Rollups on Streaming Data: Rockset vs Apache Druid

August 25, 2021
The world is moving from batch to real-time. With Confluent’s recent IPO, streaming data has officially gone mainstream, “becoming the underpinning of a modern digital customer experience, and the key to driving intelligent, efficient operations” to quote from their letter to shareholders. But while it’s easier to stream the data, analyzing it in real time still involves too much cost and complexity. Batch processes simply don’t cut it. Creating and maintaining real-time data pipelines is too hard, and even the most advanced cloud warehouses are too slow and expensive for real-time analytics.
Real-time analytics databases are built from the ground up for fast queries on fresh data, making real-time data pipelines easier, no matter the source. They are an essential part of the modern data stack for powering:
- Real-time search applications
- Social features in the product
- Recommendation/rewards features in the product
- Real-time dashboards
- IoT applications
These use cases can have several TBs per day streaming in - they are literally data torrents. It’s simply too expensive to store all the raw data and simply too slow to run batch processes to pre-aggregate it. One common example is a mobile app, where every activity is recorded as an event, resulting in millions of events per day streaming in. If you store every event, your storage footprint grows at an alarming rate and queries become prohibitively slow and expensive. Instead, if you can “rollup” data as it is being generated, then you can define metrics that can be tracked in real time across a number of dimensions with better performance and lower cost.
Rollups for More Cost-Effective Real-Time Analytics
To better serve these streaming data use cases, Rockset is introducing rollups, allowing users to aggregate data as it is ingested. This greatly reduces both the amount of data stored and the compute for queries.
Early users of rollups have experienced a 30-100x performance improvement while also reducing the cost of storage significantly. Depending upon the granularity of the rollups, storage needs can be reduced 5-150x.
With this release, Rockset users have the capability to continuously aggregate and transform data at the time of ingest, using SQL, from any data source (data streams, databases and data lakes). This is a first in the industry and frees users from managing slow, expensive ETL pipelines for their streaming data.
For example, consider a payment processor, who is processing millions of payments between thousands of merchants and millions of customers. They need to monitor all those transactions in real time and run advanced statistical models to look for anomalies and detect suspicious activity. These statistical models typically build a baseline based on aggregate data they get from a merchant. Storing the raw transaction data and recalculating the metrics for every transaction will be prohibitively expensive. Using Rockset's rollup functionality, the payment processor is able define all the merchant-specific aggregate metrics simply using SQL. Rockset will automatically maintain all those metrics for each merchant in real-time at a fraction of the cost, and those metrics will be accurate up to the last second. Since those metrics are pre-calculated and refreshed automatically, they can now implement real-time monitoring and anomaly detection to better secure their business.
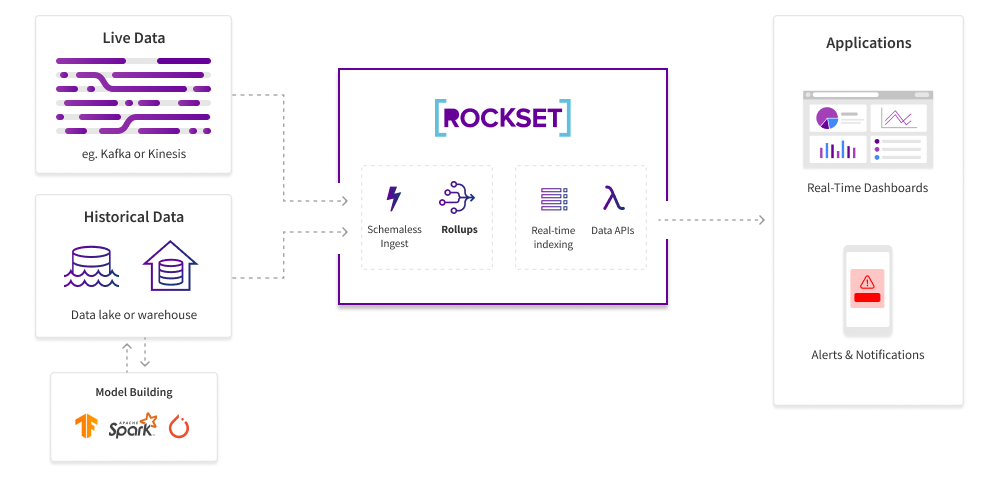 Figure 1: A sample architecture using rollups for streaming data
Figure 1: A sample architecture using rollups for streaming data
Continuous Rollups and Transformations on Any Data
Rockset supports rollups and transformations not just for streaming data but also for data from other sources, like databases and data lakes. Rockset can ingest all the data relevant for real-time applications, including transaction or inventory data from databases, and provide low-latency access to that data in a cost-effective way. Other real-time analytics systems, like Apache Druid, do not support OLTP databases as data sources.
Rollups and Transformations Using SQL
Users specify aggregations and transformations all in SQL, a familiar language to most developers. While Druid requires separate rollup and transform specs that can run into 100s of lines, users can do this more naturally with SQL in Rockset.
 Figure 2: An example rollup using SQL
Figure 2: An example rollup using SQL
Feature-Rich Aggregations
Rockset supports wider aggregation capabilities beyond simply time-based aggregations. Customers can aggregate data based on time, customer-id, location and any other criteria, which is not possible in Druid. This is extremely powerful for users creating new real-time features/functionalities in their product because they can use their data more flexibly.
An example rollup that is not time-based:
SELECT
SUM(fare_amount) AS total_fare_amount,
passenger_count,
payment_type
FROM _input
GROUP BY passenger_count, payment_type
Perfect Rollups for Streaming Data
Beyond supporting exactly-once semantics, Rockset guarantees perfect rollups for all sources, including streaming data sources. In contrast, Druid supports perfect rollup for batch data, like Hadoop, and only supports best-effort rollup for streaming data. Best-effort rollups lead to inconsistent results for out-of-band data. Rockset is the only platform to support perfect rollups for real-time streaming data.
Practically speaking, this means that when streaming data is rolled up by time, Rockset doesn’t require the data to be ingested in the order in which it was generated. This is especially important for streaming data sources as there is often a need to backfill with late-arriving data. Rockset is the only platform that ensures that rolled-up statistics are correctly updated even if data is received out of order.
Check out our interview with Rockset Chief Architect Tudor Bosman to learn more about the motivation and design behind rollups in Rockset:
Embedded content: https://youtu.be/bu5MRzd8d-0
Rockset vs Druid for Real-Time Rollups
Now that we’ve listed some key functionality above, it may be helpful to compare Rockset’s modern rollup capability to that offered by Apache Druid, an earlier option for real-time analytics on streaming data.
In terms of data sources, Druid supports ingestion from streaming and batch sources, like Hadoop. Support for database change streams is notably absent. Rockset, on the other hand, will ingest and rollup data from operational databases as well.
While Rockset allows rollups and transformations to be specified in SQL, Druid has separate ingestion specs for these. Given the greater expressivity of SQL, there is more flexibility in the types of aggregations users can do in Rockset. In contrast, Druid only does time-based aggregations, which limits the use cases to which they can be applied. In addition, Druid only supports best-effort rollup for streaming sources, which provides a weaker guarantee on the accuracy of results.

Rockset Adds Real Time To the Modern Data Stack
By being the first to allow ingest-time rollups and transformations from any data source, using SQL, Rockset provides the flexibility organizations need in a modern real-time data stack. But aside from the latest rollup functionality, there is a list of other reasons why Rockset is the best option for modern data applications.
-
Simplicity. Rockset doesn’t require an army of infra or data ops, performance engineers or consultants to use.
- No servers or clusters to manage: Rockset is a fully managed serverless database, with no capacity planning, provisioning and scaling to worry about. Druid, whether in the cloud or not, still employs a datacenter-era architecture rooted in servers and clusters, requiring time, effort and expertise to configure and operate.
- No data pre-processing: Data in Druid needs to be flattened and denormalized before ingest. Rockset can ingest data without the need for flattening, denormalization or even a schema, saving lots of data engineering complexity.
-
Efficiency. Rockset’s cloud-native architecture allows the most efficient use of compute and storage resources.
- Scale compute and storage independently: Cloud storage and compute scale independently of each other. In contrast, Druid’s architecture is tightly coupled, so storage and compute have to be scaled in lockstep.
- Utilize resources fully: Because of Druid’s tightly coupled storage and compute, only the compute associated with the data to be processed can be used, while the rest of the compute is idle. Unlike Druid, Rockset is able to utilize all of its compute resources at all times.
-
Built for developers. Rockset makes it easy for developers to build applications on real-time data in the fastest time possible.
- Native SQL: Developers can use standard SQL for queries as well as for ingest-time rollups and transformations. This allows organizations to leverage their existing expertise and SQL ecosystem.
- Query Lambdas: Rockset allows developers to create data APIs simply from Query Lambdas–SQL queries stored in Rockset and executed through a REST endpoint.

Expanding the Reach of Real-Time Analytics with Rockset
Rockset’s underlying converged indexing technology allows it to exploit cloud economics to deliver fast, flexible real-time analytics without any operational overhead. The output from rollups feeds into Rockset's Converged Index to make real-time analytics on large-scale streaming data more affordable and accessible.
If you want to experience Rockset hands-on and better understand how it compares to Druid and other alternatives, you can test drive Rockset on your data and queries with a two week free trial and $300 in free credits here.