Introduction to Semantic Search: From Keyword to Vector Search

September 12, 2023
Google, eBay, and others have the ability to find “similar” images. Have you ever wondered how this works? This capability transcends what’s possible with ordinary keyword search and instead uses semantic search to return similar or related images. This blog will cover a brief history of semantic search, its use of vectors, and how it differs from keyword search.
Developing Understanding with Semantic Search
Traditional text search embodies a fundamental limitation: exact matching. All it can do is to check, at scale, whether a query matches some text. Higher-end engines skate around this problem with additional tricks like lemmatization and stemming, for example equivalently matching “send”, “sent”, or “sending”, but when a particular query expresses a concept with a different word than the corpus (the set of documents to be searched), queries fail and users get frustrated. To put it another way, the search engine has no understanding of the corpus.
Our brains just don’t work like search engines. We think in concepts and ideas. Over a lifetime we gradually assemble a mental model of the world, all the while constructing an internal landscape of thoughts, facts, notions, abstractions, and a web of connections among them. Since related concepts live “nearby” in this landscape, it’s effortless to recall something with a different-but-related word that still maps to the same concept.
While artificial intelligence research remains far from replicating human intelligence, it has produced useful insights that make it possible to perform search at a higher, or semantic level, matching concepts instead of keywords. Vectors, and vector search, are at the heart of this revolution.
From Keywords to Vectors
A typical data structure for text search is a reverse index, which works much like the index at the back of a printed book. For each relevant keyword, the index keeps a list of occurrences in particular documents from the corpus; then resolving a query involves manipulating these lists to compute a ranked list of matching documents.
In contrast, vector search uses a radically different way of representing items: vectors. Notice that the preceding sentence changed from talking about text to a more generic term, items. We’ll get back to that momentarily.
What’s a vector? Simply a list or array of numbers--think, java.util.Vector for example—but with emphasis on its mathematical properties. Among the useful properties of vectors, also known as embeddings, is that they form a space where semantically similar items are close to each other.
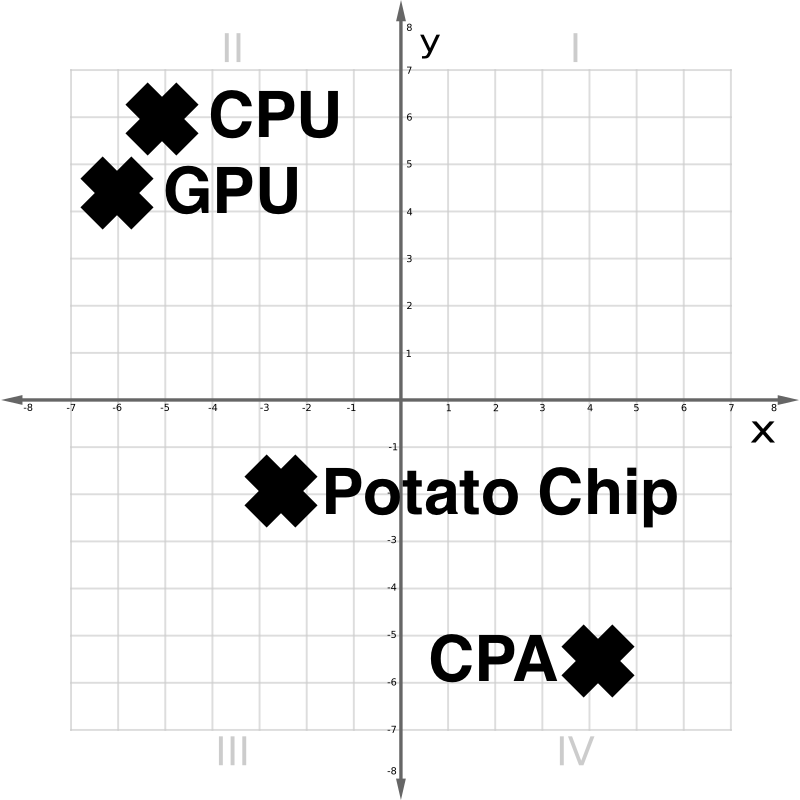
In the vector space in Figure 1 above, we see that a CPU and a GPU are conceptually close. A Potato Chip is distantly related. A CPA, or accountant, though lexically similar to a CPU, is quite different.
The full story of vectors requires a brief trip through a land of neural networks, embeddings, and thousands of dimensions.
Neural Networks and Embeddings
Articles abound describing the theory and operation of neural networks, which are loosely modeled on how biological neurons interconnect. This section will give a quick refresher. Schematically a neural net looks like Figure 2:
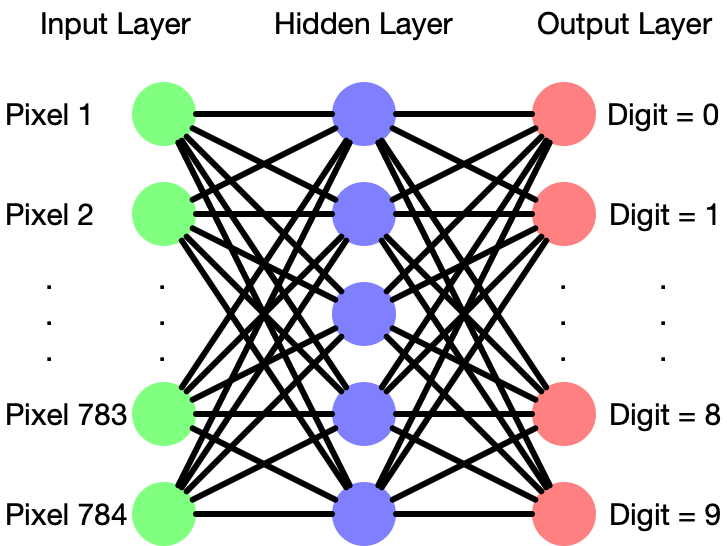
A neural network consists of layers of ‘neurons’ each of which accepts multiple inputs with weights, either additive or multiplicative, which it combines into an output signal. The configuration of layers in a neural network varies quite a bit between different applications, and crafting just the right “hyperparameters” for a neural net requires a skilled hand.
One rite of passage for machine learning students is to build a neural net to recognize handwritten digits from a dataset called MNIST, which has labeled images of handwritten digits, each 28x28 pixels. In this case, the leftmost layer would need 28x28=784 neurons, one receiving a brightness signal from each pixel. A middle “hidden layer” has a dense web of connections to the first layer. Usually neural nets have many hidden layers, but here there’s only one. In the MNIST example, the output layer would have 10 neurons, representing what the network “sees,” namely probabilities of digits 0-9.
Initially, the network is essentially random. Training the network involves repeatedly tweaking the weights to be a tiny bit more accurate. For example, a crisp image of an “8” should light up the #8 output at 1.0, leaving the other nine all at 0. To the extent this is not the case, this is considered an error, which can be mathematically quantified. With some clever math, it’s possible to work backward from the output, nudging weights to reduce the overall error in a process called backpropagation. Training a neural network is an optimization problem, finding a suitable needle in a vast haystack.
The pixel inputs and digit outputs all have obvious meaning. But after training, what do the hidden layers represent? This is a good question!
In the MNIST case, for some trained networks, a particular neuron or group of neurons in a hidden layer might represent a concept like perhaps “the input contains a vertical stroke” or “the input contains a closed loop”. Without any explicit guidance, the training process constructs an optimized model of its input space. Extracting this from the network yields an embedding.
Text Vectors, and More
What happens if we train a neural network on text?
One of the first projects to popularize word vectors is called word2vec. It trains a neural network with a hidden layer of between 100 and 1000 neurons, producing a word embedding.
In this embedding space, related words are close to each other. But even richer semantic relationships are expressible as yet more vectors. For example, the vector between the words KING and PRINCE is nearly the same as the vector between QUEEN and PRINCESS. Basic vector addition expresses semantic aspects of language that did not need to be explicitly taught.
Surprisingly, these techniques work not only on single words, but also for sentences or even whole paragraphs. Different languages will encode in a way that comparable words are close to each other in the embedding space.
Analogous techniques work on images, audio, video, analytics data, and anything else that a neural network can be trained on. Some “multimodal” embeddings allow, for example, images and text to share the same embedding space. A picture of a dog would end up close to the text “dog”. This feels like magic. Queries can be mapped to the embedding space, and nearby vectors—whether they represent text, data, or anything else–will map to relevant content.
Some Uses for Vector Search
Because of its shared ancestry with LLMs and neural networks, vector search is a natural fit in generative AI applications, often providing external retrieval for the AI. Some of the main uses for these kinds of use cases are:
- Adding ‘memory’ to a LLM beyond the limited context window size
- A chatbot that quickly finds the most relevant sections of documents in your corporate network, and hands them off to a LLM for summarization or as answers to Q&A. (This is called Retrieval Augmented Generation)
Additionally, vector search works great in areas where the search experience needs to work more closely to how we think, especially for grouping similar items, such as:
- Search across documents in multiple languages
- Finding visually similar images, or images similar to videos.
- Fraud or anomaly detection, for instance if a particular transaction/document/email produces an embedding that is farther away from a cluster of more typical examples.
- Hybrid search applications, using both traditional search engine technology as well as vector search to combine the strengths of each.
Meanwhile, traditional keyword based search still has its strengths, and remains useful for many apps, especially where a user knows exactly what they’re looking for, including structured data, linguistic analysis, legal discovery, and faceted or parametric search.
But this is only a small taste of what’s possible. Vector search is soaring in popularity, and powering more and more applications. How will your next project use vector search?
Continue your learning with part 2 of our Introduction to Semantic Search: -Embeddings, Similarity Metrics and Vector Databases.
Learn how Rockset supports vector search here.