


Streaming SQL Joins in Rockset


July 12, 2022
Users are increasingly recognizing that data decay and temporal depreciation are major risks for businesses, consequently building solutions with low data latency, schemaless ingestion and fast query performance using SQL, such as provided by Rockset, becomes more essential.
Rockset provides the ability to JOIN data across multiple collections using familiar SQL join types, such as INNER, OUTER, LEFT and RIGHT join. Rockset also supports multiple JOIN strategies to satisfy the JOIN type, such as LOOKUP, BROADCAST, and NESTED LOOPS. Using the correct type of JOIN with the correct JOIN strategy can yield SQL queries that complete very quickly. In some cases, the resources required to run a query exceeds the amount of available resources on a given Virtual Instance. In that case you can either increase the CPU and RAM resources you use to process the query (in Rockset, that means a larger Virtual Instance) or you can implement the JOIN functionality at data ingestion time. These types of JOINs allow you to trade the compute used in the query to compute used during ingestion. This can help with query performance when query volumes are higher or query complexity is high.
This document will cover building collections in Rockset that utilize JOINs at query time and JOINs at ingestion time. It will compare and contrast the two strategies and list some of the tradeoffs of each approach. After reading this document you should be able to build collections in Rockset and query them with a JOIN, and build collections in Rockset that JOIN at ingestion time and issue queries against the pre-joined collection.
Solution Overview
You will build two architectures in this example. The first is the typical design of multiple data sources going into multiple collections and then JOINing at query time. The second is the streaming JOIN architecture that will combine multiple data sources into a single collection and combine records using a SQL transformation and rollup.
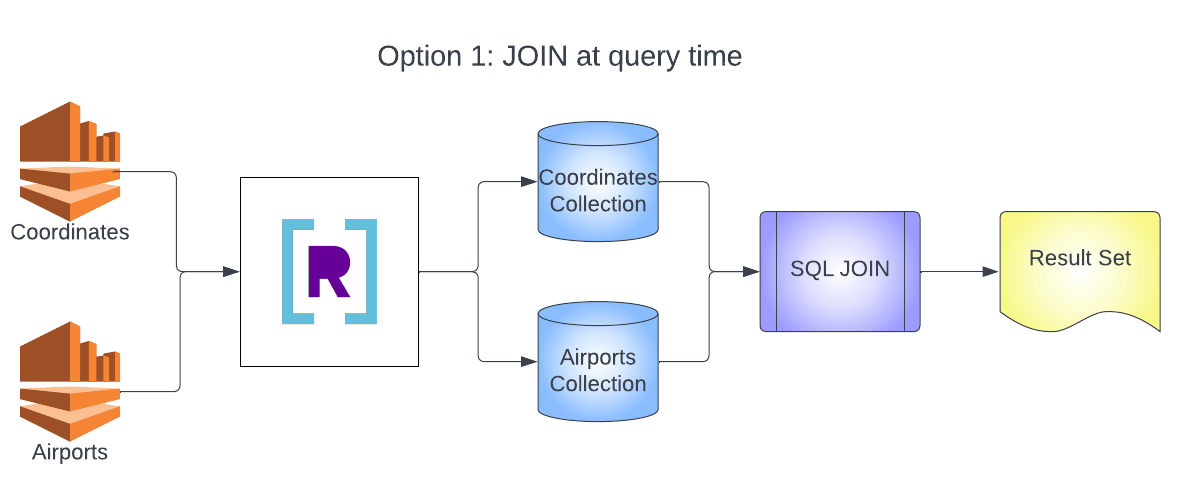
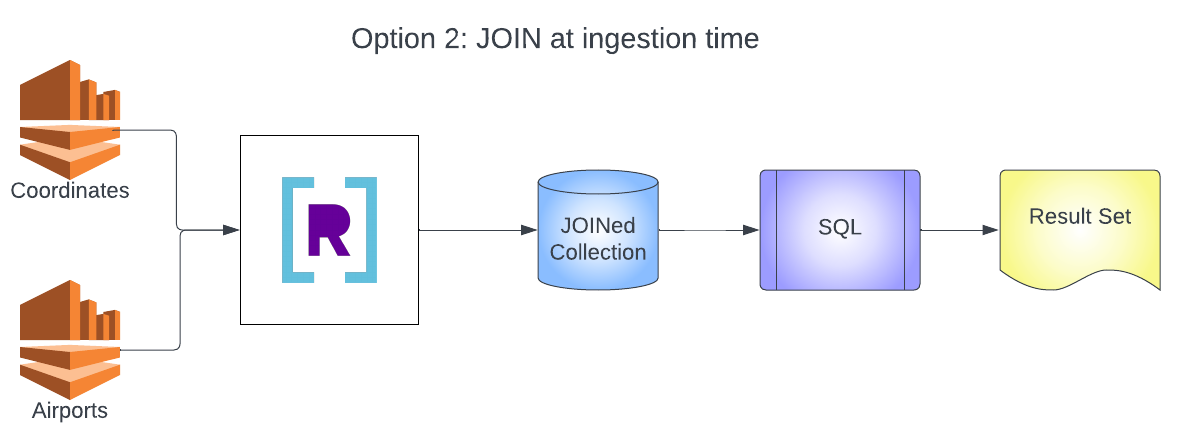
Dataset Used
We are going to use the dataset for airlines available at: 2019-airline-delays-and-cancellations.
Prerequisites
- Kinesis Data Streams configured with data loaded
- Rockset organization created
- Permission to create IAM policies and roles in AWS
- Permissions to create integrations and collections in Rockset
If you need help loading data into Amazon Kinesis you can use the following repository. Using this repository is out of scope of this article and is only provided as an example.
Walkthrough
Create Integration
To begin this first you must set up your integration in Rockset to allow Rockset to connect to your Kinesis Data Streams.
- Click on the integrations tab.

- Select Add Integration.
- Select Amazon Kinesis from the list of Icons.

- Click Start.
-
Follow the on screen instructions for creating your IAM Policy and Cross Account role. a.Your policy will look like the following:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "kinesis:ListShards", "kinesis:DescribeStream", "kinesis:GetRecords", "kinesis:GetShardIterator" ], "Resource": [ "arn:aws:kinesis:*:*:stream/blog_*" ] } ] } - Enter your Role ARN from the cross account role and press Save Integration.
Create Individual Collections
Create Coordinates Collection
Now that the integration is configured for Kinesis, you can create collections for the two data streams.
- Select the Collections tab.

- Click Create Collection.

- Select Kinesis.
- Select the integration you created in the previous section

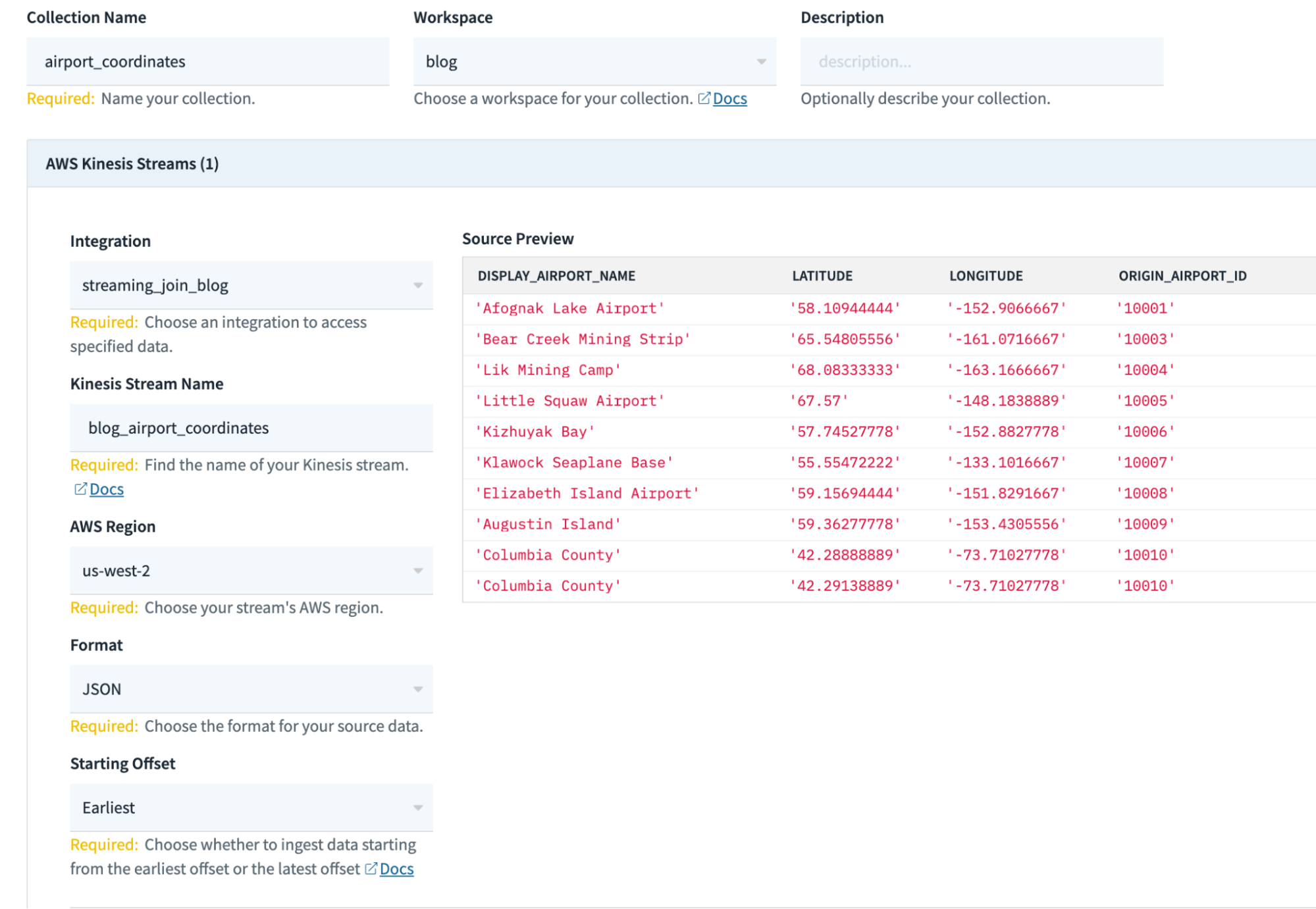
- On this screen, fill in the relevant information about your collection (some configurations may be different for you):
Collection Name: airport_coordinates
Workspace: commons
Kinesis Stream Name: blog_airport_coordinates
AWS region: us-west-2
Format: JSON
Starting Offset: Earliest
- Scroll down to the Configure ingest section and select Construct SQL rollup and/or transformation.

-
Paste the following SQL Transformation in the SQL Editor and press Apply.
a. The following SQL Transformation will cast the
LATITUDEandLONGITUDEvalues as floats instead of strings as they come into the collection and will create a new geopoint that can be used to query against using spatial data queries. The geo-index will give faster query results when using functions likeST_DISTANCE()than building a bounding box on latitude and longitude.
SELECT
i.*,
try_cast(i.LATITUDE as float) LATITUDE,
TRY_CAST(i.LONGITUDE as float) LONGITUDE,
ST_GEOGPOINT(
TRY_CAST(i.LONGITUDE as float),
TRY_CAST(i.LATITUDE as float)
) as coordinate
FROM
_input i
- Select the Create button to create the collection and start ingesting from Kinesis.
Create Airports Collection
Now that the integration is configured for Kinesis you can create collections for the two data streams.
- Select the Collections tab.
- Click Create Collection.
- Select Kinesis.
- Select the integration you created in the previous section.
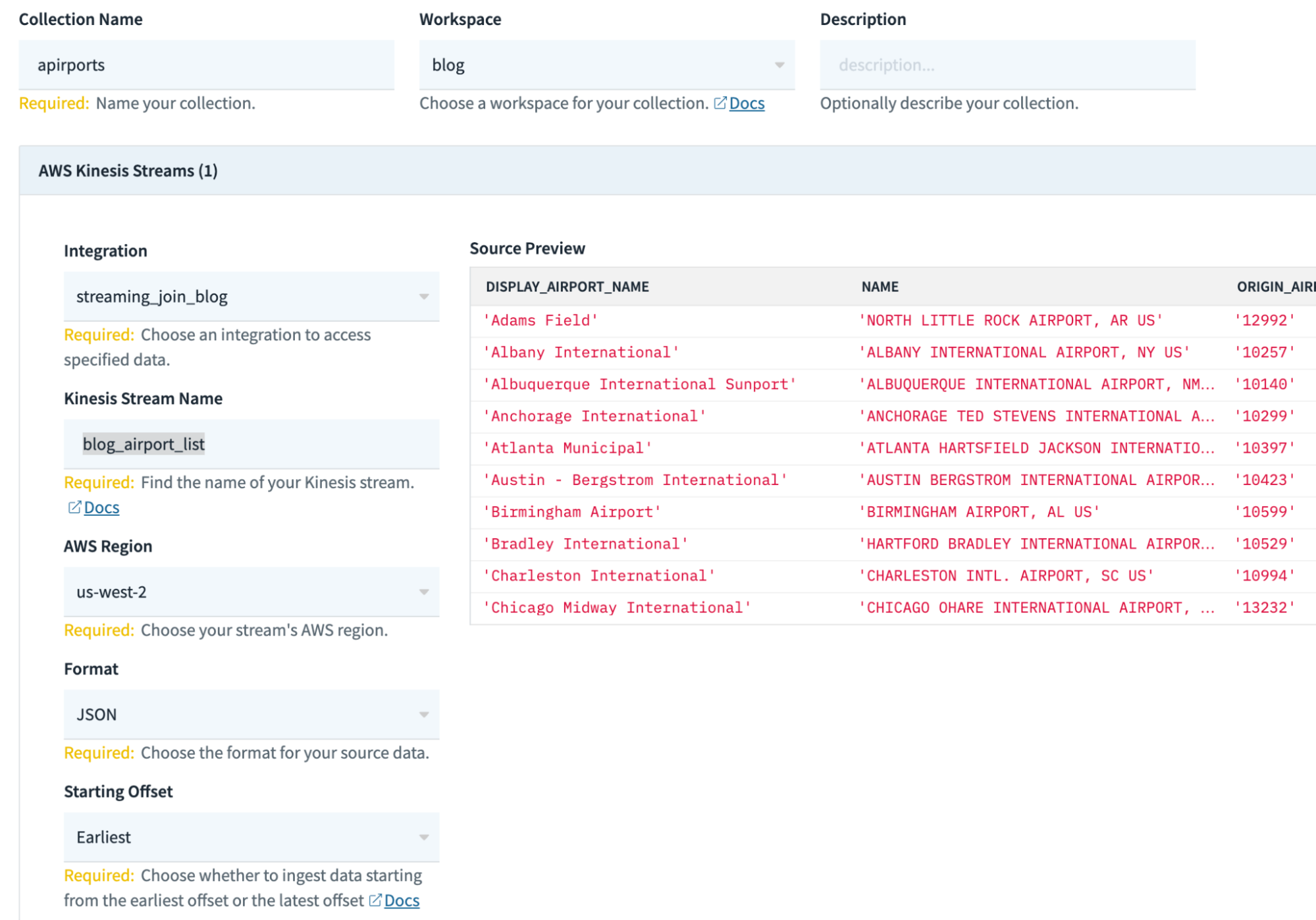
- On this screen, fill in the relevant information about your collection (some configurations may be different for you):
Collection Name: airports
Workspace: commons
Kinesis Stream Name: blog_airport_list
AWS region: us-west-2
Format: JSON
Starting Offset: Earliest
- This collection does not need a SQL Transformation.
- Select the Create button to create the collection and start ingesting from Kinesis.
Query Individual Collections
Now you need to query your collections with a JOIN.
- Select the Query Editor

- Paste the following query:
SELECT
ARBITRARY(a.coordinate) coordinate,
ARBITRARY(a.LATITUDE) LATITUDE,
ARBITRARY(a.LONGITUDE) LONGITUDE,
i.ORIGIN_AIRPORT_ID,
ARBITRARY(i.DISPLAY_AIRPORT_NAME) DISPLAY_AIRPORT_NAME,
ARBITRARY(i.NAME) NAME,
ARBITRARY(i.ORIGIN_CITY_NAME) ORIGIN_CITY_NAME
FROM
commons.airports i
left outer join commons.airport_coordinates a
on i.ORIGIN_AIRPORT_ID = a.ORIGIN_AIRPORT_ID
GROUP BY
i.ORIGIN_AIRPORT_ID
ORDER BY i.ORIGIN_AIRPORT_ID
- This query will join together the airports collection and the airport_coordinates collection and return the result of all the airports with their coordinates.
If you are wondering about the use of ARBITRARY in this query, it is used in this case because we know that there will be only one LONGITUDE (for example) for each ORIGIN_AIRPORT_ID. Because we are using GROUP BY, each attribute in the projection clause needs to either be the result of an aggregation function, or that attribute needs to be listed in the GROUP BY clause. ARBITRARY is just a handy aggregation function that returns the value that we expect every row to have. It's somewhat a personal choice as to which version is less confusing — using ARBITRARY or listing each row in the GROUP BY clause. The results will be the same in this case (remember, only one LONGITUDE per ORIGIN_AIRPORT_ID).
Create JOINed Collection
Now that you see how to create collections and JOIN them at query time, you need to JOIN your collections at ingestion time. This will allow you to combine your two collections into a single collection and enrich the airports collection data with coordinate information.
- Click Create Collection.
- Select Kinesis.
- Select the integration you created in the previous section.

- On this screen fill in the relevant information about your collection (some configurations may be different for you):
Collection Name: joined_airport
Workspace: commons
Kinesis Stream Name: blog_airport_coordinates
AWS region: us-west-2
Format: JSON
Starting Offset: Earliest
- Select the + Add Additional Source button.

- On this screen, fill in the relevant information about your collection (some configurations may be different for you):
Kinesis Stream Name: blog_airport_list
AWS region: us-west-2
Format: JSON
Starting Offset: Earliest
- You now have two data sources ready to stream into this collection.
- Now create the SQL Transformation with a rollup to
JOINthe two data sources and press Apply.
SELECT
ARBITRARY(TRY_CAST(i.LONGITUDE as float)) LATITUDE,
ARBITRARY(TRY_CAST(i.LATITUDE as float)) LONGITUDE,
ARBITRARY(
ST_GEOGPOINT(
TRY_CAST(i.LONGITUDE as float),
TRY_CAST(i.LATITUDE as float)
)
) as coordinate,
COALESCE(i.ORIGIN_AIRPORT_ID, i.OTHER_FIELD) as ORIGIN_AIRPORT_ID,
ARBITRARY(i.DISPLAY_AIRPORT_NAME) DISPLAY_AIRPORT_NAME,
ARBITRARY(i.NAME) NAME,
ARBITRARY(i.ORIGIN_CITY_NAME) ORIGIN_CITY_NAME
FROM
_input i
group by
ORIGIN_AIRPORT_ID
- Notice the key that you would normally
JOINon is used as theGROUP BYfield in the rollup. A rollup creates and maintains only a single row for every unique combination of the values of the attributes in theGROUP BYclause. In this case, since we are grouping on only one field, the rollup will have only one row perORIGIN_AIRPORT_ID. Each incoming data will get aggregated into the row for its correspondingORIGIN_AIRPORT_ID. Even though the data in each stream is different, they both have values forORIGIN_AIRPORT_ID, so this effectively combines the two data sources and creates distinct records based on eachORIGIN_AIRPORT_ID. - Also notice the projection:
COALESCE(i.ORIGIN_AIRPORT_ID,i.OTHER_FIELD) asORIGIN_AIRPORT_ID, a. This is used as an example in the event that yourJOINkeys are not named the same thing in each collection.i.OTHER_FIELDdoes not exist, butCOALESCEwith find the first non-NULL value and use that as the attribute toGROUPon orJOINon. - Notice the aggregation function
ARBITRARYis doing something more than usual in this case.ARBITRARYprefers a value over null. If, when we run this system, the first row of data that comes in for a givenORIGIN_AIRPORT_IDis from the Airports data set, it will not have an attribute forLONGITUDE. If we query that row before the Coordinates record comes in, we expect to get a null forLONGITUDE. Once a Coordinates record is processed for thatORIGIN_AIRPORT_IDwe want theLONGITUDEto always have that value. SinceARBITRARYprefers a value over a null, once we have a value forLONGITUDEit will always be returned for that row.
This pattern assumes that we won't ever get multiple LONGITUDE values for the same ORIGIN_AIRPORT_ID. If we did, we wouldn't be sure of which one would be returned from ARBITRARY. If multiple values are possible, there are other aggregation functions that will likely meet our needs, like, MIN() or MAX() if we want the largest or smallest value we have seen, or MIN_BY() or MAX_BY() if we wanted the earliest or latest values (based on some timestamp in the data). If we want to collect the multiple values that we might see of an attribute, we can use ARRAY_AGG(), MAP_AGG() and/or HMAP_AGG().
- Click Create Collection to create the collection and start ingesting from the two Kinesis data streams.
Query JOINed Collection
Now that you have created the JOINed collection, you can start to query it. You should notice that in the earlier query you were only able to find records that were defined in the airports collection and joined to the coordinates collection. Now we have a collection for all airports defined in either collection and the data that is available is stored in the documents. You can issue a query now against that collection to generate the same results as the previous query.
- Select the Query Editor.
- Paste the following query:
SELECT
i.coordinate,
i.LATITUDE,
i.LONGITUDE,
i.ORIGIN_AIRPORT_ID,
i.DISPLAY_AIRPORT_NAME,
i.NAME,
i.ORIGIN_CITY_NAME
FROM
commons.joined_airport i
where
NAME is not null
and coordinate is not null
ORDER BY i.ORIGIN_AIRPORT_ID
- Now you are returning the same result set that you were before without having to issue a
JOIN. You are also retrieving fewer data rows from storage, making the query likely much faster.The speed difference may not be noticeable on a small sample data set like this, but for enterprise applications, this technique can be the difference between a query that takes seconds to one that takes a few milliseconds to complete.
Cleanup
Now that you have created your three collections and queried them you can clean up your deployment by deleting your Kinesis shards, Rockset collections, integrations and AWS IAM role and policy.
Compare and Contrast
Using streaming joins is a great way to improve query performance by moving query time compute to ingestion time. This will reduce the frequency compute has to be consumed from every time the query is run to a single time during ingestion, resulting in the overall reduction of the compute necessary to achieve the same query latency and queries per second (QPS). But, streaming joins will not work in every scenario.
When using streaming joins, users are fixing the data model to a single JOIN and denormalization strategy. This means to utilize streaming joins effectively, users need to know a lot about their data, data model and access patterns before ingesting their data. There are strategies to handle this limitation, such as implementing multiple collections: one collection with streaming joins and other collections with raw data without the JOINs. This allows ad hoc queries to go against the raw collections and known queries to go against the JOINed collection.
Another limitation is that the GROUP BY works to simulate an INNER JOIN. If you are doing a LEFT or RIGHT JOIN you will not be able to do a streaming join and must do your JOIN at query time.
With all rollups and aggregations, it is possible you can lose granularity of your data. Streaming joins are a special kind of aggregation that may not affect data resolution. But, if there is an impact to resolution then the aggregated collection will not have the granularity that the raw collections would have. This will make queries faster, but less specific about individual data points. Understanding these tradeoffs will help users decide when to implement streaming joins and when to stick with query time JOINs.
Wrap-up
You have created collections and queried those collections. You have practiced writing queries that use JOINs and created collections that perform a JOIN at ingestion time. You can now build out new collections to satisfy use cases with extremely small query latency requirements that you are not able to achieve using query time JOINs. This knowledge can be used to solve real-time analytics use cases. This strategy does not apply only to Kinesis, but can be applied to any data sources that support rollups in Rockset. We invite you to find other use cases where this ingestion joining strategy can be used.
For further information or support, please contact Rockset Support, or visit our Rockset Community and our blog.
Rockset is the leading real-time analytics platform built for the cloud, delivering fast analytics on real-time data with surprising efficiency. Learn more at rockset.com.