- Contents
What Is Elasticsearch?
Elasticsearch is an open-sourced distributed search engine built on Apache Lucene. Learn how Elasticsearch works under the hood and common use cases.

Contents
What is Elasticsearch?
Elasticsearch is an open-sourced distributed search engine built on Apache Lucene. It was first released in 2010 for log analytics and text search use cases. Elasticsearch is known for being able to find needle-in-the-haystack queries on large-scale unstructured data.
What gives Elasticsearch its speed is the search index or a mapping of content to its location in a document. You can think of a search index as similar to the index in the back of a book. Rather than scanning through an entire book trying to find mentions of a particular word or phrase, you can go to an index and find the exact page number to locate the information.
How Is It Used?
Elasticsearch is most commonly used as a part of the ELK stack. ELK refers to Elasticsearch, Logstash and Kibana. While Elasticsearch is the search engine at the core of the stack, Logstash is used to ingest data and Kibana to visualize data. The core use cases for this stack are:
Log Analytics: The ability to search through petabytes of log data produced by your application and infrastructure for near real-time troubleshooting of application performance and availability. To make sense of your log data, Elasticsearch parses and transforms the data before indexing.
Observability: Aggregating data from metrics, traces and logs to measure performance and identify potential issues. Many teams start out using Elasticsearch for log analytics and expand into observability.
Full Text Search: Find any word or phrase within a document using either standard or customized text search capabilities. Using full text search capabilities in Elasticsearch requires configuring analyzers, tokenizers and stemming.
Security Analytics: Aggregating and analyzing security information and events from a wide range of sources to find anomalies, detect threats and streamline responses. Elastic, a managed service of Elasticsearch, has acquired security company Endgame as part of efforts to expand its endpoint detection and response capabilities.
Real-Time Analytics: Using data as soon as it is produced to answer questions, make predictions, understand relationships, and automate processes. Many teams start using Elasticsearch for log analytics or text search and then expand into real-time analytics, even though it’s not built for this use case.
Elasticsearch is known for being a powerful search engine that is flexible and can be highly customized. That said, Elasticsearch is a complex distributed system that requires considerable maintenance and development time from big data engineers.
How Does It Work?
Elasticsearch is a document-oriented search engine. Elasticsearch ingests and indexes the data, depending on your mappings and use case, to make entire JSON documents searchable. For teams coming from a relational world, that means you are searching and filtering for specific documents so they need to be modeled for the access patterns of your use case. This is different from searching for individual rows or columns of data, as is typical in OLTP databases or data warehouses.
As we’ve mentioned before, Elasticsearch indexes documents for fast retrieval. Mappings can be used to tell Elasticsearch how to store and index different fields, for example specifying that certain string fields be indexed for full text search. And, documents with the same mappings can be stored in the same index, referred to as a type.
Under the hood, Elasticsearch is a distributed system and uses Lucene indexes which are broken down into shards. When creating an index, you specify the number of shards and replicas. The documents in a Lucene index are distributed across multiple shards. Data is written to shards and then flushed to immutable segments. Shards enable data to be distributed across a cluster.
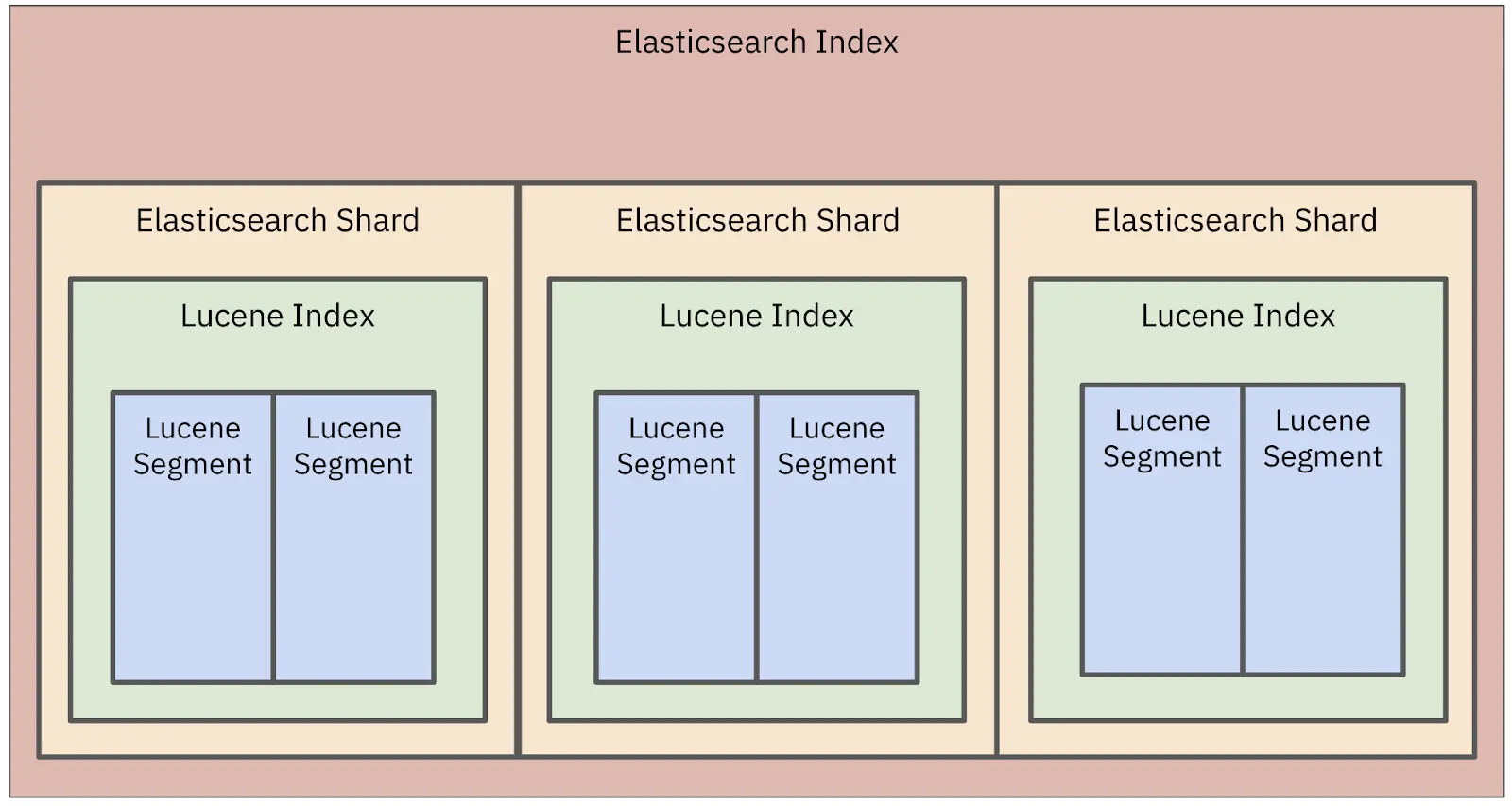
Figure 1: Elasticsearch data is stored in a Lucene index and that index is broken down into smaller segments.
To query data, Elasticsearch has its own Domain-Specific Language (Query DSL) that can retrieve documents in a JSON format. The Query DSL is how most teams use Elasticsearch to retrieve data, although there is also Elasticsearch SQL that simply converts the query into their DSL.
Elasticsearch can be self-managed using open-source licensing or can be managed using Elastic or AWS (which now has a forked version called OpenSearch ). Even when using a managed option , you will still need to configure and manage indexes, clusters, shards and nodes. A considerable amount of knowledge is required to manage and optimize Elasticsearch for different use cases.
How To Ingest Data
Elasticsearch is a NoSQL system and supports the schemaless ingest of data. There are four main ways to ingest data into Elasticsearch : Elastic Beats, Logstash, Language Clients and Elastic Ingest Nodes.
Elastic Beats: Considered a lightweight option to send data to Elasticsearch. It’s commonly used to ingest data from devices, such as IoT or edge devices. There are different flavors of Beats, depending on the use case. For example, Filebeat is built for ingesting data in different file formats whereas Metricsbeat collects and aggregates system data for metrics.
Logstash: Logstash is more powerful than Beats and enables users to transform documents with additional metadata. Logstash creates an event processing pipeline that takes a data source as an input and outputs the transformed data to Elasticsearch or other services.
Language Clients: Data can be ingested via the REST API using supported client libraries Java, Javascript, Ruby, Go, Python and more. Client libraries do need to be configured to work with queueing and back-pressure so that data is not lost.
Elasticsearch Ingest Nodes: Any node in an Elasticsearch cluster can be designated as an ingest node with the CPU marked for bulk or indexing requests and transformations. There is some overlap in use cases between Elasticsearch ingest nodes and Logstash but the former is considered to be a simpler architecture. Just like when using language clients, queueing and back-pressure need to be applied to avoid situations of data loss.
How to Design for Relationships
Before indexing your data, you’ll want to determine your document data model to support the access patterns of your use case.
For example, I may have a series of documents with every user ID and their IP address and I only want to search on those pieces of information. I might choose to only index those fields and use types to limit the number of indexes and save on compute and memory.
{
"userId": "1A567D",
"IP address”: "192.158.1.38",
"State": "CA",
"Web Page": "Homepage, Product, Pricing"
}
Elasticsearch has a non-relational data model which is ideal for log analytics use cases where you have a flattened data structure.
When using Elasticsearch for analytics, you’ll often want to represent relationships across different hierarchy levels. In these scenarios, Elasticsearch offers four options: nested objects, parent-child objects, denormalization and application-side joins.
Nested Objects: Nested objects are used to maintain relationships of each object in an array. They can be specified as a nested type at index time to allow arrays of objects to be indexed as separate Lucene documents. As Elasticsearch is not relational in nature, there are drawbacks to nested objects including that every update to a child record will result in the reindexing of the document. And, that search requests return the entire document rather than just the nested document.
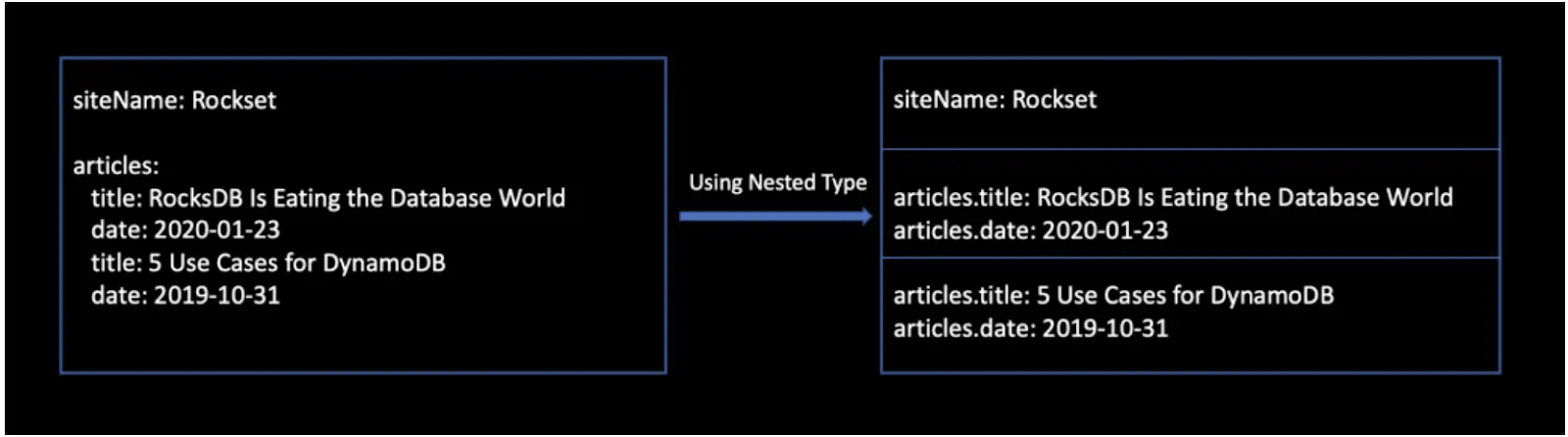
Figure 2: Arrays of objects indexed internally as separate Lucene documents in Elasticsearch using nested objects
Parent-Child: Parent-child relationships leverage the join datatype in order to completely separate objects with relationships into individual documents—parent and child. This enables you to store documents in a relational structure in separate Elasticsearch documents that can be updated separately. While parent-child relationships overcome the issues of frequent updates, the queries are more expensive and memory-intensive because of the join operation. And, it only works well for small datasets when the parent and children can live on the same shard.
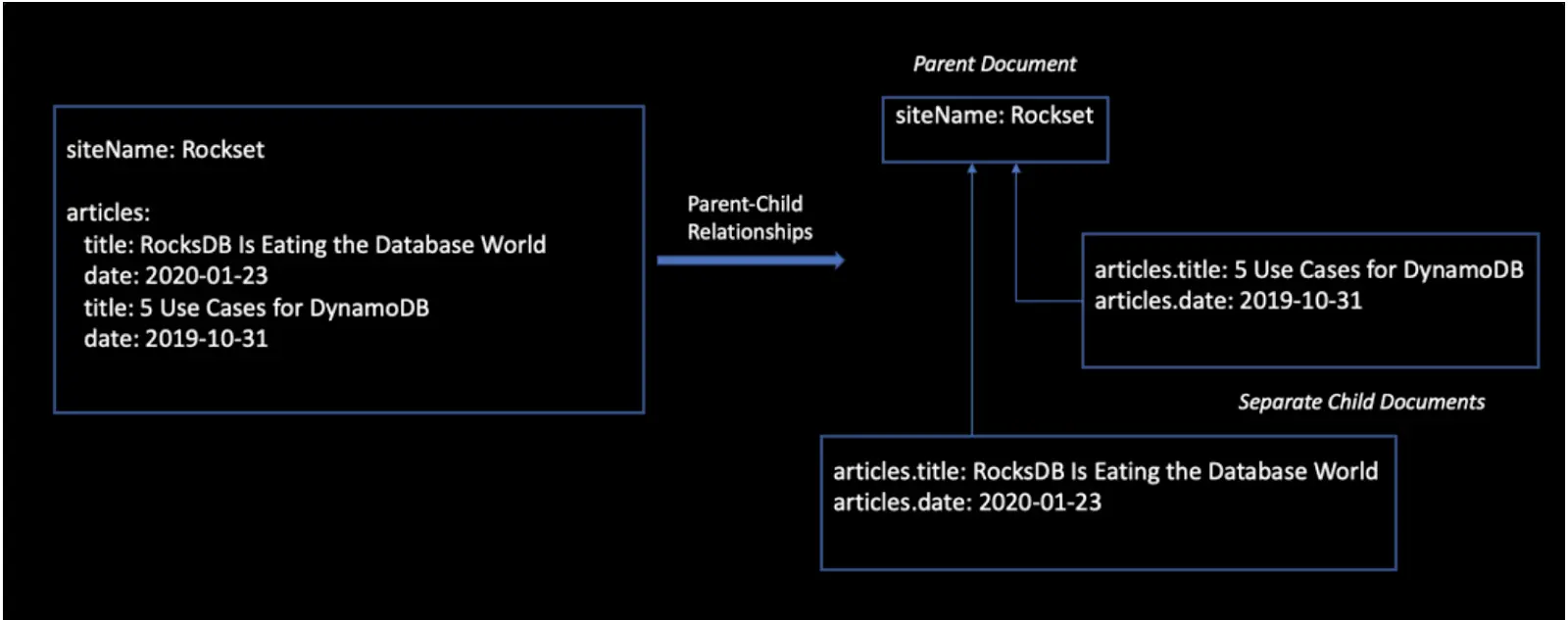
Figure 3: Parent-child model for one-to-many relationships
Elasticsearch should not be used as a relational database. That’s why it’s a best practice to denormalize your data to support relationships as Elasticsearch is a NoSQL data system. Or, to do application-side joins and put the logic on the application side.
How To Index and Reindex Data
As we mentioned above, an index in Elasticsearch is used to organize the data for efficient retrieval as well as to determine how data is distributed. It’s recommended to think through your document data model and the types of search and analytics needed for your use case.
While Elasticsearch can use dynamic mapping to infer the data types of fields, it’s a best practice to create an index with explicit typings to ensure data can be read efficiently. For example, you can specify a string as a timestamp field or a name as a text field. You can also add fields to an existing index, to save on the memory and CPU required to index data.
If you are specifying a text search field, Elasticsearch will parse the string of data and tokenize it to break up the text into characters, words and sentences. These terms are normalized to search for similar words and phrases in a standard format. Built-in analyzers in Elasticsearch are packages that can be used with character filters, tokenizers and token filters.
When you create an index, you specify the number of primary shards and this cannot be changed at a later time. Specifying the number of shards is no easy feat and getting it wrong can often result in performance problems. Sharding is especially challenging for multi-tenant applications when the size of data and access patterns differ substantially from tenant to tenant. The best way to determine the shard size is to benchmark on your own data and queries at scale.
Once you determine your mappings and settings, you can use an index template or a component template. This enables you to easily manage the setting and the mappings for any new index that you are creating.
If you need to make any changes to your mappings or settings, the data in Elasticsearch will need to be reindexed. Reindexing is operationally complex and has the potential to cause a cluster to go down, especially when large amounts of data need to be reindexed.
The other time that reindexing comes into play is when there are updates, inserts and deletes . As we’ve described previously, data is written to shards and flushed to immutable segments. This removes the ability for field-level updates, requiring entire documents to be reindexed. This can be expensive if there are frequent data changes.
How to Query Data
There are two ways to approach querying data in Elasticsearch, searching for specific values in a structured field or analyzing text fields. For text fields, analyzing the text can be highly complex and specific to the different analyzer packages that are used.
Elasticsearch provides a full Query DSL (Domain Specific Language) based on JSON. Queries can include one query clause or multiple causes, referred to as compound query clauses. There can be a steep learning curve in understanding the DSL, especially given the degree of customization in Elasticsearch.
Elastic SQL was introduced for new users who struggled to learn the Elasticsearch DSL or for data scientists and analysts who wanted to use Elasticsearch for BI use cases. While useful in these cases, Elastic SQL does not replace the need for data modeling or make Elasticsearch a relational database. That’s why it’s common for teams to use the Query DSL as it’s built to work with the non-relational data model and ensure the performance and efficiency of Elasticsearch.
How to Setup and Monitor a Cluster
An Elasticsearch index comprises one or more shards and those shards can be distributed across one or more nodes. The cluster can grow or shrink its capacity and reliability as nodes are added or removed. Shards will automatically be balanced and re-balanced across the number of nodes available in the cluster.
As we mentioned above, the number of primary shards is determined at the time of index creation. By default, a new index is given five primary shards which can be distributed by a maximum of five nodes (one per shard). It’s possible to have fewer nodes in a cluster.
You can also specify roles for nodes depending on if it is the master, data, ingest, transform, data_warm, data_cold, etc. It’s recommended to have a few master nodes and to set them at the onset of cluster creation to avoid any issues in adding or removing masters from the cluster.
The most optimal way to configure your cluster is through testing with your own data and queries. It’s recommended to avoid disasters by using cross-cluster replication and having in place tools to manage and monitor your cluster. Oftentimes, we’ll see teams use index lifecycle management to help age out data overtime.
Even using a managed offering by Elastic or AWS will require you to configure and manage the clusters, indexes, shards and nodes. This is why many teams using Elasticsearch have dedicated engineers with expertise in distributed search systems.
When Should You Use Elasticsearch?
Elasticsearch is a powerful search engine for log analytics and observability. Using Elasticsearch as part of the ELK stack has its advantages. Logstash enables data ingestion and transformation from many sources while Kibana has an intuitive and complete dashboarding solution for observability.
The strength of Elasticsearch comes from its high degree of flexibility and potential for customization. As a result, teams that use Elasticsearch have big data expertise in-house. This is both to setup and manage Elasticsearch as it's a large-scale distributed system that is complex to configure and manage.
Rockset as a Real-Time Analytics Alternative to Elasticsearch
Many engineering teams who start out using Elasticsearch for log analytics look to expand the system’s usefulness to other areas of their application. That’s because Elasticsearch returns millisecond-latency queries with indexes, is developer-friendly and has great documentation.
But, you're abusing Elasticsearch when expanding its use to complex filtering, aggregations and analytics in applications. That’s because Elasticsearch has search indexing capabilities but lacks analytics to support large-scale aggregations and joins. Learn more about Rockset as a real-time analytics alternative to Elasticsearch and how it delivers SQL joins on nested JSON at scale, while using 44% less compute.