Comparing ClickHouse vs Rockset for Event and CDC Streams

October 4, 2022
Streaming data feeds many real-time analytics applications, from logistics tracking to real-time personalization. Event streams, such as clickstreams, IoT data and other time series data, are common sources of data into these apps. The broad adoption of Apache Kafka has helped make these event streams more accessible. Change data capture (CDC) streams from OLTP databases, which may provide sales, demographic or inventory data, are another valuable source of data for real-time analytics use cases. In this post, we compare two options for real-time analytics on event and CDC streams: Rockset and ClickHouse.
Architecture
ClickHouse was developed, beginning in 2008, to handle web analytics use cases at Yandex in Russia. The software was subsequently open sourced in 2016. Rockset was started in 2016 to meet the needs of developers building real-time data applications. Rockset leverages RocksDB, a high-performance key-value store, started as an open-source project at Facebook around 2010 and based on earlier work done at Google. RocksDB is used as a storage engine for databases like Apache Cassandra, CockroachDB. Flink, Kafka and MySQL.
As real-time analytics databases, Rockset and ClickHouse are built for low-latency analytics on large data sets. They possess distributed architectures that allow for scalability to handle performance or data volume requirements. ClickHouse clusters tend to scale up, using smaller numbers of large nodes, whereas Rockset is a serverless, scale-out database. Both offer SQL support and are capable of ingesting streaming data from Kafka.
Storage Format
While Rockset and ClickHouse are both designed for analytic applications, there are significant differences in their approaches. The ClickHouse name derives from “Clickstream Data Warehouse” and it was built with data warehouses in mind, so it is unsurprising that ClickHouse borrows many of the same ideas—column orientation, heavy compression and immutable storage—in its implementation. Column orientation is known to be a better storage format for OLAP workloads, like large-scale aggregations, and is at the core of ClickHouse’s performance.
The foundational idea in Rockset, in contrast, is the indexing of data for fast analytics. Rockset builds a Converged Index™ that has characteristics of multiple types of indexes—row, columnar and inverted—on all fields. Unlike ClickHouse, Rockset is a mutable database.
Separation of Compute and Storage
Design for the cloud is another area where Rockset and ClickHouse diverge. ClickHouse is offered as software, which can be self-managed on-premises or on cloud infrastructure. Several vendors also offer cloud versions of ClickHouse. Rockset is designed solely for the cloud and is offered as a fully managed cloud service.
ClickHouse uses a shared-nothing architecture, where compute and storage are tightly coupled. This helps reduce contention and improve performance because each node in the cluster processes the data in its local storage. This is also a design that has been used by well-known data warehouses like Teradata and Vertica.
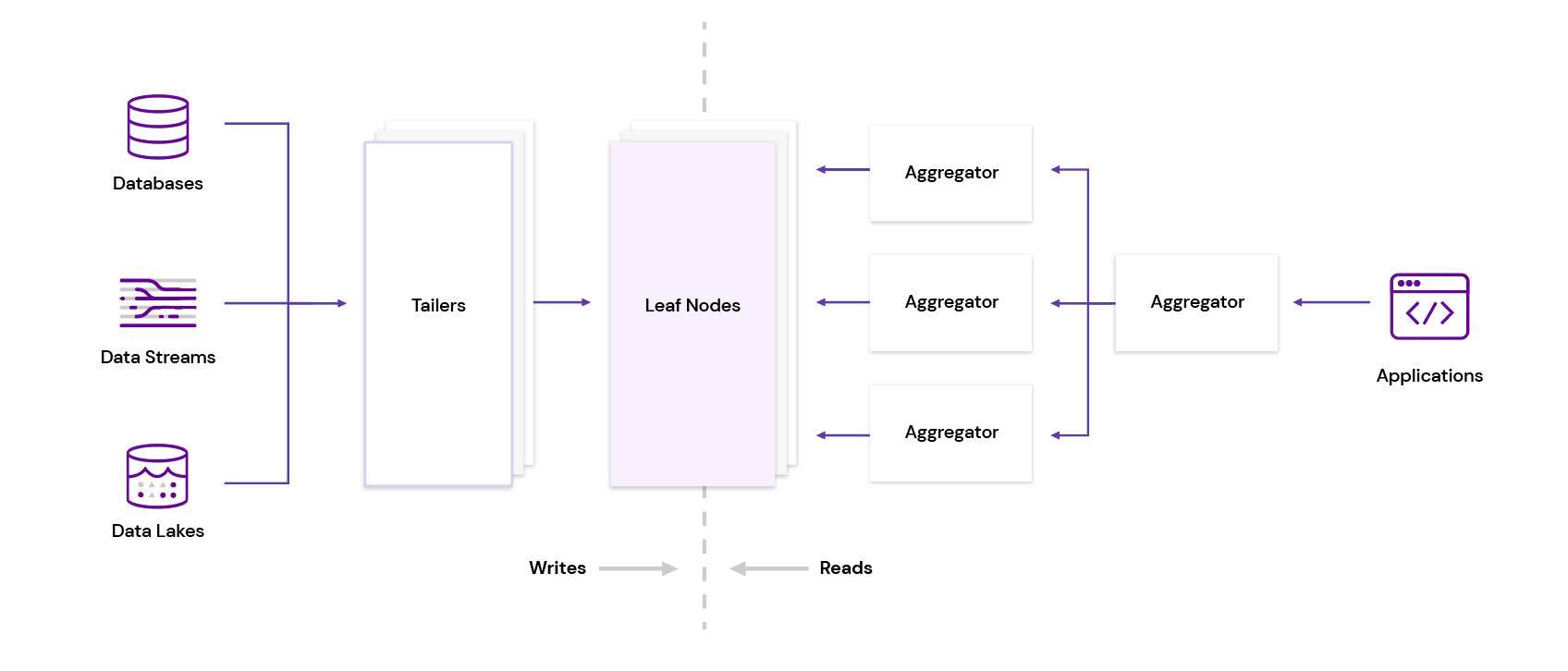
Rockset adopts an Aggregator-Leaf-Tailer (ALT) architecture, popularized by web companies like Facebook, LinkedIn and Google. Tailers fetch new data from data sources, Leaves index and store the data and Aggregators execute queries in distributed fashion. Not only does Rockset separate compute and storage, it also disaggregates ingest and query compute, so each tier in this architecture can be scaled independently.
In the following sections, we examine how some of these architectural differences impact the capabilities of Rockset and ClickHouse.
Data Ingestion
Streaming vs Batch Ingestion
While ClickHouse offers several ways to integrate with Kafka to ingest event streams, including a native connector, ClickHouse ingests data in batches. For a column store to handle high ingest rates, it needs to load data in sufficiently large batches in order to minimize overhead and maximize columnar compression. ClickHouse documentation recommends inserting data in packets of at least 1000 rows, or no more than a single request per second. This means users need to configure their streams to batch data ahead of loading into ClickHouse.
Rockset has native connectors that ingest event streams from Kafka and Kinesis and CDC streams from databases like MongoDB, DynamoDB, Postgres and MySQL. In all these cases, Rockset ingests on a per-record basis, without requiring batching, because Rockset is designed to make real-time data available as quickly as possible. In the case of streaming ingest, it generally takes 1-2 seconds from when data is produced to when it is queryable in Rockset.
Data Model
In most cases, ClickHouse will require users to specify a schema for any table they create. To help make this easier, ClickHouse recently introduced greater ability to handle semi-structured data using the JSON Object type. This is coupled with the added capability to infer the schema from the JSON, using a subset of the total rows in the table. Dynamically inferred columns have some limitations, such as the inability to be used as primary or sort keys, so users will still need to configure some level of explicit schema definition for optimal performance.
Rockset will perform schemaless ingestion for all incoming data, and will accept fields with mixed types, nested objects and arrays, sparse fields and null values without the user having to perform any manual specification. Rockset automatically generates the schema based on the exact fields and types present in the collection, not on a subset of the data.
ClickHouse data is usually denormalized so as to avoid having to do JOINs, and users have commented that the data preparation needed to do so can be difficult. In contrast, there is no recommendation to denormalize data in Rockset, as Rockset can handle JOINs well.
Updates and Deletes
As mentioned briefly in the Architecture section, ClickHouse writes data to immutable files, called “parts.” While this design helps ClickHouse achieve faster reads and writes, it does so at the cost of update performance.
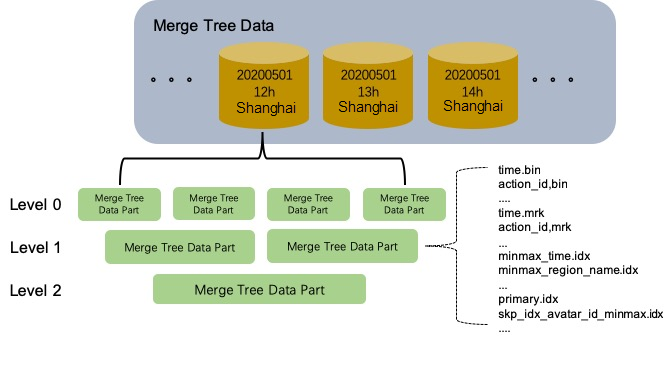
ClickHouse supports update and delete operations, which it refers to as mutations. They do not directly update or delete the data but instead rewrite and merge the data parts asynchronously. Any queries that run while an asynchronous mutation is in progress could get a mix of data from mutated and non-mutated parts.
In addition, these mutations can get expensive, as even small changes will cause large rewrites of entire parts. ClickHouse documentation states that these are heavy operations and do not advise that they be used frequently. For this reason, database CDC streams, which often contain updates and deletes, are handled less efficiently by ClickHouse.
In contrast, all documents stored in a Rockset collection are mutable and can be updated at the field level, even if these fields are deeply nested inside arrays and objects. Only the fields in a document that are part of an update request need to be reindexed, while the rest of the fields in the document remain untouched.
Rockset uses RocksDB, a high-performance key-value store that makes mutations trivial. RocksDB supports atomic writes and deletes across different keys. Due to its design, Rockset is one of the few real-time analytics databases that can efficiently ingest from database CDC streams.
Ingest Transformations and Rollups
It is useful to be able to transform and rollup streaming data as it is being ingested. ClickHouse has several storage engines that can pre-aggregate data. The SummingMergeTree sums rows that correspond to the same primary key and stores the result as a single row. The AggregatingMergeTree is similar and applies aggregate functions to rows with the same primary key to produce a single row as its result.
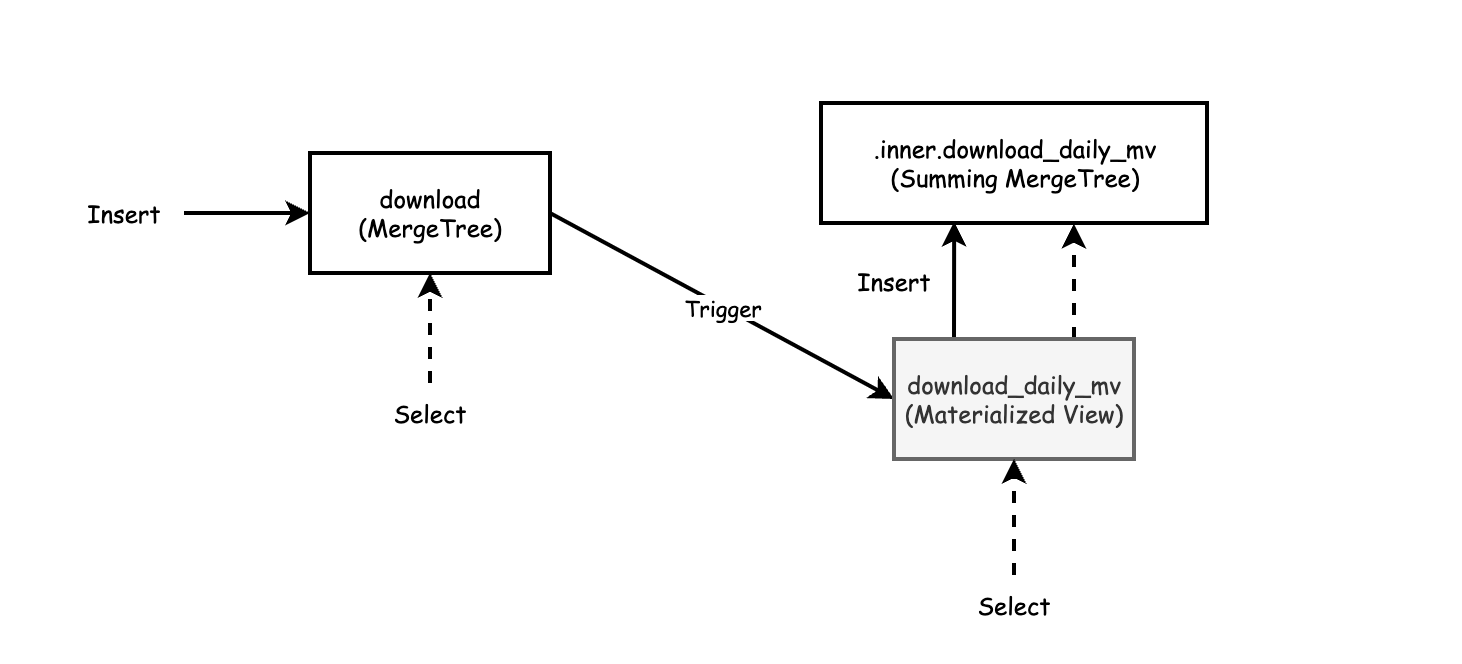
Rockset supports SQL transformations that apply to all documents at the point of ingestion. Users have the ability to specify many more types of transformations through the use of SQL. Common uses for ingest transformation include dropping fields, field masking and hashing, and type coercion.
Rollups in Rockset are a special type of transformation that aggregates data upon ingest. Using rollups reduces storage size and improves query performance because only the aggregated data is stored and queried.
Queries and Performance
Indexing
ClickHouse’s performance stems primarily from storage optimizations such as column orientation, aggressive compression and ordering of data by primary key. ClickHouse does use indexing to speed up queries as well, but in a more limited fashion as compared to its storage optimizations.
Primary indexes in ClickHouse are sparse indexes. They do not index every row but instead have one index entry per group of rows. Instead of returning single rows that match the query, the sparse index is used to locate groups of rows that are possible matches.
Similarly, ClickHouse utilizes secondary indexes, known as data skipping indexes, to enable ClickHouse to skip reading blocks that will not match the query. ClickHouse then scans through the reduced data set to complete executing the query.
Rockset optimizes for compute efficiency, so indexing is the main driver behind its query speed. Rockset’s Converged Index combines a row index, columnar index and inverted index. This allows Rockset’s SQL engine to use indexing optimally to accelerate various kinds of analytical queries, from highly selective queries to large-scale aggregations. The Converged Index is also a covering index, meaning all queries can be resolved solely through the index, without any additional lookup.
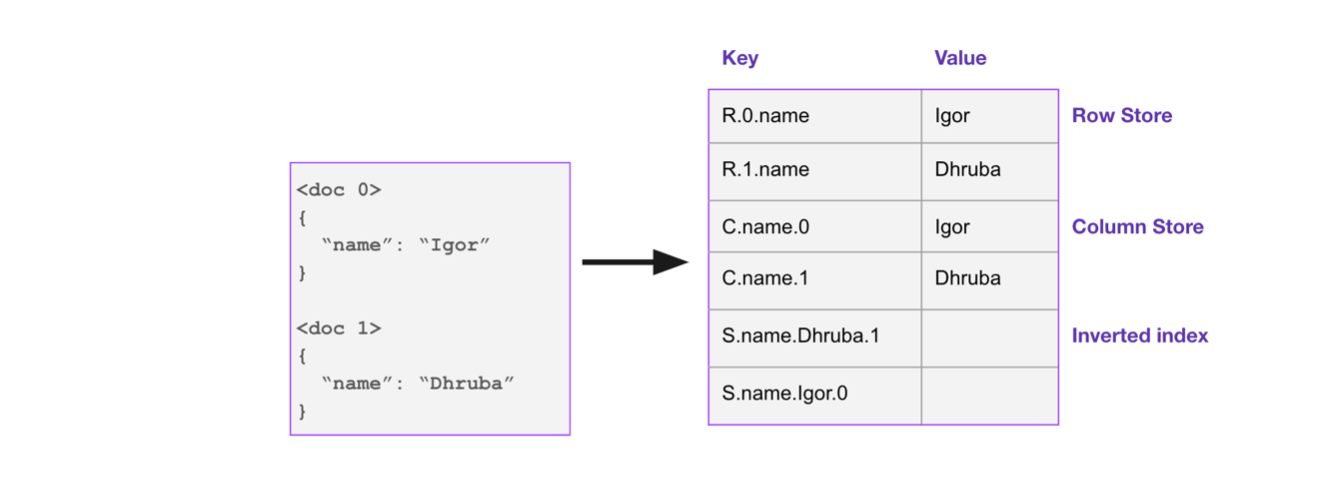
There is a big difference in how indexing is managed in ClickHouse and Rockset. In ClickHouse, the onus is on the user to understand what indexes are needed in order to configure primary and secondary indexes. Rockset, by default, indexes all the data that is ingested in the different ways provided by the Converged Index.
Joins
While ClickHouse supports JOIN functionality, many users report performance challenges with JOINs, particularly on large tables. ClickHouse does not have the ability to optimize these JOINs effectively, so alternatives, like denormalizing data beforehand to avoid JOINs, are recommended.
In supporting full-featured SQL, Rockset was designed with JOIN performance in mind. Rockset partitions the JOINs, and these partitions run in parallel on distributed Aggregators that can be scaled out if needed. It also has multiple ways of performing JOINs:
- Hash Join
- Nested loop Join
- Broadcast Join
- Lookup Join
The ability to JOIN data in Rockset is particularly useful when analyzing data across different database systems and live data streams. Rockset can be used, for example, to JOIN a Kafka stream with dimension tables from MySQL. In many situations, pre-joining the data is not an option because data freshness is important or the ability to perform ad hoc queries is required.
Operations
Cluster Management
ClickHouse clusters can be run in self-managed mode or through a company that commercializes ClickHouse as a cloud service. In a self-managed cluster, ClickHouse users will need to install and configure the ClickHouse software as well as required services like ZooKeeper or ClickHouse Keeper. The cloud version will help remove some of the hardware and software provisioning burden, but users still need to configure nodes, shards, software versions, replication and so on. Users need to intervene to upgrade the cluster, during which they may experience downtime or performance degradation.
In contrast, Rockset is fully managed and serverless. The concept of clusters and servers is abstracted away, so no provisioning is needed and users do not have to manage any infrastructure themselves. Software upgrades happen in the background, so users can easily take advantage of the latest version of software.
Scaling and Rebalancing
While it is fairly straightforward to get started with the single-node version of ClickHouse, scaling the cluster to meet performance and storage needs takes some effort. For instance, setting up distributed ClickHouse involves creating a shard table on each individual server and then defining the distributed view via another create command.
As discussed in the Architecture overview, compute and storage are bound to each other in ClickHouse nodes and clusters. Users need to scale both compute and storage in fixed ratios and lack the flexibility to scale resources independently. This can result in resource utilization that is suboptimal, where either compute or storage is overprovisioned.
The tight coupling of compute and storage also gives rise to situations where imbalances or hotspots can occur. A common scenario arises when adding nodes to a ClickHouse cluster, which requires rebalancing of data to populate the newly added nodes. ClickHouse documentation calls out that ClickHouse clusters are not elastic because they do not support automatic shard rebalancing. Instead, rebalancing is a highly involved process that can include manually weighting writes to bias where new data is written, manual relocation of existing data partitions, or even copying and exporting data to a new cluster.
Another side effect of the lack of compute-storage separation is that a large number of small queries can affect the entire cluster. ClickHouse recommends bi-level sharding to limit the impact of these small queries.
Scaling in Rockset involves less effort because of its separation of compute and storage. Storage autoscales as data size grows, while compute can be scaled by specifying the Virtual Instance size, which governs the total compute and memory resources available in the system. Users can scale resources independently for more efficient resource utilization. No rebalancing is needed as Rockset’s compute nodes access data from its shared storage.
Replication
Due to ClickHouse’s shared-nothing architecture, replicas serve a dual purpose: availability and durability. While replicas have the potential to help with query performance, they are essential to guard against the loss of data, so ClickHouse users must incur the additional cost for replication. Configuring replication in ClickHouse also involves deploying ZooKeeper or ClickHouse Keeper, ClickHouse’s version of the service, for coordination.
In Rockset’s cloud-native architecture, it uses cloud object storage to ensure durability without requiring additional replicas. Multiple replicas can aid query performance, but these can be brought online on demand, only when there is an active query request. By using cheaper cloud object storage for durability and only spinning up compute and fast storage for replicas when needed for performance, Rockset can provide better price-performance.
Summary
Rockset and ClickHouse are both real-time analytics options for streaming data, but they are designed quite differently under the hood. Their technical differences manifest themselves in the following ways.
- Efficiency of streaming writes and updates: ClickHouse discourages small, streaming writes and frequent updates as it is built on immutable columnar storage. Rockset, as a mutable database, handles streaming ingest, updates and deletes much more efficiently, making it suitable as a target for event and database CDC streams.
- Data and query flexibility: ClickHouse usually requires data to be denormalized because large-scale JOINs don’t perform well. Rockset operates on semi-structured data, without the need for schema definition or denormalization, and supports full-featured SQL including JOINs.
- Operations: Rockset was built for the cloud from day one, while ClickHouse is software that can be deployed on-premises or on cloud infrastructure. Rockset’s disaggregated cloud-native architecture minimizes the operational burden on the user and enables quick and easy scale out.
For these reasons, many organizations have opted to build on Rockset rather than invest in heavier data engineering to make other solutions work. If you would like to try Rockset for yourself, you can set up a new account and connect to a streaming source in minutes.