How to Implement CDC for MySQL and Postgres

November 9, 2021
There are multiple change data capture methods available when using a MySQL or Postgres database. Some of these methods overlap and are very similar regardless of which database technology you are using, others are different. Ultimately, we require a way to specify and detect what has changed and a method of sending those changes to a target system.
This post assumes you are familiar with change data capture, if not read the previous introductory post here “Change Data Capture: What It Is and How To Use It.” In this post, we’re going to dive deeper into the different ways you can implement CDC if you have either a MySQL and Postgres database and compare the approaches.
CDC with Update Timestamps and Kafka
One of the simplest ways to implement a CDC solution in both MySQL and Postgres is by using update timestamps. Any time a record is inserted or modified, the update timestamp is updated to the current date and time and lets you know when that record was last changed.
We can then either build bespoke solutions to poll the database for any new records and write them to a target system or a CSV file to be processed later. Or we can use a pre-built solution like Kafka and Kafka Connect that has pre-defined connectors that poll tables and publish rows to a queue when the update timestamp is greater than the last processed record. Kafka Connect also has connectors to target systems that can then write these records for you.
Fetching the Updates and Publishing them to the Target Database using Kafka
Kafka is an event streaming platform that follows a pub-sub model. Publishers send data to a queue and one or more consumers can then read messages from that queue. If we wanted to capture changes from a MySQL or Postgres database and send them to a data warehouse or analytics platform, we first need to set up a publisher to send the changes and then a consumer that could read the changes and apply them to our target system.
To simplify this process we can use Kafka Connect. Kafka Connect works as a middle man with pre-built connectors to both publish and consume data that can simply be configured with a config file.
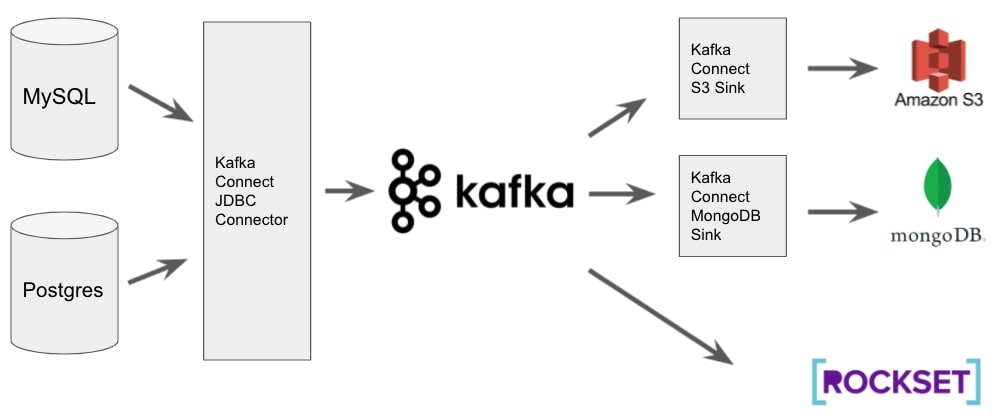
Fig 1. CDC architecture with MySQL, Postgres and Kafka
As shown in Fig 1, we can configure a JDBC connector for Kafka Connect that specifies which table we would like to consume, how to detect changes which in our case will be by using the update timestamp and which topic (queue) to publish them to. Using Kafka Connect to handle this means all of the logic required to detect which rows have changed is done for us. We only need to ensure that the update timestamp field is updated (covered in the next section) and Kafka Connect will take care of:
- Keeping track of the maximum update timestamp of the latest record it has published
- Polling the database for any records with newer update timestamp fields
- Writing the data to a queue to be consumed downstream
We can then either configure “sinks” which define where to output the data or have the source system talk to Kafka directly. Again, Kafka Connect has many pre-defined sink connectors that we can just configure to output the data to many different target systems. Services like Rockset can talk to Kafka directly and therefore do not require a sink to be configured.
Again, using Kafka Connect means that out of the box, not only can we write data to many different locations with very little coding required, but we also get Kafkas throughput and fault tolerance that will help us scale our solution in the future.
For this to work, we need to ensure that we have update timestamp fields on the tables we want to capture and that these fields are always updated whenever the record is updated. In the next section, we cover how to implement this in both MySQL and Postgres.
Using Triggers for Update Timestamps (MySQL & Postgres)
MySQL and Postgres both support triggers. Triggers allow you to perform actions in the database either immediately before or after another action happens. For this example, whenever an update command is detected to a row in our source table, we want to trigger another update on the affected row which sets the update timestamp to the current date and time.
We only want the trigger to run on an update command as in both MySQL and Postgres you can set the update timestamp column to automatically use the current date and time when a new record is inserted. The table definition in MySQL would look as follows (the Postgres syntax would be very similar). Note the DEFAULT CURRENTTIMESTAMP keywords when declaring the updatetimestamp column that ensures when a record is inserted, by default the current date and time are used.
CREATE TABLE user
(
id INT(6) UNSIGNED AUTO_INCREMENT PRIMARY KEY,
firstname VARCHAR(30) NOT NULL,
lastname VARCHAR(30) NOT NULL,
email VARCHAR(50),
update_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
This will mean our update_timestamp column gets set to the current date and time for any new records, now we need to define a trigger that will update this field whenever a record is updated in the user table. The MySQL implementation is simple and looks as follows.
DELIMITER $$
CREATE TRIGGER user_update_timestamp
BEFORE UPDATE ON user
FOR EACH ROW BEGIN
SET NEW.update_timestamp = CURRENT_TIMESTAMP;
END$$
DELIMITER ;
For Postgres, you first have to define a function that will set the update_timestamp field to the current timestamp and then the trigger will execute the function. This is a subtle difference but is slightly more overhead as you now have a function and a trigger to maintain in the postgres database.
Using Auto-Update Syntax in MySQL
If you are using MySQL there is another, much simpler way of implementing an update timestamp. When defining the table in MySQL you can define what value to set a column to when the record is updated, which in our case would be to update it to the current timestamp.
CREATE TABLE user
(
id INT(6) UNSIGNED AUTO_INCREMENT PRIMARY KEY,
firstname VARCHAR(30) NOT NULL,
lastname VARCHAR(30) NOT NULL,
email VARCHAR(50),
update_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
The benefit of this is that we no longer have to maintain the trigger code (or the function code in the case of Postgres).
CDC with Debezium, Kafka and Amazon DMS
Another option for implementing a CDC solution is by using the native database logs that both MySQL and Postgres can produce when configured to do so. These database logs record every operation that is executed against the database which can then be used to replicate these changes in a target system.
The advantage of using database logs is that firstly, you don’t need to write any code or add any extra logic to your tables as you do with update timestamps. Second, it also supports deletion of records, something that isn’t possible with update timestamps.
In MySQL you do this by turning on the binlog and in Postgres, you configure the Write Ahead Log (WAL) for replication. Once the database is configured to write these logs you can choose a CDC system to help capture the changes. Two popular options are Debezium and Amazon Database Migration Service (DMS). Both of these systems utilise the binlog for MySQL and WAL for Postgres.
Debezium works natively with Kafka. It picks up the relevant changes, converts them into a JSON object that contains a payload describing what has changed and the schema of the table and puts it on a Kafka topic. This payload contains all the context required to apply these changes to our target system, we just need to write a consumer or use a Kafka Connect sink to write the data. As Debezium uses Kafka, we get all the benefits of Kafka such as fault tolerance and scalability.
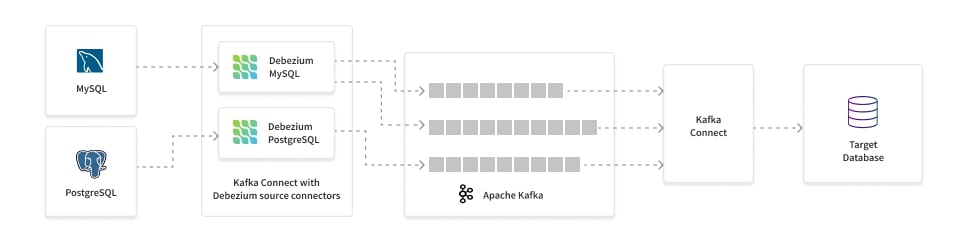
Fig 2. Debezium CDC architecture for MySQL and Postgres
AWS DMS works in a similar way to Debezium. It supports many different source and target systems and integrates natively with all of the popular AWS data services including Kinesis and Redshift.
The main benefit of using DMS over Debezium is that it's effectively a “serverless” offering. With Debezium, if you want the flexibility and fault tolerance of Kafka, you have the overhead of deploying a Kafka cluster. DMS as its name states is a service. You configure the source and target endpoints and AWS takes care of handling the infrastructure to deal with monitoring the database logs and copying the data to the target.
However, this serverless approach does have its drawbacks, mainly in its feature set.
Which Option for CDC?
When weighing up which pattern to follow it’s important to assess your specific use case. Using update timestamps works when you only want to capture inserts and updates, if you already have a Kafka cluster you can get up and running with this very quickly, especially if most tables already include some kind of update timestamp.
If you’d rather go with the database log approach, maybe because you want exact replication then you should look to use a service like Debezium or AWS DMS. I would suggest first checking which system supports the source and target systems you require. If you have some more advanced use cases such as masking sensitive data or re-routing data to different queues based on its content then Debezium is probably the best choice. If you’re just looking for simple replication with little overhead then DMS will work for you if it supports your source and target system.
If you have real-time analytics needs, you may consider using a target database like Rockset as an analytics serving layer. Rockset integrates with MySQL and Postgres, using AWS DMS, to ingest CDC streams and index the data for sub-second analytics at scale. Rockset can also read CDC streams from NoSQL databases, such as MongoDB and Amazon DynamoDB.
The right answer depends on your specific use case and there are many more options than have been discussed here, these are just some of the more popular ways to implement a modern CDC system.
Lewis Gavin has been a data engineer for five years and has also been blogging about skills within the Data community for four years on a personal blog and Medium. During his computer science degree, he worked for the Airbus Helicopter team in Munich enhancing simulator software for military helicopters. He then went on to work for Capgemini where he helped the UK government move into the world of Big Data. He is currently using this experience to help transform the data landscape at easyfundraising.org.uk, an online charity cashback site, where he is helping to shape their data warehousing and reporting capability from the ground up.