Developing Global Labor Market Intelligence at SkyHive Using Rockset and Databricks

January 31, 2023
SkyHive is an end-to-end reskilling platform that automates skills assessment, identifies future talent needs, and fills skill gaps through targeted learning recommendations and job opportunities. We work with leaders in the space including Accenture and Workday, and have been recognized as a cool vendor in human capital management by Gartner.
We’ve already built a Labor Market Intelligence database that stores:
- Profiles of 800 million (anonymized) workers and 40 million companies
- 1.6 billion job descriptions from 150 countries
- 3 trillion unique skill combinations required for current and future jobs
Our database ingests 16 TB of data every day from job postings scraped by our web crawlers to paid streaming data feeds. And we have done a lot of complex analytics and machine learning to glean insights into global job trends today and tomorrow.
Thanks to our ahead-of-the-curve technology, good word-of-mouth and partners like Accenture, we are growing fast, adding 2-4 corporate customers every day.
Driven by Data and Analytics
Like Uber, Airbnb, Netflix, and others, we are disrupting an industry – the global HR/HCM industry, in this case – with data-driven services that include:
- SkyHive Skill Passport – a web-based service educating workers on the job skills they need to build their careers, and resources on how to get them.
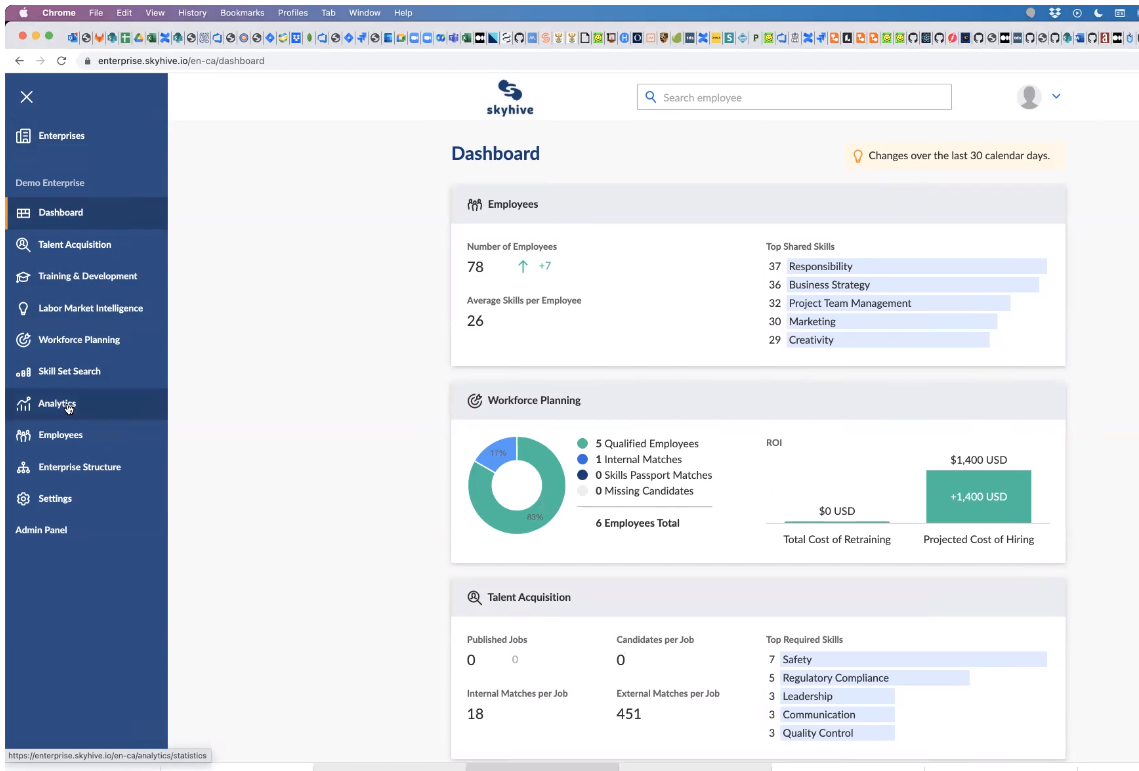
- SkyHive Enterprise – a paid dashboard (below) for executives and HR to analyze and drill into data on a) their employees’ aggregated job skills, b) what skills companies need to succeed in the future; and c) the skills gaps.
- Platform-as-a-Service via APIs – a paid service allowing businesses to tap into deeper insights, such as comparisons with competitors, and recruiting recommendations to fill skills gaps.
Challenges with MongoDB for Analytical Queries
16 TB of raw text data from our web crawlers and other data feeds is dumped daily into our S3 data lake. That data was processed and then loaded into our analytics and serving database, MongoDB.

MongoDB query performance was too slow to support complex analytics involving data across jobs, resumes, courses and different geographics, especially when query patterns were not defined ahead of time. This made multidimensional queries and joins slow and costly, making it impossible to provide the interactive performance our users required.
For example, I had one large pharmaceutical customer ask if it would be possible to find all of the data scientists in the world with a clinical trials background and 3+ years of pharmaceutical experience. It would have been an incredibly expensive operation, but of course the customer was looking for immediate results.
When the customer asked if we could expand the search to non-English speaking countries, I had to explain it was beyond the product’s current capabilities, as we had problems normalizing data across different languages with MongoDB.
There were also limitations on payload sizes in MongoDB, as well as other strange hardcoded quirks. For instance, we could not query Great Britain as a country.
All in all, we had significant challenges with query latency and getting our data into MongoDB, and we knew we needed to move to something else.
Real-Time Data Stack with Databricks and Rockset
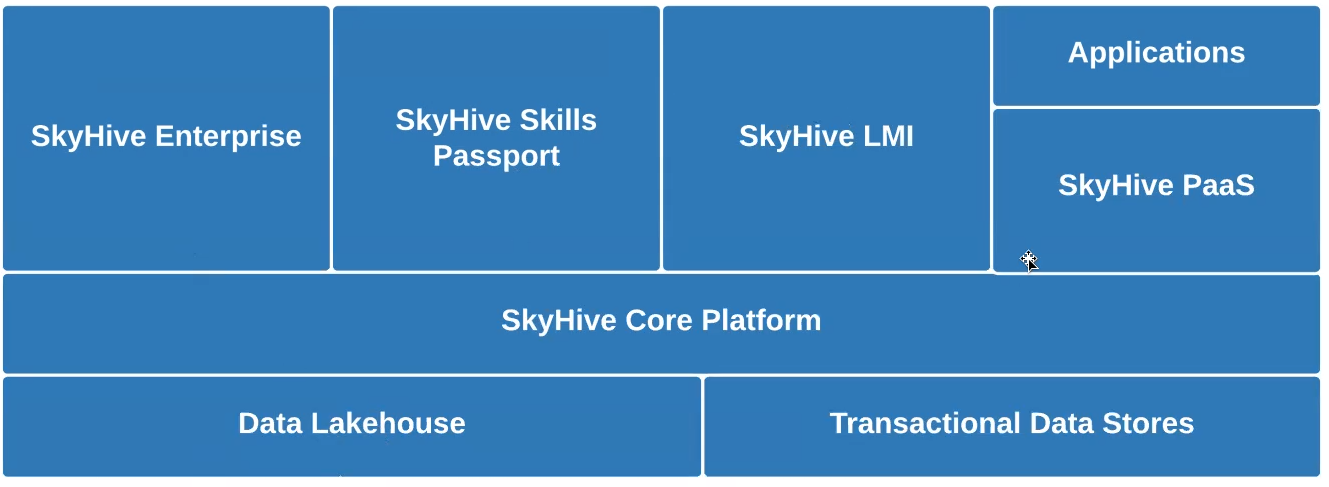
We needed a storage layer capable of large-scale ML processing for terabytes of new data per day. We compared Snowflake and Databricks, choosing the latter because of Databrick’s compatibility with more tooling options and support for open data formats. Using Databricks, we have deployed (below) a lakehouse architecture, storing and processing our data through three progressive Delta Lake stages. Crawled and other raw data lands in our Bronze layer and subsequently goes through Spark ETL and ML pipelines that refine and enrich the data for the Silver layer. We then create coarse-grained aggregations across multiple dimensions, such as geographical location, job function, and time, that are stored in the Gold layer.

We have SLAs on query latency in the low hundreds of milliseconds, even as users make complex, multi-faceted queries. Spark was not built for that – such queries are treated as data jobs that would take tens of seconds. We needed a real-time analytics engine, one that creates an uber-index of our data in order to deliver multidimensional analytics in a heartbeat.
We chose Rockset to be our new user-facing serving database. Rockset continuously synchronizes with the Gold layer data and instantly builds an index of that data. Taking the coarse-grained aggregations in the Gold layer, Rockset queries and joins across multiple dimensions and performs the finer-grained aggregations required to serve user queries. That enables us to serve: 1) pre-defined Query Lambdas sending regular data feeds to customers; 2) ad hoc free-text searches such as “What are all of the remote jobs in the United States?”
Sub-Second Analytics and Faster Iterations
After several months of development and testing, we switched our Labor Market Intelligence database from MongoDB to Rockset and Databricks. With Databricks, we have improved our ability to handle huge datasets as well as efficiently run our ML models and other non-time-sensitive processing. Meanwhile, Rockset enables us to support complex queries on large-scale data and return answers to users in milliseconds with little compute cost.
For instance, our customers can search for the top 20 skills in any country in the world and get results back in near real time. We can also support a much higher volume of customer queries, as Rockset alone can handle millions of queries a day, regardless of query complexity, the number of concurrent queries, or sudden scale-ups elsewhere in the system (such as from bursty incoming data feeds).
We are now easily hitting all of our customer SLAs, including our sub-300 millisecond query time guarantees. We can provide the real-time answers that our customers need and our competitors cannot match. And with Rockset’s SQL-to-REST API support, presenting query results to applications is easy.
Rockset also speeds up development time, boosting both our internal operations and external sales. Previously, it took us three to nine months to build a proof of concept for customers. With Rockset features such as its SQL-to-REST-using-Query Lambdas, we can now deploy dashboards customized to the prospective customer hours after a sales demo.
We call this “product day zero.” We don’t have to sell to our prospects anymore, we just ask them to go and try us out. They’ll discover they can interact with our data with no noticeable delay. Rockset’s low ops, serverless cloud delivery also makes it easy for our developers to deploy new services to new users and customer prospects.

We are planning to further streamline our data architecture (above) while expanding our use of Rockset into a couple of other areas:
- geospatial queries, so that users can search by zooming in and out of a map;
- serving data to our ML models.
Those projects would likely take place over the next year. With Databricks and Rockset, we have already transformed and built out a beautiful stack. But there is still much more room to grow.