- Contents
Whitepaper
Rockset vs Apache Druid for Real-Time Analytics
While Rockset and Apache Druid are both geared towards real-time analytics use cases, Rockset offers the performance, schema and query flexibility, and serverless architecture to make developers as productive as possible. Engineering teams build data applications in days using Rockset, resulting in much faster time to market compared to Druid.

Introduction
Rockset and Apache Druid are two options for real-time analytics. Druid was originally introduced in 2011 by Metamarkets, an ad tech company, as the data store for their analytics products. Rockset was started in 2016 to meet the needs of developers building real-time data applications. Rockset leverages RocksDB, a high-performance key-value store used as a storage engine for databases like Apache Cassandra, CockroachDB and MySQL.
There are several commonalities between Rockset and Druid. Both utilize a distributed architecture to distribute query execution across multiple servers. Both provide and emphasize the ability to ingest and query real-time data such as streams.
Rockset and Druid also incorporate ideas from other data stores, like data warehouses, search engines and time series databases. In Rockset’s case, it stores data in a Converged Index™ that builds a row index, columnar index and search index on all fields. This allows Rockset’s SQL engine to use combinations of indexes to accelerate multiple kinds of analytical queries, from highly selective queries to large-scale aggregations.
While Rockset and Druid share certain design goals, there are significant differences in other areas. Design for the cloud is one area where they diverge. Druid has multiple deployment options, including on-premises and in the cloud, whereas Rockset is designed solely for the cloud. Druid uses commodity servers as the primary building block for its clusters, while Rockset has the ability to optimize fully for cloud infrastructure and cloud services, as will be apparent in the Architecture and Operations sections of this paper.
Another significant difference is Rockset’s focus on developer productivity. Rockset is designed to provide the greatest data and query flexibility, without the need for data and performance engineering. In addition, Rockset is offered as serverless SaaS, which gives users the ultimate operational simplicity because they do not have to pre-provision servers or storage. Many of the technical differences between Rockset and Druid that impact the ease with which applications can be built and run in production are covered in the Ingestion, Querying and Operations sections of this paper.
Architecture
Separation of Ingest Compute and Query Compute
The Druid architecture employs nodes called data servers that are used for both ingestion and queries. In this design, high ingestion or query load can cause CPU and memory contention. For instance, a spike in ingestion workload can negatively impact query latencies.
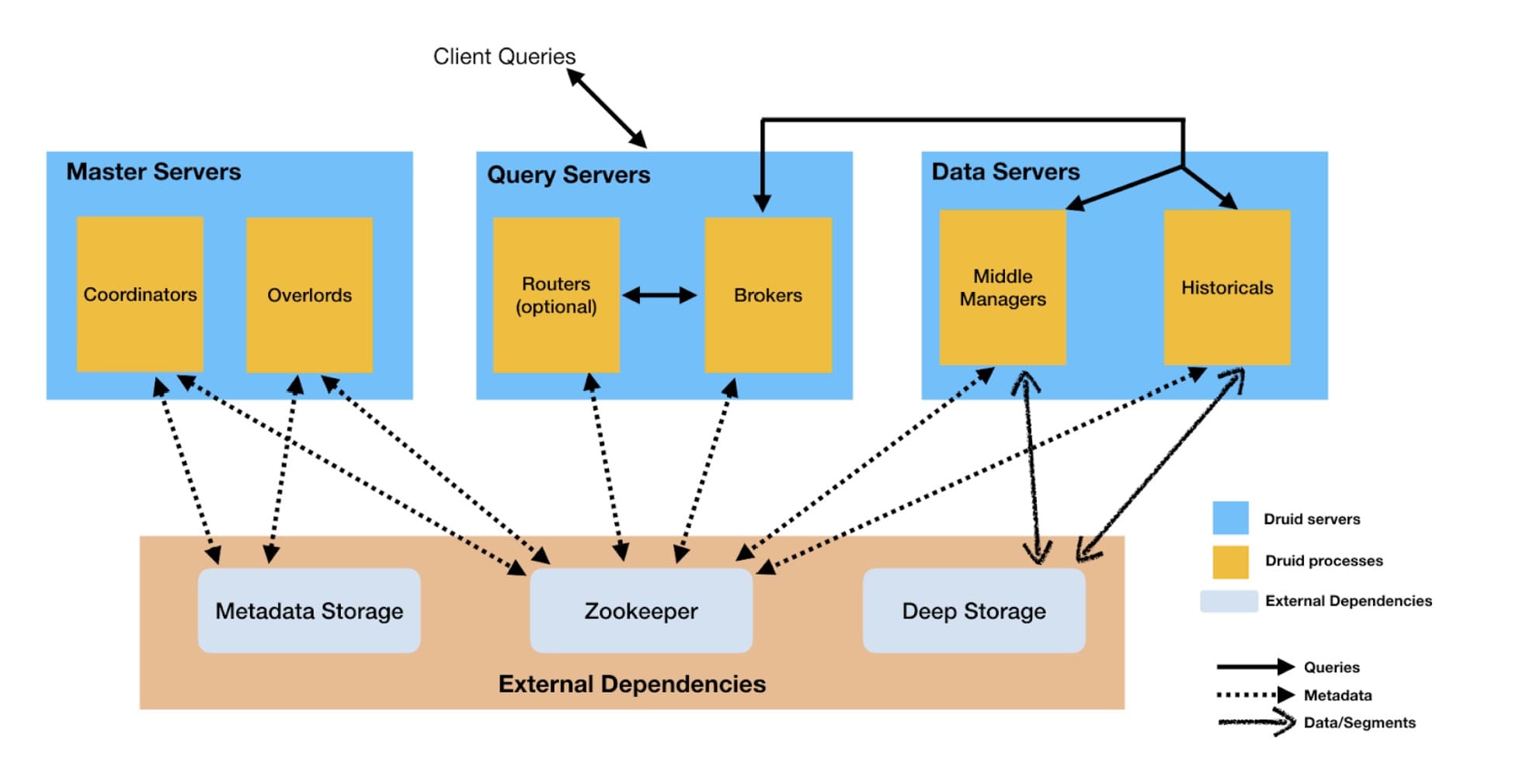
If necessary, the Druid processes that handle ingestion and querying on historical data can be run on separate nodes. However, the default setting is that ingestion and queries are run on the same node. Breaking apart the pre-packaged data server components involves planning ahead and additional complexity, and is not an action that is taken dynamically in response to emergent ingestion and query loads.
Rockset employs a cloud-native, Aggregator Leaf Tailer (ALT) architecture, favored by web-scale companies like Facebook, LinkedIn and Google, that disaggregates resources needed for ingestion, querying and storage. Tailers fetch new data from data sources, Leaves index and store the data and Aggregators execute queries in distributed fashion.
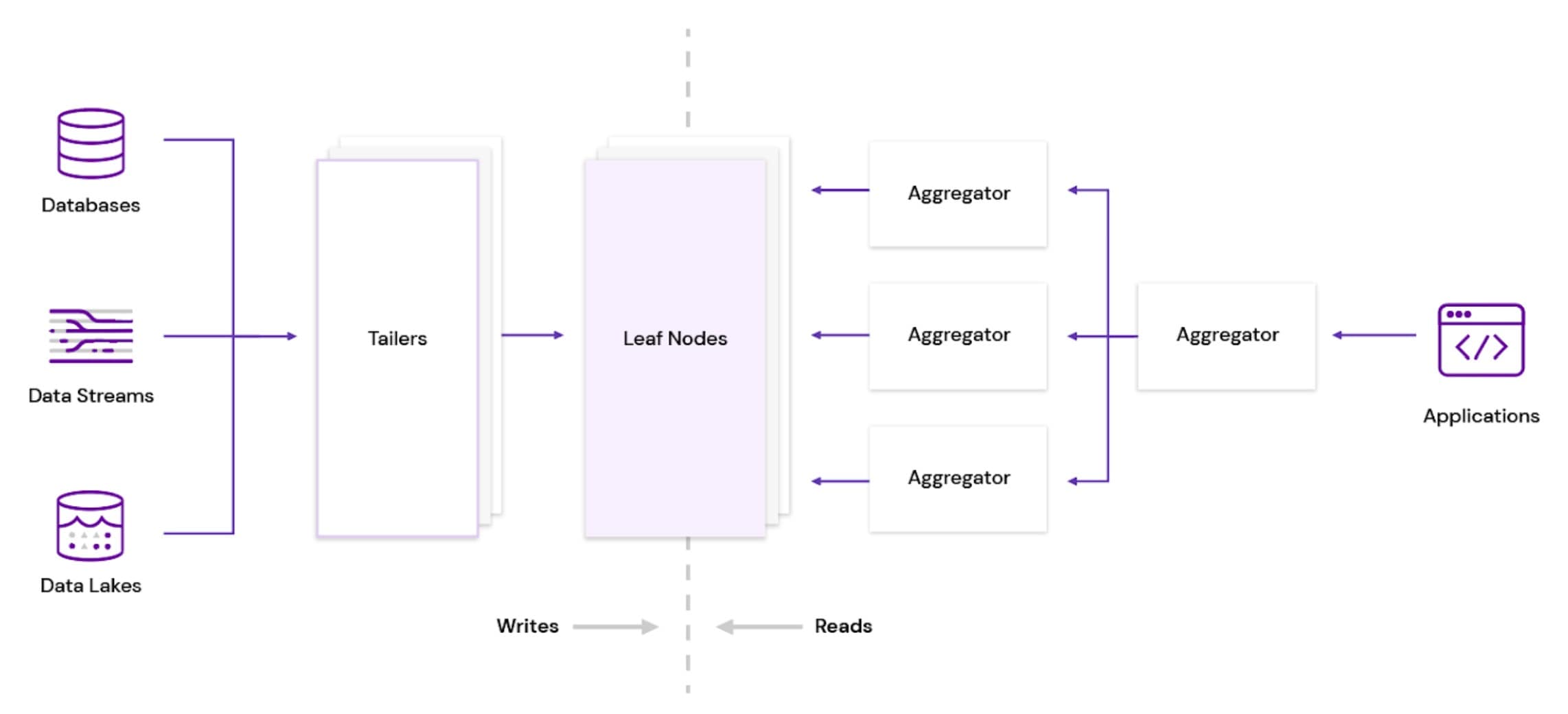
The Rockset architecture implements the Command Query Responsibility Segregation (CQRS) pattern, keeping compute resources separate between ingestion and queries, and allowing each to be scaled independently. Rockset scales Tailers when there is more data to ingest and scales Aggregators when the number or complexity of queries increases. As a result, the system provides consistent query latencies even under periods of high ingestion loads.
Separation of Compute and Storage
Druid does not decouple compute and storage but combines them for performance reasons. Queries must be routed to the node on which the data resides and are limited by the compute resources on that node for execution. This means that query performance is closely tied to the fixed ratio of compute to storage on Druid nodes; there is no easy way to vary the compute resources available to handle larger query loads.
As described in the Rockset ALT architecture, Rockset adds Leaves when there is more data to be managed and scales Aggregators when the query workload increases. Aggregator resources are not tied to where the data is located, so users can simply add compute as needed, without having to move to different hardware instances or change the distribution of data. The ability to share available compute across queries, regardless of where data is stored, also allows for more efficient utilization of resources.
Mutability
Druid writes data to segments, converting the data to columnar format and indexing it in the process. Once the segments are built, they are periodically committed and published, at which point they become immutable.
This design is suitable for append-only use cases but is limiting for many real-world situations where data needs to be corrected or where data is sent out of order. For instance, backfilling data is frequently needed in streaming systems where a small fraction of data regularly arrives late, outside of the current time window. Older time segments in Druid will need to be updated in this case. This and other use cases that require frequent updates to existing data, such as when ingesting data from operational databases, are problematic. Updating data in Druid may require reingesting and reindexing data for the time chunks that need to be updated.
In contrast, Rockset is a mutable database. It allows any existing record, including individual fields of an existing deeply nested document, to be updated without having to reindex the entire document. This is especially useful and very efficient when staying in sync with operational databases, which are likely to have a high rate of inserts, updates and deletes.
Rockset has a Patch API that allows users to perform updates at the field level, reindexing only the fields that are part of the patch request while keeping the rest of the fields in the document untouched.
Sharding
Druid is a term-sharded system, partitioning data by time and storing these partitions as segment files. This design optimizes for write efficiency because all records for a time interval are written to the same segment sequentially. However, reads can be less efficient. A data segment is determined by a key range–in this case a time interval–and resides on one or two servers. All queries that need to access keys in that range need to hit these specific servers, which can lead to a hot-key problem when queries are concentrated on a particular time range, resulting in poor performance, inefficient hardware utilization and limits to scalability.
Rockset takes a different approach and is a document-sharded system, a common implementation with search engines. Rockset uses a synthetic field as a shard key, ensuring records are distributed across servers as randomly as possible. A single query can utilize the compute on all the servers in parallel, which results in lower query latency and avoidance of hot-key problems.
Rockset also employs a novel sharding technique called microsharding. Each document in a Rockset collection is mapped to a microshard, and a group of microshards comes together to form a Rockset shard. The use of microsharding makes it easy to stay within an optimal sharding configuration just by reorganizing microshards to get the desired number of shards and shard size. This feature allows a user to migrate a collection from one Rockset Virtual Instance to another quickly and without any downtime. Increasing and decreasing the number of shards is more complicated in Druid and regularly requires compaction and reindexing.
Ingesting Data
Ingestion Methods
Druid supports streaming and batch ingestion methods. It has native support for Kafka and Kinesis streaming sources and can also ingest from various cloud storage, HDFS and RDBMS options through batch indexing tasks.
Rockset ingests from streaming, cloud storage and database sources such as Kafka, Kinesis, S3, Google Cloud Storage, DynamoDB, MongoDB, MySQL and PostgreSQL. Importantly, Rockset provides built-in connectors to cloud storage and database sources that not only perform an initial load but stay in sync with any changes as well. Rockset’s mutability, discussed in the Architecture section above, enables it to accept frequent updates of data, which is essential for the continuous, real-time sync between Rockset and operational databases.
Both streaming and batch ingestion in Druid require the definition of an ingestion spec, which provides information on the schema, how to read from the specific source and tuning parameters. This spec can run into hundreds of lines for more complex data sets.
"dataSchema": {
"dataSource": "wikipedia",
"timestampSpec": {
"column": "timestamp",
"format": "auto"
},
"dimensionsSpec": {
"dimensions": [
{ "type": "string", "page" },
{ "type": "string", "language" },
{ "type": "long", "name": "userId" }
]
},
"metricsSpec": [
{ "type": "count", "name": "count" },
{ "type": "doubleSum", "name": "bytes_added_sum", "fieldName": "bytes_added" },
{ "type": "doubleSum", "name": "bytes_deleted_sum", "fieldName": "bytes_deleted" }
],
"granularitySpec": {
"segmentGranularity": "day",
"queryGranularity": "none",
"intervals": [
"2013-08-31/2013-09-01"
]
}
}
To simplify the spec, Druid users have the option of leaving out dimension fields. In this case, Druid uses schemaless interpretation and ingests these fields as string-typed dimensions.
When ingesting into Rockset from supported data sources, such as DynamoDB and MongoDB, users generally only need to provide connection information to the data source in the Rockset Console or via the Rockset API, without the need for upfront data definition. Users may specify field mappings to transform incoming data–for type coercion, data masking or dropping fields–but these are optional.
Rockset will perform schemaless ingestion for all incoming data, and will accept fields with mixed types, nested objects and arrays, sparse fields and null values. In many cases, Rockset will automatically generate the schema based on the exact fields and types present in the database.
Data Model
Druid employs a flat data model. Data formats, such as JSON, that support nested data need to be flattened upon ingestion. Users have to specify a flattenSpec to define how the nested data should be handled. This takes time and effort to create and maintain, and data ingestion may break if the data changes unexpectedly.
"flattenSpec": {
"useFieldDiscovery": true,
"fields": [
{ "name": "baz", "type": "root" },
{ "name": "foo_bar", "type": "path", "expr": "$.foo.bar" },
{ "name": "first_food", "type": "jq", "expr": ".thing.food[1]" }
]
}
Rockset fully supports the ingestion and querying of nested data, indexing every individual field without the user having to perform any manual specification. There is no requirement to flatten nested objects or arrays at ingestion time.
Performance Optimizations at Ingestion
Druid leverages data denormalization and write-time aggregation at ingestion to reduce query latency.
Druid recommends the use of data denormalization as far as possible. Using flat schemas in Druid improves performance significantly by avoiding the need for JOINs at query time. It is common for data to go through an additional denormalization step before ingestion into Druid.
A big cost of denormalization is that users have to denormalize data with a single JOIN pattern in mind. To support multiple JOIN patterns, users need multiple denormalizations. Even if these patterns are known in advance, performing multiple denormalizations is costly in terms of effort and storage. Relying on denormalization makes ad hoc queries very difficult.
Druid makes extensive use of write-time aggregations, called rollups, as another performance optimization method. Rollups can improve query performance because less data is queried, but this strategy will not work in cases where fine-grained queries are required.
Rockset takes advantage of its Converged Index and cloud elasticity to enable low-latency queries on high-velocity data. While Rockset provides the option to use SQL-based rollups, most use cases can be adequately supported by query-time aggregations on normalized data. As a result, it takes less time and effort at ingestion to make the data available for querying.
Querying Data
SQL and JOINs
Druid has a native JSON-based query language and provides Druid SQL as an alternative that translates into its native queries. In contrast, Rockset was built with standard ANSI SQL as its native query language.
Due to how the two technologies were designed, one major difference between Druid and Rockset is in their support for SQL JOINs. JOINs are a recent feature in Druid, having been introduced in April 2020, and also take significant effort to implement. As such, JOIN functionality in Druid is limited.
Druid currently only supports broadcast JOINs, so users cannot JOIN two large tables as one of them needs to fit into the memory of a single server. From a performance perspective, JOINs result in 3x query latency degradation compared to using a denormalized data set. Druid best practice is still to avoid JOINs and use denormalized data where possible.
In supporting full-featured SQL, Rockset was designed with JOIN performance in mind. Rockset partitions the JOINs, and these partitions run in parallel on distributed Aggregators that can be scaled out if needed. It also has multiple ways of performing JOINs:
- Hash Join
- Nested loop Join
- Broadcast Join
- Lookup Join
The ability to JOIN data in Rockset is particularly useful when analyzing data across different database systems and live data streams. Rockset can be used, for example, to JOIN a Kafka stream with dimension tables from MySQL. In many situations, pre-joining the data is not an option because data freshness is important or the ability to perform ad hoc queries is required.
Developer Tooling
Both Druid and Rockset provide REST APIs, which allow users to ingest, manage and query data. Beyond that, Druid is more focused on BI use cases, whereas Rockset is designed for serving applications.
To increase the productivity of developers building applications, Rockset has additional tooling such as support for Query Lambdas, which are named parameterized SQL queries stored in Rockset that can be executed from a dedicated REST endpoint. Users can create these REST endpoints from their queries in a matter of clicks, without any API development or hosting additional servers. From there, they can reference the new endpoint created and provide live data APIs. Query Lambdas can also be used to version control queries, so that developers can collaborate easily with their data teams and iterate faster.
Operations
Cluster Management
Druid clusters can be run in self-managed mode or through a company that commercializes Druid as a cloud service. In a self-managed cluster, Druid users will need to install and configure Druid services for 3 different types of nodes as well as required services like ZooKeeper, a metadata store such as MySQL or PostgreSQL, and deep storage in the form of S3 or HDFS. The cloud version will help remove some of the software installation and configuration burden, but users still need to select a software distribution, perform capacity planning and specify the number and size of Data, Query and Master servers in order to provision a cluster.
In contrast, Rockset is fully managed and serverless. The concept of clusters and servers is abstracted away, so no provisioning is needed and users do not have to manage any storage themselves. Software upgrades happen in the background, so users can easily take advantage of the latest version of software.
Scaling
Druid clusters can be scaled either vertically or horizontally. When scaling vertically, users replace existing servers with larger ones, so they will need to specify the new instance size to be used. When scaling horizontally, users add more data servers to the cluster, so they will have to determine how many nodes they require in the scaled-out cluster. In both cases, users are still exposed to decisions about the number and size of servers as the cluster is scaled.
Scaling in Rockset involves less effort. Storage autoscales as data size grows, while compute can be scaled by specifying the Virtual Instance size, which governs the total compute and memory resources available in the system. Users do not have to specify instance types or numbers of nodes explicitly in Rockset.
Performance Tuning
Druid provides many configuration parameters that can be tuned to improve query performance. There will usually be 6 Druid configuration files, one for each Druid process and one for common properties shared across the Druid services. These configurations cover properties like sizing for heap, direct memory and cache, and the level of parallelism for each Druid process. Understanding how multiple services and configuration properties work together in order to tune performance can require considerable expertise and effort, while getting the configuration wrong risks adverse effects on the system.
Rockset avoids the need for extensive performance tuning by relying on its Converged Index and disaggregated ALT architecture to deliver fast queries with minimal manual intervention. Its Converged Index accelerates a wide range of queries, while its cloud-native architecture makes it easy to reduce query latency by simply adding more compute resources, without managing multiple lists of service-specific configuration properties.
Summary
While Rockset and Druid may provide similar real-time analytics functionality on the surface, many technical differences between the two exist in the areas of Architecture, Ingesting Data, Querying Data and Operations.
- Design for cloud - Rockset is truly cloud-native and serverless, while Druid offers on-premises and cloud deployment options. This focus on cloud allows Rockset to scale quickly and easily, leveraging its disaggregated cloud-native architecture.
- Flexibility - Rockset makes flexibility in ingesting and querying data a core design principle. Users can ingest nested, semi-structured data as is and run familiar SQL, including JOINs, without denormalizing data ahead of time. Rockset provides built-in connectors for fast, easy ingestion from common data sources along with developer tooling that makes it simple to create data APIs.
- Operational simplicity - Unlike Druid, which requires manual intervention for many operational tasks, Rockset is offered as a fully managed serverless database, so users do not have to be concerned with planning, sizing, provisioning and scaling servers and clusters.
These important differences enable developers to be as productive as possible and allow even lean engineering teams to build and run production applications with minimal data engineering, performance tuning and operations effort. As a result, organizations are able to deliver real-time analytics features and products much faster with Rockset.