in ranking, thereby significantly enhancing the user's experience with the system.
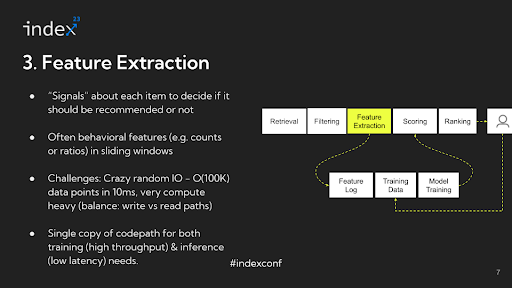
Detailed analysis: In the feature extraction stage, the extracted features are typically behavioral, reflecting user interactions and preferences. A common example is the number of times a user has viewed, clicked on, or purchased something, factoring in specific attributes such as the content's author, topic, or category within a certain timeframe.
For instance, a typical feature might be the frequency of a user clicking on videos created by female publishers aged 18 to 24 over the past 14 days. This feature not only captures the content's attributes, like the age and gender of the publisher, but also the user's interactions within a defined period. Sophisticated recommendation systems might employ hundreds or even thousands of such features, each contributing to a more nuanced and personalized user experience.
Infrastructure challenges: The feature extraction stage is considered the most challenging from an infrastructure perspective in a recommendation system. The primary reason for this is the extensive data I/O (Input/Output) operations involved. For instance, suppose you have thousands of candidates after filtering and thousands of features in the system. This results in a matrix with potentially millions of data points. Each of these data points involves looking up pre-computed quantities, such as how many times a specific event has occurred for a particular combination. This process is mostly random access, and the data points need to be continually updated to reflect the latest events.
For example, if a user watches a video, the system needs to update several counters relevant to that interaction. This requirement leads to a storage system that must support very high write throughput and even higher read throughput. Moreover, the system is latency-bound, often needing to process these millions of data points within tens of milliseconds..
Additionally, this stage requires significant computational power. Some of this computation occurs during the data ingestion (write) path, and some during the data retrieval (read) path. In most recommendation systems, the bulk of the computational resources is split between feature extraction and model serving. Model inference is another critical area that consumes a considerable amount of compute resources. This interplay of high data throughput and computational demands makes the feature extraction stage particularly intensive in recommendation systems.
There are even deeper challenges associated with feature extraction and processing, particularly related to balancing latency and throughput requirements. While the need for low latency is paramount during the live serving of recommendations, the same code path used for feature extraction must also handle batch processing for training models with millions of examples. In this scenario, the problem becomes throughput-bound and less sensitive to latency, contrasting with the real-time serving requirements.
To address this dichotomy, the typical approach involves adapting the same code for different purposes. The code is compiled or configured in one way for batch processing, optimizing for throughput, and in another way for real-time serving, optimizing for low latency. Achieving this dual optimization can be very challenging due to the differing requirements of these two modes of operation.
Step 4: Scoring
Once you have identified all the signals for all the candidates you somehow have to combine them and convert them into a single number, this is called scoring.
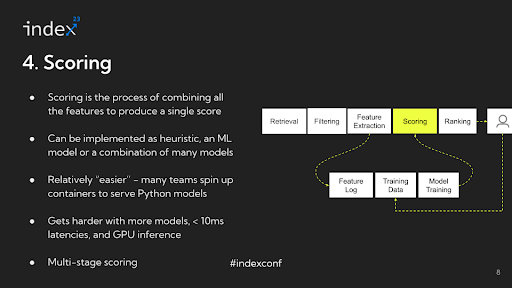
Detailed analysis: In the process of scoring for recommendation systems, the methodology can vary significantly depending on the application. For example, the score for the first item might be 0.7, for the second item 3.1, and for the third item -0.1. The way scoring is implemented can range from simple heuristics to complex machine learning models.
An illustrative example is the evolution of the feed at Quora. Initially, the Quora feed was chronologically sorted, meaning the scoring was as simple as using the timestamp of content creation. In this case, no complex steps were needed, and items were sorted in descending order based on the time they were created. Later, the Quora feed evolved to use a ratio of upvotes to downvotes, with some modifications, as its scoring function.
This example highlights that scoring does not always involve machine learning. However, in more mature or sophisticated settings, scoring often comes from machine learning models, sometimes even a combination of several models. It's common to use a diverse set of machine learning models, possibly half a dozen to a dozen, each contributing to the final scoring in different ways. This diversity in scoring methods allows for a more nuanced and tailored approach to ranking content in recommendation systems.
Infrastructure challenges: The infrastructure aspect of scoring in recommendation systems has significantly evolved, becoming much easier compared to what it was 5 to 6 years ago. Previously a major challenge, the scoring process has been simplified with advancements in technology and methodology. Nowadays, a common approach is to use a Python-based model, like XGBoost, spun up inside a container and hosted as a service behind FastAPI. This method is straightforward and sufficiently effective for most applications.
However, the scenario becomes more complex when dealing with multiple models, tighter latency requirements, or deep learning tasks that require GPU inference. Another interesting aspect is the multi-staged nature of ranking in recommendation systems. Different stages often require different models. For instance, in the earlier stages of the process, where there are more candidates to consider, lighter models are typically used. As the process narrows down to a smaller set of candidates, say around 200, more computationally expensive models are employed. Managing these varying requirements and balancing the trade-offs between different types of models, especially in terms of computational intensity and latency, becomes a crucial aspect of the recommendation system infrastructure.
Step 5: Ranking
Following the computation of scores, the final step in the recommendation system is what can be described as ordering or sorting the items. While often referred to as 'ranking', this stage might be more accurately termed 'ordering', as it primarily involves sorting the items based on their computed scores.
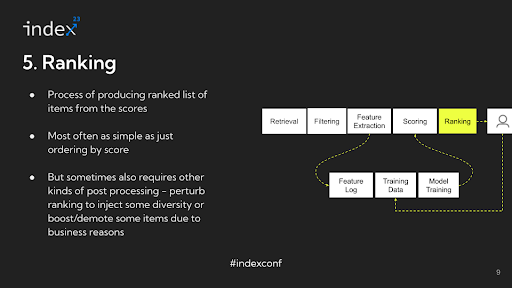
Detailed analysis: This sorting process is straightforward — typically just arranging the items in descending order of their scores. There's no additional complex processing involved at this stage; it's simply about organizing the items in a sequence that reflects their relevance or importance as determined by their scores. In sophisticated recommendation systems, there's more complexity involved beyond just ordering items based on scores. For example, suppose a user on TikTok sees videos from the same creator one after another. In that case, it might lead to a less enjoyable experience, even if those videos are individually relevant. To address this, these systems often adjust or 'perturb' the scores to enhance aspects like diversity in the user's feed. This perturbation is part of a post-processing stage where the initial sorting based on scores is modified to maintain other desirable qualities, like variety or freshness, in the recommendations. After this ordering and adjustment process, the results are presented to the user.
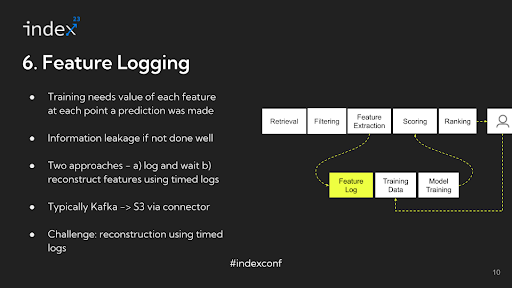
Step 6: Feature logging
When extracting features for training a model in a recommendation system, it's crucial to log the data accurately. The numbers that are extracted during feature extraction are typically logged in systems like Apache Kafka. This logging step is vital for the model training process that occurs later.
For instance, if you plan to train your model 15 days after data collection, you need the data to reflect the state of user interactions at the time of inference, not at the time of training. In other words, if you're analyzing the number of impressions a user had on a particular video, you need to know this number as it was when the recommendation was made, not as it is 15 days later. This approach ensures that the training data accurately represents the user's experience and interactions at the relevant moment.
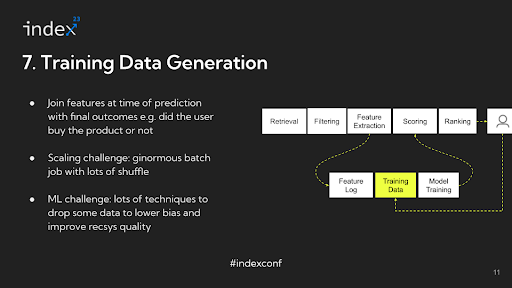
Step 7: Training Data
To facilitate this, a common practice is to log all the extracted data, freeze it in its current state, and then perform joins on this data at a later time when preparing it for model training. This method allows for an accurate reconstruction of the user's interaction state at the time of each inference, providing a reliable basis for training the recommendation model.
For instance, Airbnb might need to consider a year's worth of data due to seasonality factors, unlike a platform like Facebook which might look at a shorter window. This necessitates maintaining extensive logs, which can be challenging and slow down feature development. In such scenarios, features might be reconstructed by traversing a log of raw events at the time of training data generation.
The process of generating training data involves a massive join operation at scale, combining the logged features with actual user actions like clicks or views. This step can be data-intensive and requires efficient handling to manage the data shuffle involved.
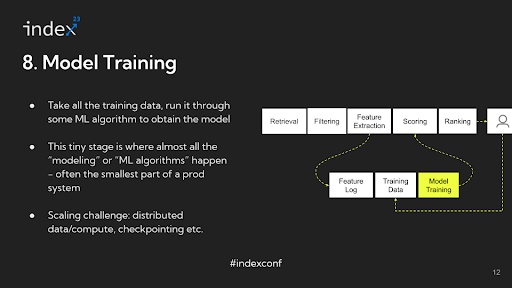
Step 8: Model Training
Finally, once the training data is prepared, the model is trained, and its output is then used for scoring in the recommendation system. Interestingly, in the entire pipeline of a recommendation system, the actual machine learning model training might only constitute a small portion of an ML engineer's time, with the majority spent on handling data and infrastructure-related tasks.
Infrastructure challenges: For larger-scale operations where there is a significant amount of data, distributed training becomes necessary. In some cases, the models are so large – literally terabytes in size – that they cannot fit into the RAM of a single machine. This necessitates a distributed approach, like using a parameter server to manage different segments of the model across multiple machines.
Another critical aspect in such scenarios is checkpointing. Given that training these large models can take extensive periods, sometimes up to 24 hours or more, the risk of job failures must be mitigated. If a job fails, it's important to resume from the last checkpoint rather than starting over from scratch. Implementing effective checkpointing strategies is essential to manage these risks and ensure efficient use of computational resources.
However, these infrastructure and scaling challenges are more relevant for large-scale operations like those at Facebook, Pinterest, or Airbnb. In smaller-scale settings, where the data and model complexity are relatively modest, the entire system might fit on a single machine ('single box'). In such cases, the infrastructure demands are significantly less daunting, and the complexities of distributed training and checkpointing may not apply.
Overall, this delineation highlights the varying infrastructure requirements and challenges in building recommendation systems, dependent on the scale and complexity of the operation. The 'blueprint' for constructing these systems, therefore, needs to be adaptable to these differing scales and complexities.
Special Cases of Recommendation System Blueprint
In the context of recommendation systems, various approaches can be taken, each fitting into a broader blueprint but with certain stages either omitted or simplified.

Let's look at a few examples to illustrate this:
Chronological Sorting: In a very basic recommendation system, the content might be sorted chronologically. This approach involves minimal complexity, as there's essentially no retrieval or feature extraction stage beyond using the time at which the content was created. The scoring in this case is simply the timestamp, and the sorting is based on this single feature.
Handcrafted Features with Weighted Averages: Another approach involves some retrieval and the use of a limited set of handcrafted features, maybe around 10. Instead of using a machine learning model for scoring, a weighted average calculated through a hand-tuned formula is used. This method represents an early stage in the evolution of ranking systems.
Sorting Based on Popularity: A more specific approach focuses on the most popular content. This could involve a single generator, likely an offline pipeline, that computes the most popular content based on metrics like the number of likes or upvotes. The sorting is then based on these popularity metrics.
Online Collaborative Filtering: Previously considered state-of-the-art, online collaborative filtering involves a single generator that performs an embedding lookup on a trained model. In this case, there's no separate feature extraction or scoring stage; it's all about retrieval based on model-generated embeddings.
Batch Collaborative Filtering: Similar to online collaborative filtering, batch collaborative filtering uses the same approach but in a batch processing context.
These examples illustrate that regardless of the specific architecture or approach of a ranking recommendation system, they are all variations of a fundamental blueprint. In simpler systems, certain stages like feature extraction and scoring may be omitted or greatly simplified. As systems grow more sophisticated, they tend to incorporate more stages of the blueprint, eventually filling out the entire template of a complex recommendation system.
Bonus Section: Storage considerations
Although we have completed our blueprint, along with the special cases for it, storage considerations still form an important part of any modern recommendation system. So, it's worthwhile to pay some attention to this bit.

In recommendation systems, Key-Value (KV) stores play a pivotal role, especially in feature serving. These stores are characterized by extremely high write throughput. For instance, on platforms like Facebook, TikTok, or Quora, thousands of writes can occur in response to user interactions, indicating a system with a high write throughput. Even more demanding is the read throughput. For a single user request, features for potentially thousands of candidates are extracted, even though only a fraction of these candidates will be shown to the user. This results in the read throughput being magnitudes larger than the write throughput, often 100 times more. Achieving single-digit millisecond latency (P99) under such conditions is a challenging task.
The writes in these systems are typically read-modify writes, which are more complex than simple appends. At smaller scales, it's feasible to keep everything in RAM using solutions like Redis or in-memory dictionaries, but this can be costly. As scale and cost increase, data needs to be stored on disk. Log-Structured Merge-tree (LSM) databases are commonly used for their ability to sustain high write throughput while providing low-latency lookups. RocksDB, for example, was initially used in Facebook's feed and is a popular choice in such applications. Fennel uses RocksDB for the storage and serving of feature data. Rockset, a search and analytics database, also uses RocksDB as its underlying storage engine. Other LSM database variants like ScyllaDB are also gaining popularity.
As the amount of data being produced continues to grow, even disk storage is becoming costly. This has led to the adoption of S3 tiering as a must-have solution for managing the sheer volume of data in petabytes or more. S3 tiering also facilitates the separation of write and read CPUs, ensuring that ingestion and compaction processes do not use up CPU resources needed for serving online queries. In addition, systems have to manage periodic backups and snapshots, and ensure exact-once processing for stream processing, further complicating the storage requirements. Local state management, often using solutions like RocksDB, becomes increasingly challenging as the scale and complexity of these systems grow, presenting numerous intriguing storage problems for those delving deeper into this space.
What does the future hold for the recommendation systems?
In discussing the future of recommendation systems, Nikhil highlights two significant emerging trends that are converging to create a transformative impact on the industry.

Extremely Large Deep Learning Models: There's a trend towards using deep learning models that are incredibly large, with parameter spaces in the range of terabytes. These models are so extensive that they cannot fit in the RAM of a single machine and are impractical to store on disk. Training and serving such massive models present considerable challenges. Manual sharding of these models across GPU cards and other complex techniques are currently being explored to manage them. Although these approaches are still evolving, and the field is largely uncharted, libraries like PyTorch are developing tools to assist with these challenges.
Real-Time Recommendation Systems: The industry is shifting away from batch-processed recommendation systems to real-time systems. This shift is driven by the realization that real-time processing leads to significant improvements in key production metrics such as user engagement and gross merchandise value (GMV) for e-commerce platforms. Real-time systems are not only more effective in enhancing user experience but are also easier to manage and debug compared to batch-processed systems. They tend to be more cost-effective in the long run, as computations are performed on-demand rather than pre-computing recommendations for every user, many of whom may not even engage with the platform daily.
A notable example of the intersection of these trends is TikTok's approach, where they have developed a system that combines the use of very large embedding models with real-time processing. From the moment a user watches a video, the system updates the embeddings and serves recommendations in real-time. This approach exemplifies the innovative directions in which recommendation systems are heading, leveraging both the power of large-scale deep learning models and the immediacy of real-time data processing.
These developments suggest a future where recommendation systems are not only more accurate and responsive to user behavior but also more complex in terms of the technological infrastructure required to support them. This intersection of large model capabilities and real-time processing is poised to be a significant area of innovation and growth in the field.
Interested in exploring more?
- Explore Fennel's real-time feature store for machine learning
For an in-depth understanding of how a real-time feature store can enhance machine learning capabilities, consider exploring Fennel. Fennel offers innovative solutions tailored for modern recommendation systems. Visit Fennel or read Fennel Docs.
- Find out more about the Rockset search and analytics database
Learn how Rockset serves many recommendation use cases through its performance, real-time update capability, and vector search functionality. Read more about Rockset or try Rockset for free.