Real-Time Data Transformations with dbt + Rockset

October 20, 2021
Until now, the majority of the world’s data transformations have been performed on top of data warehouses, query engines, and other databases which are optimized for storing lots of data and querying them for analytics occasionally. These solutions have worked well for the batch ELT world over the past decade, where data teams are used to dealing with data that is only occasionally refreshed and analytics queries that can take minutes or even hours to complete.
The world, however, is moving from batch to real-time, and data transformations are no exception.
Both data freshness and query latency requirements are becoming more and more strict, with modern data applications and operational analytics necessitating fresh data that never gets stale. With the speed and scale at which new data is constantly being generated in today’s real-time world, such analytics based on data that is days, hours, or even minutes old may no longer be useful. Comprehensive analytics require extremely robust data transformations, which is challenging and expensive to make real-time when your data is residing in technologies not optimized for real-time analytics.
Introducing dbt Core + Rockset
Back in July, we introduced our dbt-Rockset adapter for the first time which brought real-time analytics to dbt, an immensely popular open-source data transformation tool that lets teams quickly and collaboratively deploy analytics code to ship higher quality data sets. Using the adapter, you could now load data into Rockset and create collections by writing SQL SELECT statements in dbt. These collections could then be built on top of one another to support highly complex data transformations with many dependency edges.
Today, we’re excited to announce the first major update to our dbt-Rockset adapter which now supports all four core dbt materializations:
- View Materializations where dbt models are rebuilt on each run as views in Rockset
- Table Materializations where dbt models are rebuilt on each run as collections in Rockset
- Incremental Materializations where dbt inserts or updates records into Rockset collections since the last time that dbt was run
- Ephemeral Materializations where dbt interpolates Rockset SQL code from models as common table expressions
With this beta release, you can now perform all of the most popular workflows used in dbt for performing real-time data transformations on Rockset. This comes on the heels of our latest product releases around more accessible and affordable real-time analytics with Rollups on Streaming Data and Rockset Views.
Real-Time Streaming ELT Using dbt + Rockset
As data is ingested into Rockset, we will automatically index it using Rockset’s Converged Index™ technology, perform any write-time data transformations you define, and then make that data queryable within seconds. Then, when you execute queries on that data, we will leverage those indexes to complete any read-time data transformations you define using dbt with sub-second latency.
Let’s walk through an example workflow for setting up real-time streaming ELT using dbt + Rockset:
Write-Time Data Transformations Using Rollups and Field Mappings
Rockset can easily extract and load semi-structured data from multiple sources in real-time. For high velocity data, most commonly coming from data streams, you can roll it up at write-time. For instance, let’s say you have streaming data coming in from Kafka or Kinesis. You would create a Rockset collection for each data stream, and then set up SQL-Based Rollups to perform transformations and aggregations on the data as it is written into Rockset. This can be helpful when you want to reduce the size of large scale data streams, deduplicate data, or partition your data.
Collections can also be created from other data sources including data lakes (e.g. S3 or GCS), NoSQL databases (e.g. DynamoDB or MongoDB), and relational databases (e.g. PostgreSQL or MySQL). You can then use Rocket’s SQL-Based Field Mappings to transform the data using SQL statements as it is written into Rockset.
Read-Time Data Transformations Using Rockset Views
There is only so much complexity you can codify into your data transformations during write-time, so the next thing you’ll want to try is using the adapter to set up data transformations as SQL statements in dbt using the View Materialization that can be performed during read-time.
Create a dbt model using SQL statements for each transformation you want to perform on your data. When you execute dbt run, dbt will automatically create a Rockset View for each dbt model, which will perform all the data transformations when queries are executed.
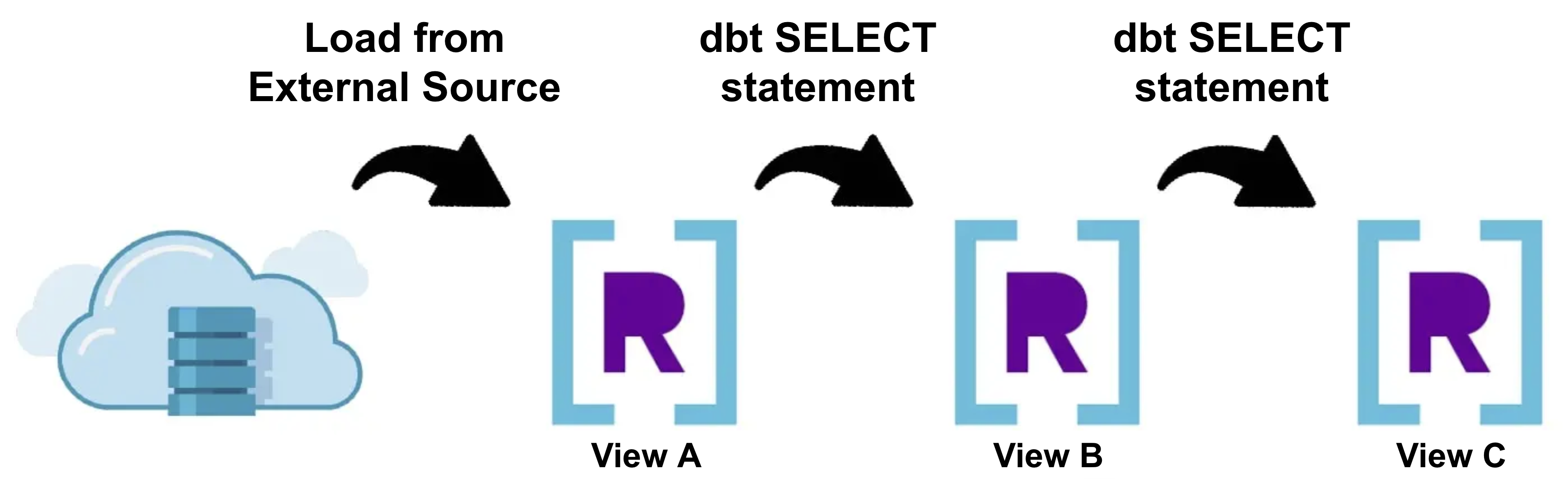
If you’re able to fit all of your transformation into the steps above and queries complete within your latency requirements, then you have achieved the gold standard of real-time data transformations: Real-Time Streaming ELT.
That is, your data will be automatically kept up-to-date in real-time, and your queries will always reflect the most up-to-date source data. There is no need for periodic batch updates to “refresh” your data. In dbt, this means that you will not need to execute dbt run again after the initial setup unless you want to make changes to the actual data transformation logic (e.g. adding or updating dbt models).
Persistent Materializations Using dbt + Rockset
If using only write-time transformations and views is not enough to meet your application’s latency requirements or your data transformations become too complex, you can persist them as Rockset collections. Keep in mind Rockset also requires queries to complete in under 2 minutes to cater to real-time use cases, which may affect you if your read-time transformations are too involuted. While this requires a batch ELT workflow since you would need to manually execute dbt run each time you want to update your data transformations, you can use micro-batching to run dbt extremely frequently to keep your transformed data up-to-date in near real-time.
The most important advantages to using persistent materializations is that they are both faster to query and better at handling query concurrency, as they are materialized as collections in Rockset. Since the bulk of the data transformations have already been performed ahead of time, your queries will complete significantly faster since you can minimize the complexity necessary during read-time.
There are two persistent materializations available in dbt: incremental and table.
Materializing dbt Incremental Models in Rockset
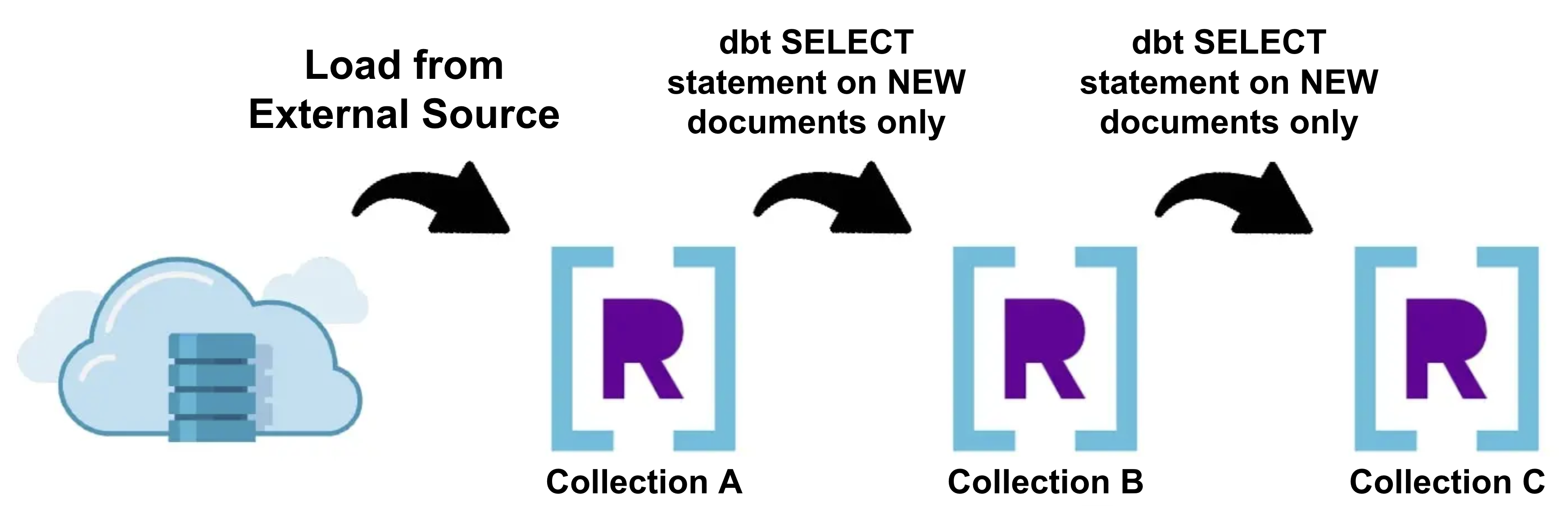
Incremental Models are an advanced concept in dbt which allow you to insert or update documents into a Rockset collection since the last time dbt was run. This can significantly reduce the build time since we only need to perform transformations on the new data that was just generated, rather than dropping, recreating, and performing transformations on the entirety of the data.
Depending on the complexity of your data transformations, incremental materializations may not always be a viable option to meet your transformation requirements. Incremental materializations are usually best suited for event or time-series data streamed directly into Rockset. To tell dbt which documents it should perform transformations on during an incremental run, simply provide SQL that filters for these documents using the is_incremental() macro in your dbt code. You can learn more about configuring incremental models in dbt here.
Materializing dbt Table Models in Rockset

Table Models in dbt are transformations which drop and recreate entire Rockset collections with each execution of dbt run in order to update that collection’s transformed data with the most up-to-date source data. This is the simplest way to persist transformed data in Rockset, and results in much faster queries since the transformations are completed prior to query time.
On the other hand, the biggest drawback to using table models is that they can be slow to complete since Rockset is not optimized for creating entirely new collections from scratch on the fly. This may cause your data latency to increase significantly as it may take several minutes for Rockset to provision resources for a new collection and then populate it with transformed data.
Putting It All Together

Keep in mind that with both table models and incremental models, you can always use them in conjunction with Rockset views to customize the perfect stack in order to meet the unique requirements of your data transformations. For example, you might use SQL-based rollups to first transform your streaming data during write-time, transform and persist them into Rockset collections via incremental or table models, and then execute a sequence of view models during read-time to transform your data again.
Beta Partner Program
The dbt-Rockset adapter is fully open-sourced, and we would love your input and feedback! If you’re interested in getting in touch with us, you can sign up here to join our beta partner program for the dbt-Rockset adapter, or find us at the dbt Slack community in the #db-rockset channel. We’re also hosting an office hours on October 26th at 10am PST where we’ll show a live demo of real-time transformations and answer any technical questions. Hope you can join us for the event!